From:From
一、CNN基础
1.1 理论基础
CNN的理论基础主要包括个方面:感受野、卷积计算、全零填充、批标准化、池化、舍弃。
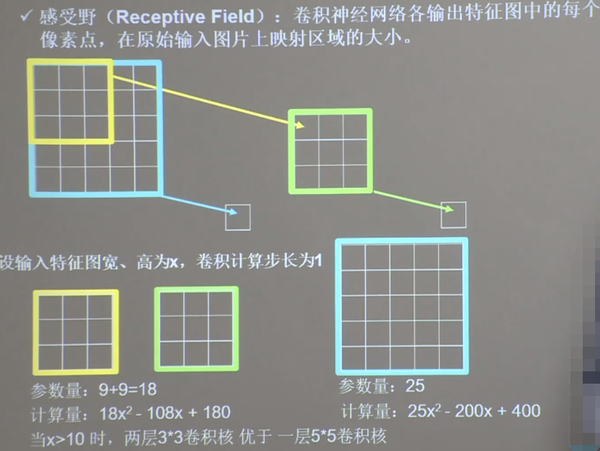
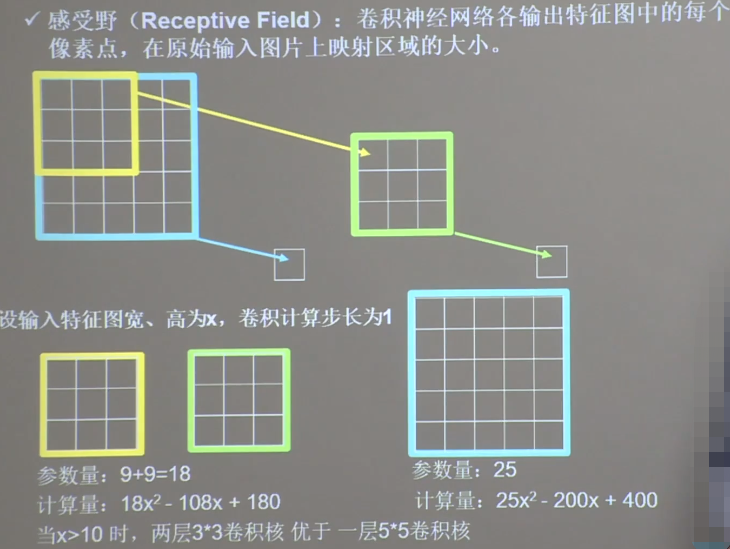
(1)感受野
感受野
神经网络在卷积计算中,常使用两层33卷积核。
(2)卷积计算
输入特征图的深度(channel数),决定了当前层卷积核的深度;当前卷积核的个数,决定了当前层输出特征图的深度。如果某层特征提取能力不足,可以在这一层多用几个卷积核提高这一层的特征提取能力。卷积就是利用立体卷积核实现参数共享。
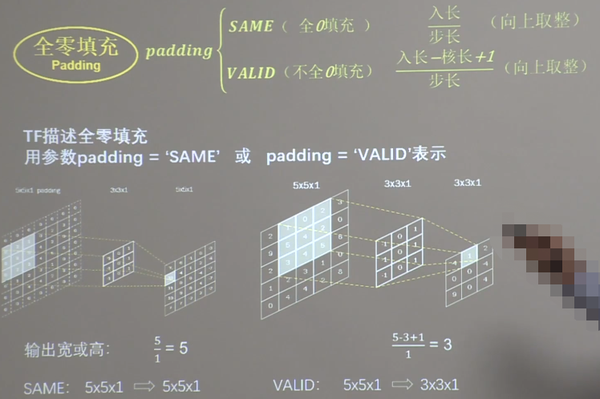
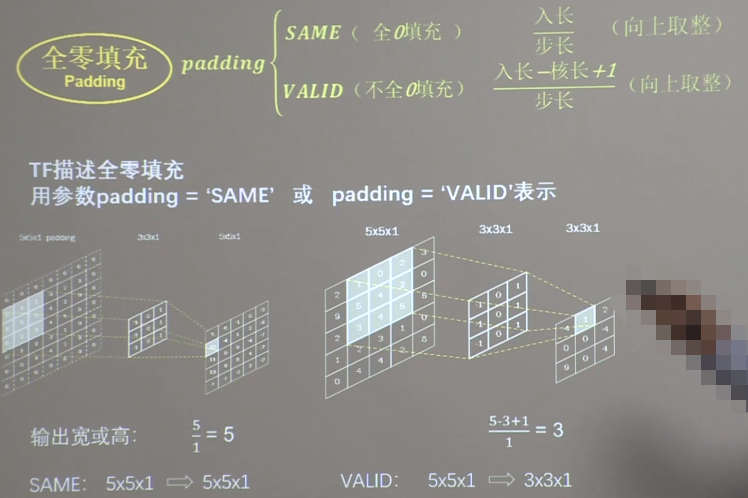
(3)全零填充
卷积计算保持输入特征图的尺寸不变,可以在输入特征图周围进行全零填充。
全零填充
不填充时,输出特征图边长=(输入特征图边长-卷积核长+1)/步长。
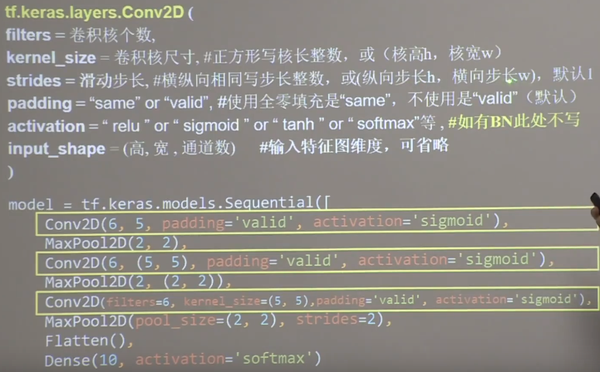
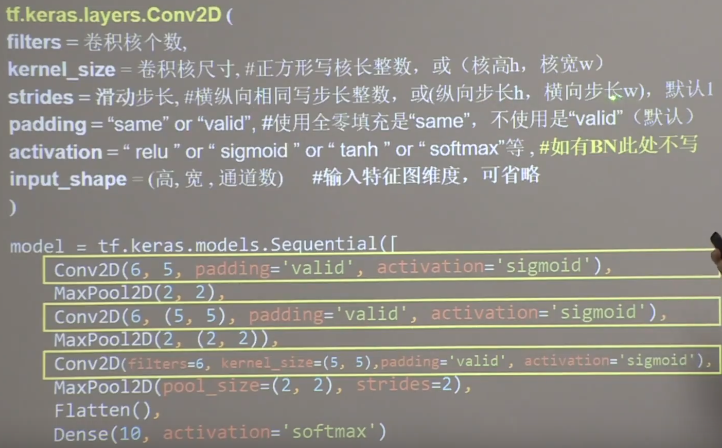
TF描述卷积层:
TF描述卷积层
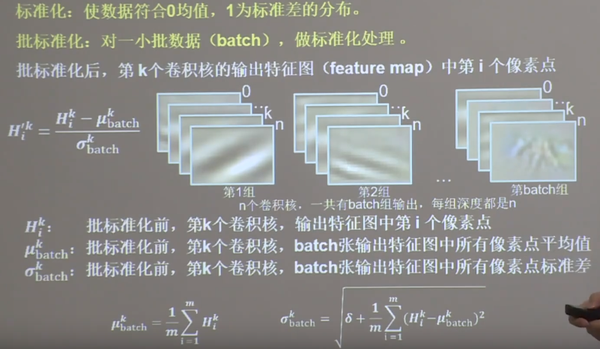
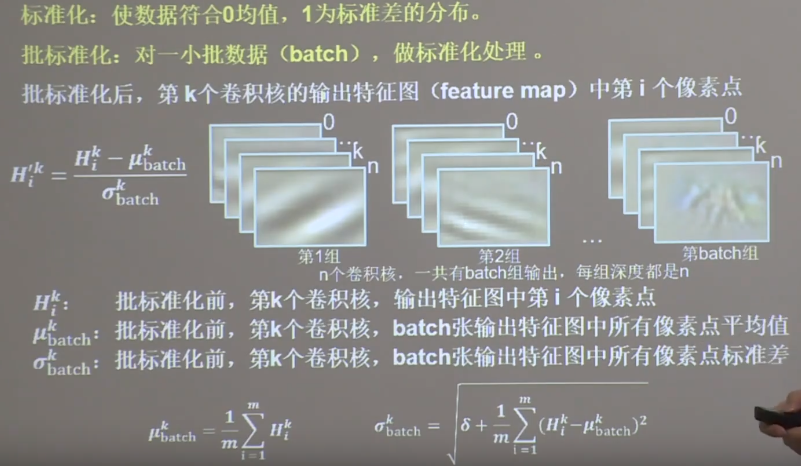
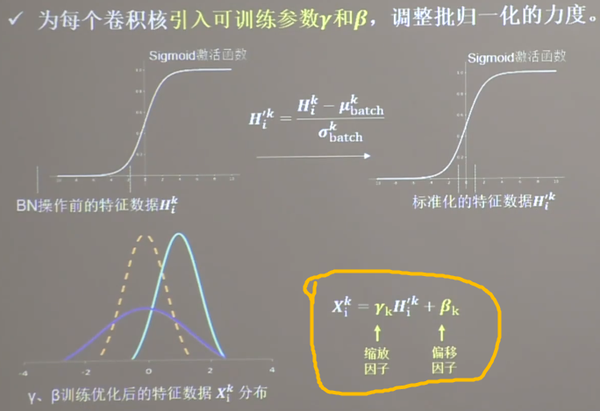
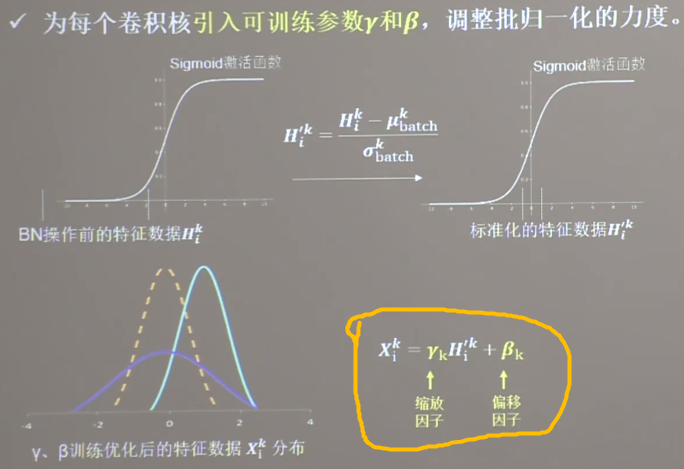
(4) 批标准化
批标准化
缩放偏移
缩放因子
γ \beta ,同模型其他参数一起进行训练。通过缩放因子和偏移因子,优化了特征数据分布的宽窄和偏移量,保证了网络的非线性表达力。
BN描述
(5) 池化
池化为了减少特征数据量,池化主要有两种:最大池化和平均池化。最大池化提取图片纹理,均值池化保留背景特征。
TF描述池化:
TF描述池化
(6) 舍弃
为了缓解过拟合,常把隐藏层的部分神经元按照一定比例从神经网络中临时舍弃。在使用神经网络时,再把神经元恢复到神经网络中。
卷积神经网络就是借助卷积核对输入特征进行特征提取,再把提取到的特征送入全连接网络进行识别预测。卷积就是特征提取器,主要包括卷积Convolutional、批标准化BN、激活Activation、池化Pooling和舍弃,即CBAPD,最后送入全连接网络。
1.2 base-CNN
利用Cifar10数据集,搭建base版本的CNN。C
ifar10数据集说明:
3232像素点的十分类彩色图片和标签,其中5万张用于训练,1万张用于测试。
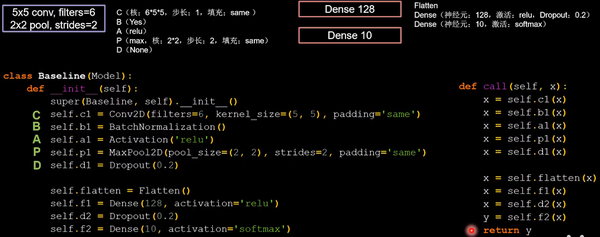
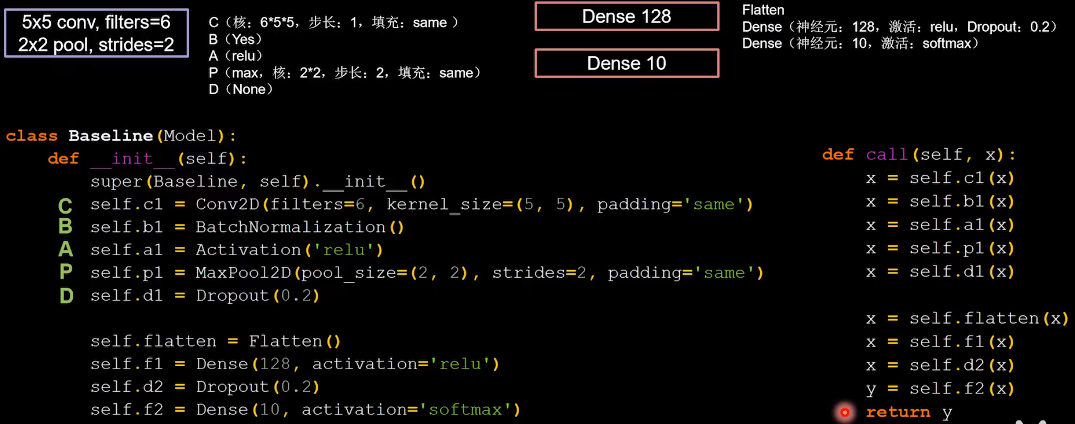
CNN搭建示例:6个55的卷积核,步长为1;2个2 2的池化核,步长为2。利用CBAPD搭建网络:
网络结构搭建
整体代码如下,将作为下面介绍五种经典CNN的base版本,只替换对应的网络结构即可。
import tensorflow as tf
np.set_printoptions(threshold=np.inf)
cifar10 = tf.keras.datasets.cifar10
class Baseline(Model):init (self):init ()
self.flatten = Flatten()
self.f1 = Dense(128, activation='relu')
self.d2 = Dropout(0.2)
self.f2 = Dense(10, activation='softmax')
def call(self, x):
x = self.c1(x)
x = self.b1(x)
x = self.a1(x)
x = self.p1(x)
x = self.d1(x)
x = self.flatten(x)
x = self.f1(x)
x = self.d2(x)
y = self.f2(x)
return y
model = Baseline()
model.compile(optimizer=‘adam’,
checkpoint_save_path = “./checkpoint/Baseline.ckpt”
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1,
file = open(‘./weights.txt’, ‘w’)
##################### show ######################
acc = history.history[‘sparse_categorical_accuracy’]
plt.subplot(1, 2, 1)
plt.subplot(1, 2, 2)
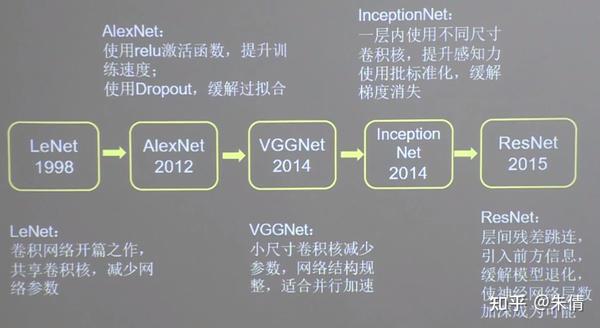
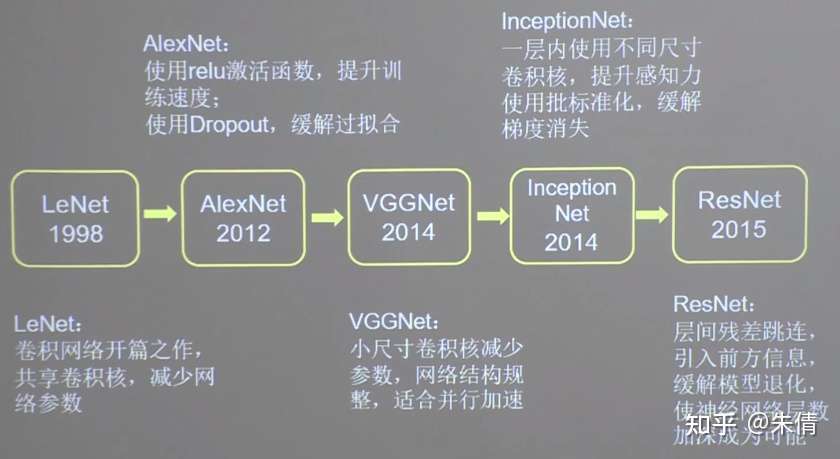
二、五种经典CNN
利用六步法实现LeNet、AlexNet、VGGNet、InceptionNet和ResNet。
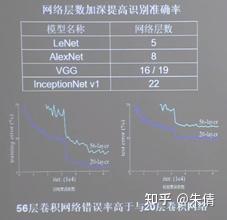
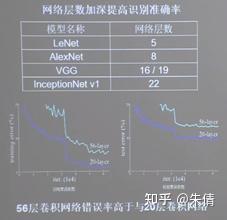
统计网络层数时,一般只统计卷积计算层和全连接层。
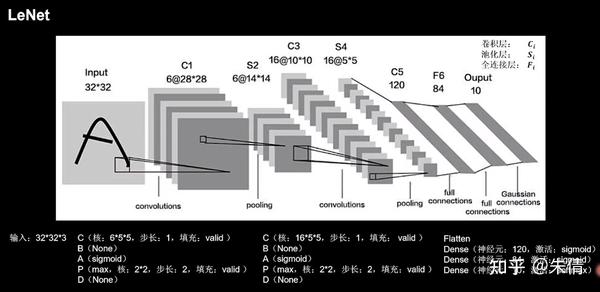
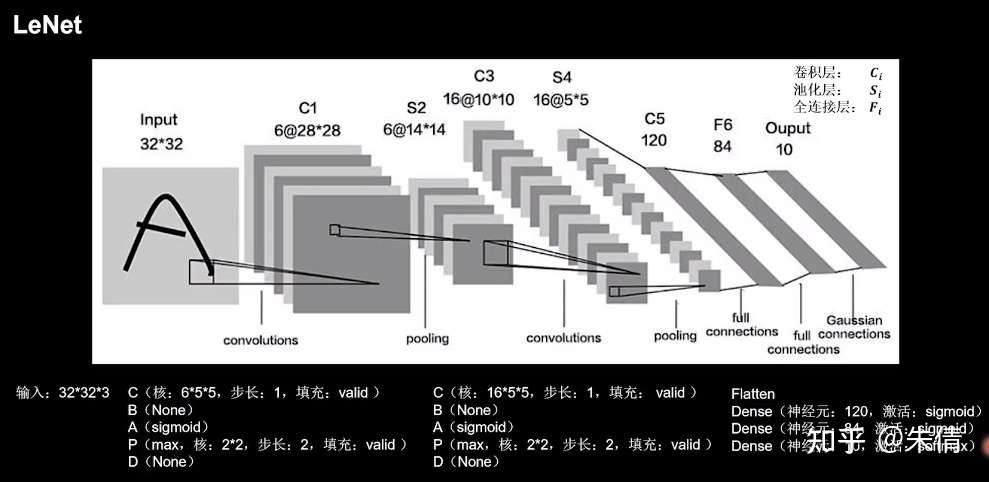
2.1 LeNet
LeNet由Yann LeCnn于1998年提出,卷积网络开篇之作。
LeNet网络结构:
LeNet网络结构
LeNet提出时,没有BN操作,sigmoid是主流激活函数。
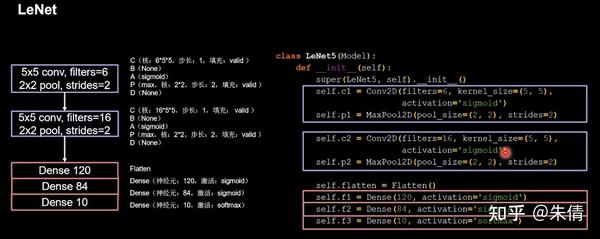
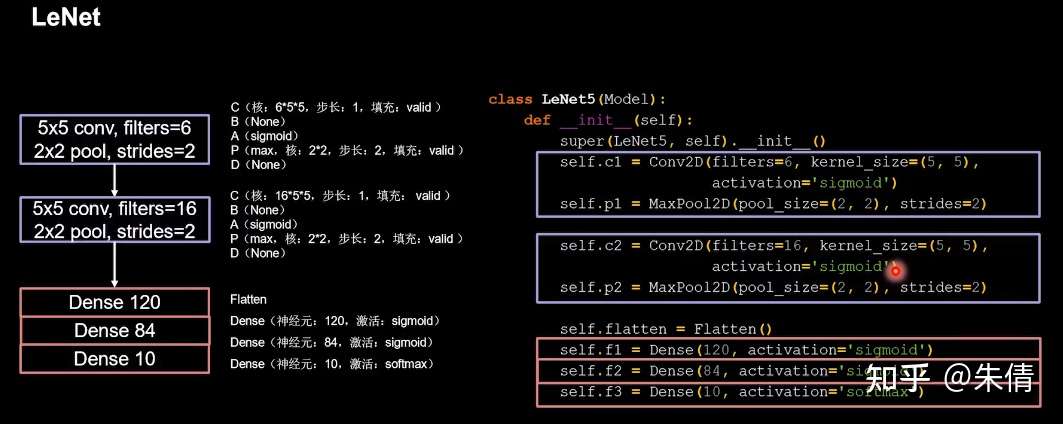
CBAPD写出来:
LeNet
将base版本CNN中model部分替换成LeNet网络即可。
class LeNet5(Model):init (self):init () self.c2 = Conv2D(filters=16, kernel_size=(5, 5),
