
Faster RCNN基本结构和各部分原理详解
Faster RCNN的基本结构
一、网络总体结构
总体结构如图:

可分为以下四个模块↓
| 名称 | 作用 |
| 卷积层(conv) | 提取feature maps |
| 区域候选网络(RPN) |
|
| 兴趣域池化(RoI Pooling) | 收集PRN生成的proposals,并从feature maps中抠出对应的位置 |
| 分类和回归(Classification & Regression) | 利用proposals feature maps计算具体类别,在使用bounding box regression获得检测框的精确位置 |
二、分层详解
①卷积层
卷积层可以基于VGG或ResNet50,本文基于ResNet50构造卷积层。
卷积层合计13个Conv,13个ReLu,4个Pooling。
其中Conv的属性为:kernel_size=3, padding=1, stride=1
Pooling的属性为:kernel_size=2, padding=0, stride=2
Tips:卷积&池化公式
![]()
![]()
其被组织成两个模组:Conv Block和Identity Block
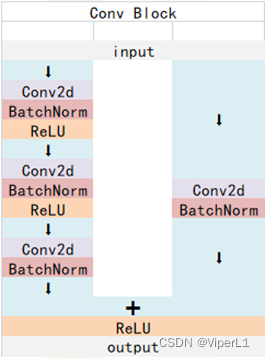

这两个模块的区别是:Conv Block的残差边有卷积,而Identity Block的残差边上没有卷积。拥有卷积边的Conv Block可以通过改变残差边来改变输出维度,而Identity Block的输入和输出维度是一致的。
其中使用Conv Block的会将图片的长宽/2(步长=2)
使用Identity Block的不会改变图片尺寸
作用:Conv Block用于改变网络维度,Identity Block用于串联以及加深网络深度。
一张MxN的图像经过卷积层后生成的feature map 为(M/16)x(N/16)
②RPN
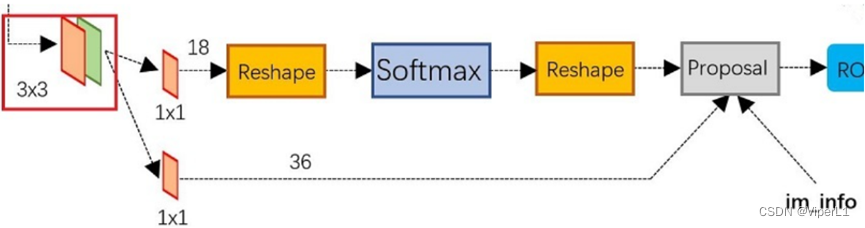
分为两个部分,
上面的线路通过softmax分类anchors获得正负两类(positive&negtive)
下面的线路通过reg layer计算anchors的bounding box regression偏移量获取proposal
两者在Proposal层汇合,本层负责将positive anchors和对应bounding box regression偏移量获取修正后的proposals(会剔除过小/超出边界的proposals)
其实执行到此处相当于完成了目标定位
②-1Cls layer-anchors
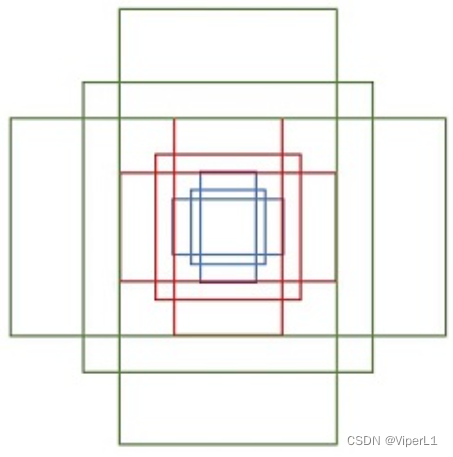
PRN的输入feature map为(M/16)x(N/16),在其上对每个像素点设置n个anchor(原作为9个)。这些anchor按照一定长宽比设置大小(原作为ratio[1:1,1:2,2:1])。
原图上的anchor的数量为(M/16)x(N/16)xn。但大部分会淘汰;此通道数为18=2x9->9对应着每个像素点上的九个先验框,2用于判断先验框是否包含物体。
②-3:reg layer