activation='sigmoid')
self.p2 = MaxPool2D(pool_size=(2, 2), strides=2)
self.flatten = Flatten()
self.f1 = Dense(120, activation='sigmoid')
self.f2 = Dense(84, activation='sigmoid')
self.f3 = Dense(10, activation='softmax')
def call(self, x):
x = self.c1(x)
x = self.p1(x)
x = self.c2(x)
x = self.p2(x)
x = self.flatten(x)
x = self.f1(x)
x = self.f2(x)
y = self.f3(x)
return y
model = LeNet5()
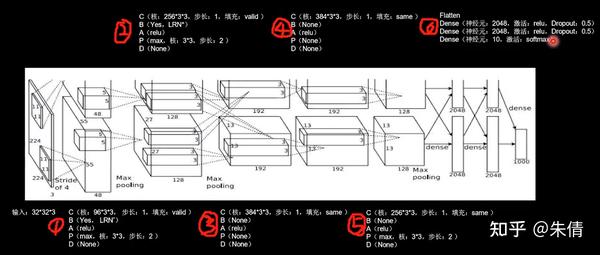
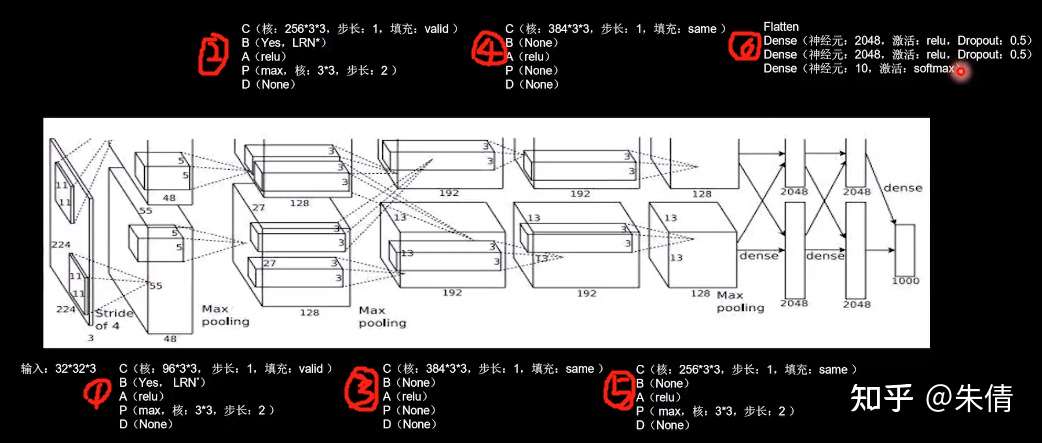
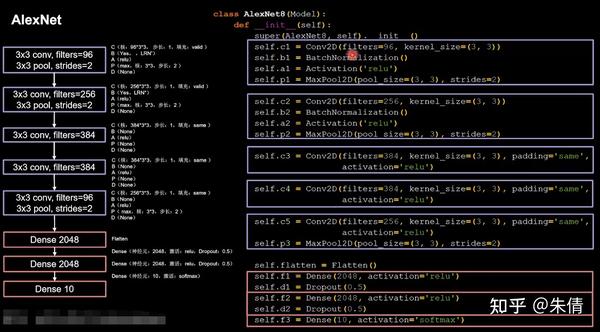
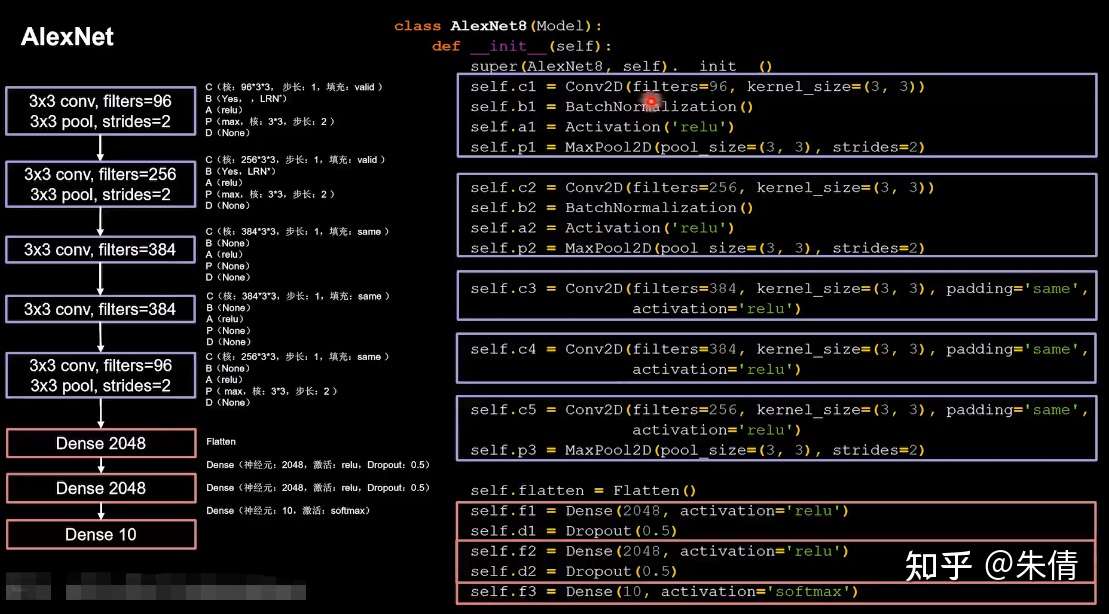
2.1 AlexNet
AlexNet网络诞生于2012年,当年ImageNet竞赛的冠军,Top5错误率为16.4%。
AlexNet使用relu激活函数,提高了训练速度;使用dropout缓解了过拟合。
AlexNet网络结构:
AlexNet网络结构
原论文中使用LRN局部响应标准化,它的作用与BN相似,代码实现选择了当前主流的BN操作实现特征标准化。
CBAPD写出来:
AlexNet
将base版本CNN中model部分替换成AlexNet网络即可。
class AlexNet8(Model):init (self):init () self.c2 = Conv2D(filters=256, kernel_size=(3, 3))
self.b2 = BatchNormalization()
self.a2 = Activation('relu')
self.p2 = MaxPool2D(pool_size=(3, 3), strides=2)
self.c3 = Conv2D(filters=384, kernel_size=(3, 3), padding='same',
activation='relu')
self.c4 = Conv2D(filters=384, kernel_size=(3, 3), padding='same',
activation='relu')
self.c5 = Conv2D(filters=256, kernel_size=(3, 3), padding='same',
activation='relu')
self.p3 = MaxPool2D(pool_size=(3, 3), strides=2)
self.flatten = Flatten()
self.f1 = Dense(2048, activation='relu')
self.d1 = Dropout(0.5)
self.f2 = Dense(2048, activation='relu')
self.d2 = Dropout(0.5)
self.f3 = Dense(10, activation='softmax')
def call(self, x):
x = self.c1(x)
x = self.b1(x)
x = self.a1(x)
x = self.p1(x)
x = self.c2(x)
x = self.b2(x)
x = self.a2(x)
x = self.p2(x)
x = self.c3(x)
x = self.c4(x)
x = self.c5(x)
x = self.p3(x)
x = self.flatten(x)
x = self.f1(x)
x = self.d1(x)
x = self.f2(x)
x = self.d2(x)
y = self.f3(x)
return y
model = AlexNet8()
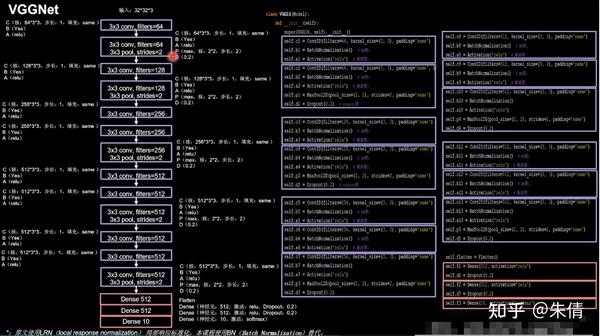
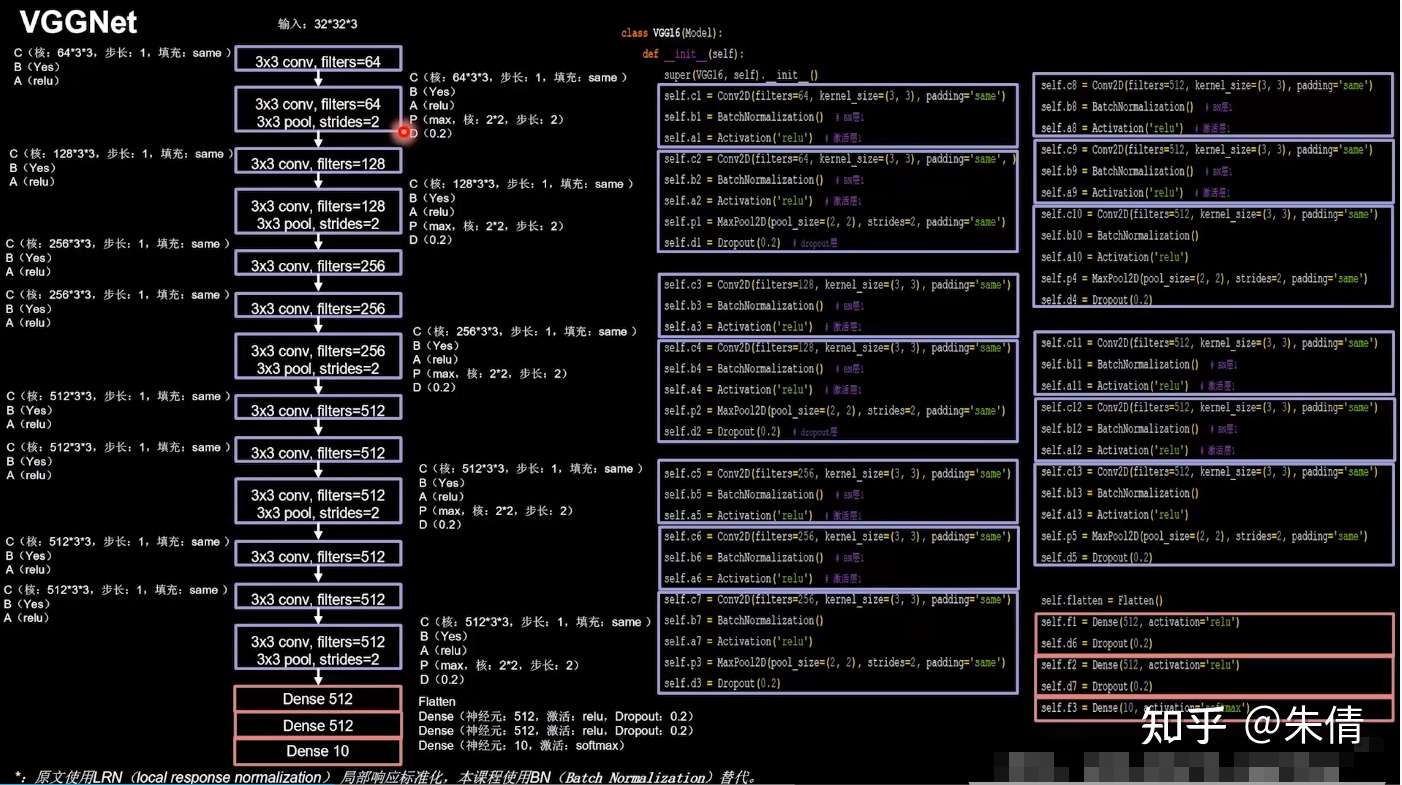
2.3 VGGNet
VGGNet诞生于2014年,当年ImageNet竞赛的亚军,Top5错误率减小到7.3%。
VGGNet使用小尺寸卷积核,在减少参数的同时,提高了识别准确率。VGGNet结构规整,非常适合硬件加速。
VGGNet网络结构:
VGGNet
VGGNet结构:2次CBA、CBAPD,3次CBA、CBA、CBAPD,最后3层全连接。
设计VGGNet网络时,卷积核的个数从64到128,到256,到512,逐渐增加。网络越靠后,特征图尺寸越小,通过增加卷积核个数,增加特征图深度,保持了信息的承载能力。
将base版本CNN中model部分替换成VGGNet网络即可,以16层为例。
class VGG16(Model):init (self):init () self.c3 = Conv2D(filters=128, kernel_size=(3, 3), padding='same')
self.b3 = BatchNormalization() # BN层1
self.a3 = Activation('relu') # 激活层1
self.c4 = Conv2D(filters=128, kernel_size=(3, 3), padding='same')
self.b4 = BatchNormalization() # BN层1
self.a4 = Activation('relu') # 激活层1
self.p2 = MaxPool2D(pool_size=(2, 2), strides=2, padding='same')
self.d2 = Dropout(0.2) # dropout层
self.c5 = Conv2D(filters=256, kernel_size=(3, 3), padding='same')
self.b5 = BatchNormalization() # BN层1
self.a5 = Activation('relu') # 激活层1
self.c6 = Conv2D(filters=256, kernel_size=(3, 3), padding='same')
self.b6 = BatchNormalization() # BN层1
self.a6 = Activation('relu') # 激活层1
self.c7 = Conv2D(filters=256, kernel_size=(3, 3), padding='same')
self.b7 = BatchNormalization()
self.a7 = Activation('relu')
self.p3 = MaxPool2D(pool_size=(2, 2), strides=2, padding='same')
self.d3 = Dropout(0.2)
self.c8 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b8 = BatchNormalization() # BN层1
self.a8 = Activation('relu') # 激活层1
self.c9 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b9 = BatchNormalization() # BN层1
self.a9 = Activation('relu') # 激活层1
self.c10 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b10 = BatchNormalization()
self.a10 = Activation('relu')
self.p4 = MaxPool2D(pool_size=(2, 2), strides=2, padding='same')
self.d4 = Dropout(0.2)
self.c11 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b11 = BatchNormalization() # BN层1
self.a11 = Activation('relu') # 激活层1
self.c12 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b12 = BatchNormalization() # BN层1
self.a12 = Activation('relu') # 激活层1
self.c13 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b13 = BatchNormalization()
self.a13 = Activation('relu')
self.p5 = MaxPool2D(pool_size=(2, 2), strides=2, padding='same')
self.d5 = Dropout(0.2)
self.flatten = Flatten()
self.f1 = Dense(512, activation='relu')
self.d6 = Dropout(0.2)
self.f2 = Dense(512, activation='relu')
self.d7 = Dropout(0.2)
self.f3 = Dense(10, activation='softmax')
def call(self, x):
x = self.c1(x)
x = self.b1(x)
x = self.a1(x)
x = self.c2(x)
x = self.b2(x)
x = self.a2(x)
x = self.p1(x)
x = self.d1(x)
x = self.c3(x)
x = self.b3(x)
x = self.a3(x)
x = self.c4(x)
x = self.b4(x)
x = self.a4(x)
x = self.p2(x)
x = self.d2(x)
x = self.c5(x)
x = self.b5(x)
x = self.a5(x)
x = self.c6(x)
x = self.b6(x)
x = self.a6(x)
x = self.c7(x)
x = self.b7(x)
x = self.a7(x)
x = self.p3(x)
x = self.d3(x)
x = self.c8(x)
x = self.b8(x)
x = self.a8(x)
x = self.c9(x)
x = self.b9(x)
x = self.a9(x)
x = self.c10(x)
x = self.b10(x)
x = self.a10(x)
x = self.p4(x)
x = self.d4(x)
x = self.c11(x)
x = self.b11(x)
x = self.a11(x)
x = self.c12(x)
x = self.b12(x)
x = self.a12(x)
x = self.c13(x)
x = self.b13(x)
x = self.a13(x)
x = self.p5(x)
x = self.d5(x)
x = self.flatten(x)
x = self.f1(x)
x = self.d6(x)
x = self.f2(x)
x = self.d7(x)
y = self.f3(x)
return y
model = VGG16()
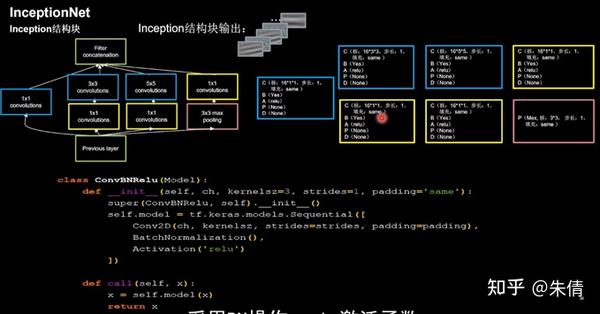
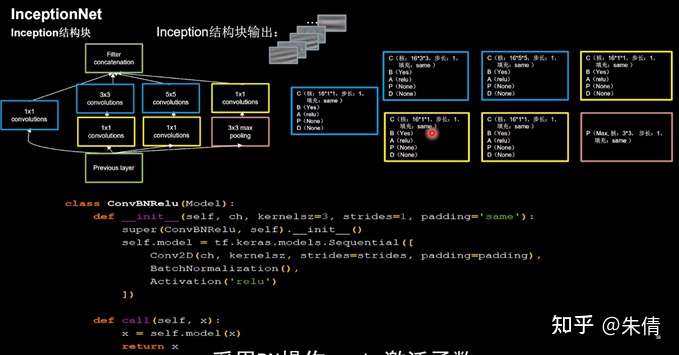
2.4 InceptionNet
InceptionNet诞生于2014年,当年ImageNet竞赛冠军,Top5错误率为6.67%。
InceptionNet在同一层网络内使用不同尺寸的卷积核,可以提取不同尺寸的特征,提升了模型感知力;使用批标准化,缓解了梯度消失。
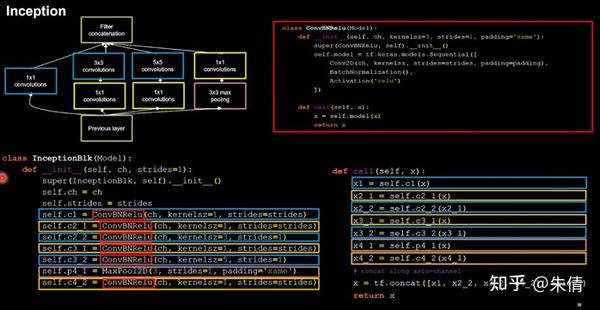
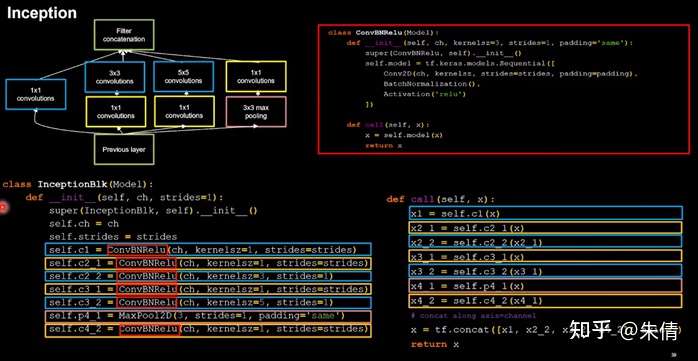
InceptionNet的核心是它的基本单元Inception结构块,
通过设定少于输入特征图深度的11卷积核个数,减少了输出特征图深度,起到了降维的作用,减少了参数量和计算量。