(M/16)x(N/16)x256的features通过一个1x1的kernel输出一组(M/16)x(N/16)x4k,为每个anchor的偏移量(此处输出的仅为偏移量,需要和原坐标进行叠加),通道数为9x2x4,4为先验框对于建议框的调整量。
4k是应为其偏移量有四个通道,如下
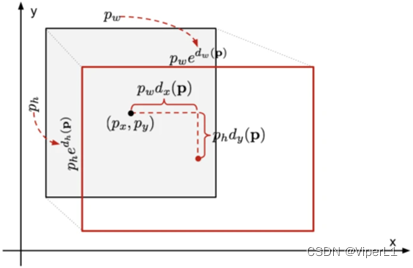
[tx,ty,tw,th],[xa,ya,wa,ha]为anchor的中心坐标和宽高,其计算公式如下
![]()
![]()
![]()
![]()
经过修正(p为原始坐标,d为PRN预测的坐标),anchor的坐标为
![]()
![]()
![]() )
)![]()
②-4:Proposal
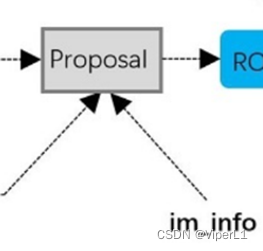
合计共三个输入
Cls生成的(M/16)x(N/16)x2k的向量
Reg生成的(M/16)x(N/16)x2k的向量
Im_info=[M,N,scale_factor]
其作用如下:
(1)利用reg层的偏移量,对所有的原始anchor进行修正
(2)利用cls层的scores,按positive socres由大到小排列所有anchors,取前topN(比如6000个)个anchors
(3)边界处理,把超出图像边界的positive anchor超出的部分收拢到图像边界处,防止后续RoI pooling时proposals超出边界。
(4)剔除尺寸非常小的positive anchor
(5)对剩余的positive anchors进行NMS(非极大抑制)
(6)最后输出一堆proposals左上角和右下角坐标值([x1,y1,x2,y2]对应原图MxN尺度)
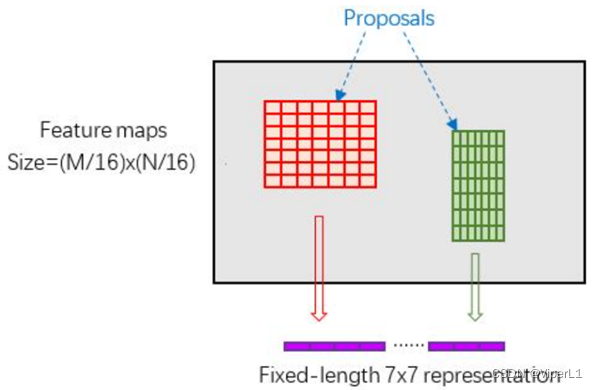
③RoI pooling
全连接层输入的feature尺寸必须相同,传统的做法一般是裁剪(crop)或
缩放(wrap),虽然可以resize图像,但是会出现信息缺失/破坏原始形状信息的问题。
RoI pooling的原理:
将每个proposal对应的feature map区域分为pooled_w x pooled_h的网格
对每个部分做max pooling,使每个proposal输出都是pooled_w x pooled_h
④Classification
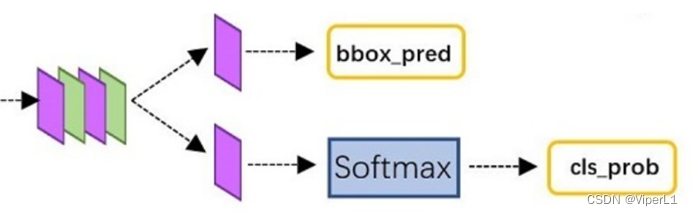
其与RPN的区别是RPN仅进行二分类(目标/背景),而classification还需要确定具体属于哪一类。
其主要功能有:
①通过全连接层和softmax对proposals进行分类(多分类)
②在此对proposals进行bunding box regression,获取更高精度的box

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)