Inception结构块包含4个分支:①分别经过11卷积核输出到卷积连接器;②经过11卷积核配合3 3卷积核输出到卷积连接器;③经过11卷积核配合5 5卷积核输出到卷积连接器;④经过33最大池化核配合1 1卷积核输出到卷积连接器。送到卷积连接器的特征数据尺寸相同,卷积连接器会把收到的这四路特征数据按深度方向拼接,形成Inception结构块的输出。用CBAPD对应颜色进行编码。
Inception结构块
由于Inception结构块中的卷积操作均采用了CBA操作,先卷积,再BN,再采用relu激活函数,所以将其打包成新的类ConvBNRelu,在此基础上实现Inception块。
Inception结构块
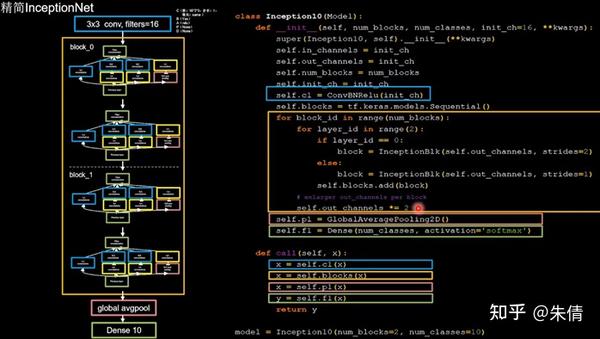
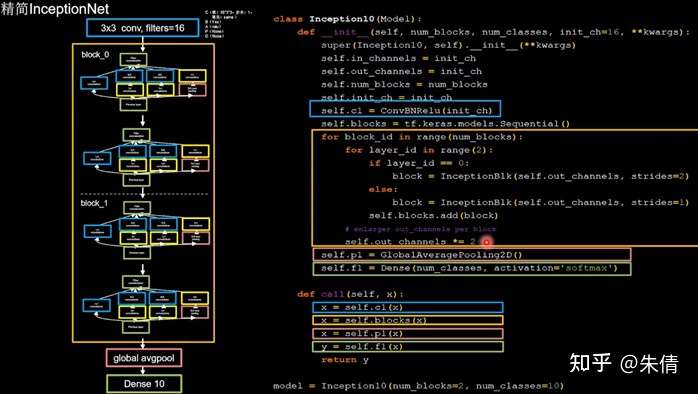
搭建精简版本InceptionNet:
精简InceptionNet
4个Inception结构块顺序相连,每2个Inception结构块组成一个block,每个block中的第一个Inception结构块的卷积步长是2,第二个Inception结构块的卷积步长是1,这使得第一个Inception输出特征图尺寸减半,因此把输出特征图加深,尽可能保证特征提取过程中信息承载量一致。block_1通道数为16,通过4个分支,变成416=64,block_2的通道数是block_1通道数的两倍,在经过4个分支,即16 2*4=128。这128个通道数据被送入平均池化,然后送入10个分类的全连接。
将base版本CNN中model部分替换成InceptionNet网络即可。
class ConvBNRelu(Model):init (self, ch, kernelsz=3, strides=1, padding=‘same’):init ()def call(self, x):
x = self.model(x, training=False) #在training=False时,BN通过整个训练集计算均值、方差去做批归一化,training=True时,通过当前batch的均值、方差去做批归一化。推理时 training=False效果好
return x
class InceptionBlk(Model):init (self, ch, strides=1):init ()
def call(self, x):
x1 = self.c1(x)
x2_1 = self.c2_1(x)
x2_2 = self.c2_2(x2_1)
x3_1 = self.c3_1(x)
x3_2 = self.c3_2(x3_1)
x4_1 = self.p4_1(x)
x4_2 = self.c4_2(x4_1)
# concat along axis=channel
x = tf.concat([x1, x2_2, x3_2, x4_2], axis=3)
return x
class Inception10(Model):init (self, num_blocks, num_classes, init_ch=16, **kwargs):init (**kwargs)
def call(self, x):
x = self.c1(x)
x = self.blocks(x)
x = self.p1(x)
y = self.f1(x)
return y
model = Inception10(num_blocks=2, num_classes=10)
由于当前训练数据量较大,将history中的batch_size调整为1024,一次喂入神经网络的数据量多一些,以充分发挥显卡的性能,提高训练速度。你也可以根据电脑的性能,调整batch_size的数值,一般让显卡达到70-80%的负荷比较合理。
2.5 ResNet
ResNet诞生于2015年,当年ImageNet竞赛冠军,Top错误率为3.57%。
ResNet提出了层间残差跳连,引入了前方信息,缓解梯度消失,使神经网络层数增加成为可能。
ResNet的作者何凯明在cifar10数据集上面做了实验,发现56层卷积网络的错误率要高于20层卷积网络的错误率。他认为,单纯堆叠神经网络的层数,会使神经网络模型退化,以至于后边的特征丢失了前边特征的原本模样。
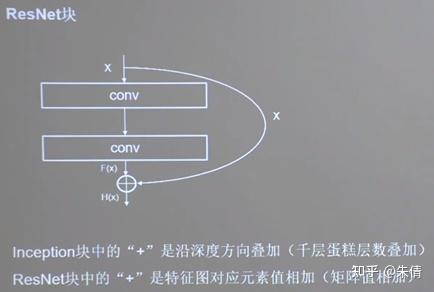
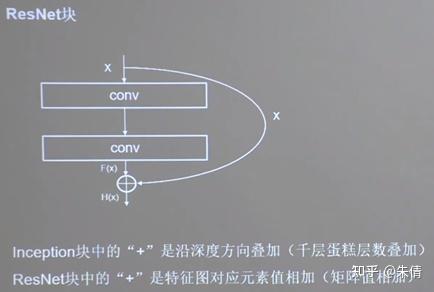
于是,他用一根跳连线将前边的特征直接接到了后边,使这里的输出H(x)包含了堆叠卷积的非线性输出F(x),和跳过这两层堆叠卷积直接连接过来的恒等映射x,让他们的对应元素相加。这一操作,有效缓解了神经网络模型堆叠导致的退化,使得神经网络可以向着更深层级发展。
ResNet块中的“+”与Inception块中的“+”是不同的。ResNet块中的“+”是沿深度方向叠加,而Inception块中的“+”是两路特征图对应元素值相加。
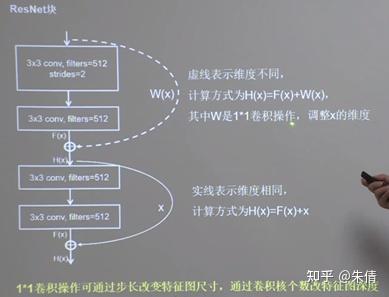
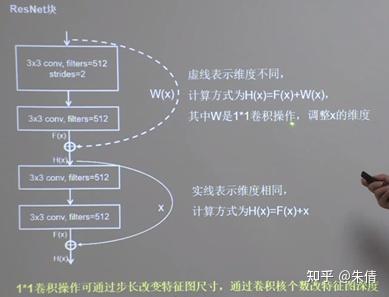
ResNet块
ResNet块中有两种情况:一种情况用图中的实线表示,两层堆叠卷积,没有改变特征图的维度,也就是他们特征图的高、宽和深度都相同,可以直接让F(x)与x直接相加; 另一路用虚线表示,两层堆叠卷积,改变了特征图的维度,需要借助1*1的卷积来调整x的维度,使W(x)与F(x)的维度一致。
两种情况
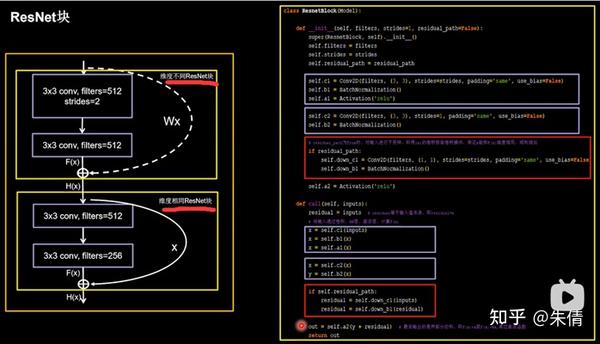
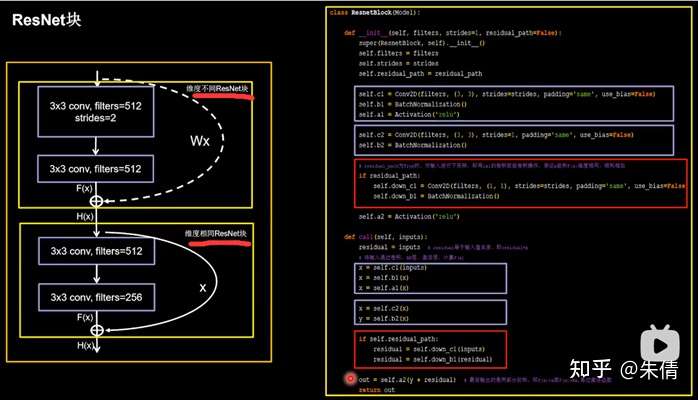
ResNet块中的两种情况,如果维度不相同,则执行红色框里面的代码。
ResnetBlock类
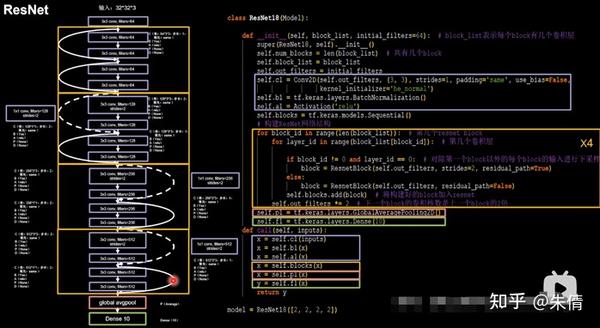
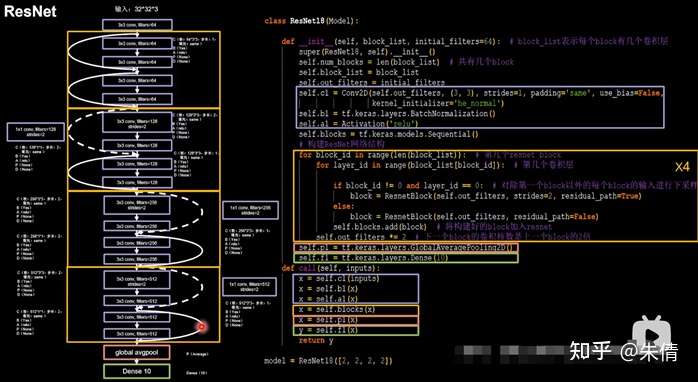
利用ResNet块,搭建ResNet网络。第一层是卷积输入,然后是8个ResNet块(每个ResNet块是2层卷积),经过均值池化,最后一层全连接。其中,第1个ResNet块是两条实线跳连,后面3个ResNet块是先虚线跳连,后实线跳连。
ResNet
为加速收敛,可将history中的batch_size调整为128。
将base版本CNN中model部分替换成ResNet网络即可。
class ResnetBlock ( Model ): def init ( self , filters , strides = 1 , residual_path = False ): super ( ResnetBlock , self ) . init () self . filters = filters self . strides = strides self . residual_path = residual_path
<span class="bp">self</span><span class="o">.</span><span class="n">c1</span> <span class="o">=</span> <span class="n">Conv2D</span><span class="p">(</span><span class="n">filters</span><span class="p">,</span> <span class="p">(</span><span class="mi">3</span><span class="p">,</span> <span class="mi">3</span><span class="p">),</span> <span class="n">strides</span><span class="o">=</span><span class="n">strides</span><span class="p">,</span> <span class="n">padding</span><span class="o">=</span><span class="s1">'same'</span><span class="p">,</span> <span class="n">use_bias</span><span class="o">=</span><span class="kc">False</span><span class="p">)</span>
<span class="bp">self</span><span class="o">.</span><span class="n">b1</span> <span class="o">=</span> <span class="n">BatchNormalization</span><span class="p">()</span>
<span class="bp">self</span><span class="o">.</span><span class="n">a1</span> <span class="o">=</span> <span class="n">Activation</span><span class="p">(</span><span class="s1">'relu'</span><span class="p">)</span>
<span class="bp">self</span><span class="o">.</span><span class="n">c2</span> <span class="o">=</span> <span class="n">Conv2D</span><span class="p">(</span><span class="n">filters</span><span class="p">,</span> <span class="p">(</span><span class="mi">3</span><span class="p">,</span> <span class="mi">3</span><span class="p">),</span> <span class="n">strides</span><span class="o">=</span><span class="mi">1</span><span class="p">,</span> <span class="n">padding</span><span class="o">=</span><span class="s1">'same'</span><span class="p">,</span> <span class="n">use_bias</span><span class="o">=</span><span class="kc">False</span><span class="p">)</span>
<span class="bp">self</span><span class="o">.</span><span class="n">b2</span> <span class="o">=</span> <span class="n">BatchNormalization</span><span class="p">()</span>
<span class="c1"># residual_path为True时,对输入进行下采样,即用1x1的卷积核做卷积操作,保证x能和F(x)维度相同,顺利相加</span>
<span class="k">if</span> <span class="n">residual_path</span><span class="p">:</span>
<span class="bp">self</span><span class="o">.</span><span class="n">down_c1</span> <span class="o">=</span> <span class="n">Conv2D</span><span class="p">(</span><span class="n">filters</span><span class="p">,</span> <span class="p">(</span><span class="mi">1</span><span class="p">,</span> <span class="mi">1</span><span class="p">),</span> <span class="n">strides</span><span class="o">=</span><span class="n">strides</span><span class="p">,</span> <span class="n">padding</span><span class="o">=</span><span class="s1">'same'</span><span class="p">,</span> <span class="n">use_bias</span><span class="o">=</span><span class="kc">False</span><span class="p">)</span>
<span class="bp">self</span><span class="o">.</span><span class="n">down_b1</span> <span class="o">=</span> <span class="n">BatchNormalization</span><span class="p">()</span>
<span class="bp">self</span><span class="o">.</span><span class="n">a2</span> <span class="o">=</span> <span class="n">Activation</span><span class="p">(</span><span class="s1">'relu'</span><span class="p">)</span>
<span class="k">def</span> <span class="nf">call</span><span class="p">(</span><span class="bp">self</span><span class="p">,</span> <span class="n">inputs</span><span class="p">):</span>
<span class="n">residual</span> <span class="o">=</span> <span class="n">inputs</span> <span class="c1"># residual等于输入值本身,即residual=x</span>
<span class="c1"># 将输入通过卷积、BN层、激活层,计算F(x)</span>
<span class="n">x</span> <span class="o">=</span> <span class="bp">self</span><span class="o">.</span><span class="n">c1</span><span class="p">(</span><span class="n">inputs</span><span class="p">)</span>
<span class="n">x</span> <span class="o">=</span> <span class="bp">self</span><span class="o">.</span><span class="n">b1</span><span class="p">(</span><span class="n">x</span><span class="p">)</span>
<span class="n">x</span> <span class="o">=</span> <span class="bp">self</span><span class="o">.</span><span class="n">a1</span><span class="p">(</span><span class="n">x</span><span class="p">)</span>
<span class="n">x</span> <span class="o">=</span> <span class="bp">self</span><span class="o">.</span><span class="n">c2</span><span class="p">(</span><span class="n">x</span><span class="p">)</span>
<span class="n">y</span> <span class="o">=</span> <span class="bp">self</span><span class="o">.</span><span class="n">b2</span><span class="p">(</span><span class="n">x</span><span class="p">)</span>
<span class="k">if</span> <span class="bp">self</span><span class="o">.</span><span class="n">residual_path</span><span class="p">:</span>
<span class="n">residual</span> <span class="o">=</span> <span class="bp">self</span><span class="o">.</span><span class="n">down_c1</span><span class="p">(</span><span class="n">inputs</span><span class="p">)</span>
<span class="n">residual</span> <span class="o">=</span> <span class="bp">self</span><span class="o">.</span><span class="n">down_b1</span><span class="p">(</span><span class="n">residual</span><span class="p">)</span>
<span class="n">out</span> <span class="o">=</span> <span class="bp">self</span><span class="o">.</span><span class="n">a2</span><span class="p">(</span><span class="n">y</span> <span class="o">+</span> <span class="n">residual</span><span class="p">)</span> <span class="c1"># 最后输出的是两部分的和,即F(x)+x或F(x)+Wx,再过激活函数</span>
<span class="k">return</span> <span class="n">out</span>
class ResNet18 ( Model ):
<span class="k">def</span> <span class="nf">__init__</span><span class="p">(</span><span class="bp">self</span><span class="p">,</span> <span class="n">block_list</span><span class="p">,</span> <span class="n">initial_filters</span><span class="o">=</span><span class="mi">64</span><span class="p">):</span> <span class="c1"># block_list表示每个block有几个卷积层</span>
<span class="nb">super</span><span class="p">(</span><span class="n">ResNet18</span><span class="p">,</span> <span class="bp">self</span><span class="p">)</span><span class="o">.</span><span class="fm">__init__</span><span class="p">()</span>
<span class="bp">self</span><span class="o">.</span><span class="n">num_blocks</span> <span class="o">=</span> <span class="nb">len</span><span class="p">(</span><span class="n">block_list</span><span class="p">)</span> <span class="c1"># 共有几个block</span>
<span class="bp">self</span><span class="o">.</span><span class="n">block_list</span> <span class="o">=</span> <span class="n">block_list</span>
<span class="bp">self</span><span class="o">.</span><span class="n">out_filters</span> <span class="o">=</span> <span class="n">initial_filters</span>
<span class="bp">self</span><span class="o">.</span><span class="n">c1</span> <span class="o">=</span> <span class="n">Conv2D</span><span class="p">(</span><span class="bp">self</span><span class="o">.</span><span class="n">out_filters</span><span class="p">,</span> <span class="p">(</span><span class="mi">3</span><span class="p">,</span> <span class="mi">3</span><span class="p">),</span> <span class="n">strides</span><span class="o">=</span><span class="mi">1</span><span class="p">,</span> <span class="n">padding</span><span class="o">=</span><span class="s1">'same'</span><span class="p">,</span> <span class="n">use_bias</span><span class="o">=</span><span class="kc">False</span><span class="p">)</span>
<span class="bp">self</span><span class="o">.</span><span class="n">b1</span> <span class="o">=</span> <span class="n">BatchNormalization</span><span class="p">()</span>
<span class="bp">self</span><span class="o">.</span><span class="n">a1</span> <span class="o">=</span> <span class="n">Activation</span><span class="p">(</span><span class="s1">'relu'</span><span class="p">)</span>
<span class="bp">self</span><span class="o">.</span><span class="n">blocks</span> <span class="o">=</span> <span class="n">tf</span><span class="o">.</span><span class="n">keras</span><span class="o">.</span><span class="n">models</span><span class="o">.</span><span class="n">Sequential</span><span class="p">()</span>
<span class="c1"># 构建ResNet网络结构</span>
<span class="k">for</span> <span class="n">block_id</span> <span class="ow">in</span> <span class="nb">range</span><span class="p">(</span><span class="nb">len</span><span class="p">(</span><span class="n">block_list</span><span class="p">)):</span> <span class="c1"># 第几个resnet block</span>
<span class="k">for</span> <span class="n">layer_id</span> <span class="ow">in</span> <span class="nb">range</span><span class="p">(</span><span class="n">block_list</span><span class="p">[</span><span class="n">block_id</span><span class="p">]):</span> <span class="c1"># 第几个卷积层</span>
<span class="k">if</span> <span class="n">block_id</span> <span class="o">!=</span> <span class="mi">0</span> <span class="ow">and</span> <span class="n">layer_id</span> <span class="o">==</span> <span class="mi">0</span><span class="p">:</span> <span class="c1"># 对除第一个block以外的每个block的输入进行下采样</span>
<span class="n">block</span> <span class="o">=</span> <span class="n">ResnetBlock</span><span class="p">(</span><span class="bp">self</span><span class="o">.</span><span class="n">out_filters</span><span class="p">,</span> <span class="n">strides</span><span class="o">=</span><span class="mi">2</span><span class="p">,</span> <span class="n">residual_path</span><span class="o">=</span><span class="kc">True</span><span class="p">)</span>
<span class="k">else</span><span class="p">:</span>
<span class="n">block</span> <span class="o">=</span> <span class="n">ResnetBlock</span><span class="p">(</span><span class="bp">self</span><span class="o">.</span><span class="n">out_filters</span><span class="p">,</span> <span class="n">residual_path</span><span class="o">=</span><span class="kc">False</span><span class="p">)</span>
<span class="bp">self</span><span class="o">.</span><span class="n">blocks</span><span class="o">.</span><span class="n">add</span><span class="p">(</span><span class="n">block</span><span class="p">)</span> <span class="c1"># 将构建好的block加入resnet</span>
<span class="bp">self</span><span class="o">.</span><span class="n">out_filters</span> <span class="o">*=</span> <span class="mi">2</span> <span class="c1"># 下一个block的卷积核数是上一个block的2倍</span>
<span class="bp">self</span><span class="o">.</span><span class="n">p1</span> <span class="o">=</span> <span class="n">tf</span><span class="o">.</span><span class="n">keras</span><span class="o">.</span><span class="n">layers</span><span class="o">.</span><span class="n">GlobalAveragePooling2D</span><span class="p">()</span>
<span class="bp">self</span><span class="o">.</span><span class="n">f1</span> <span class="o">=</span> <span class="n">tf</span><span class="o">.</span><span class="n">keras</span><span class="o">.</span><span class="n">layers</span><span class="o">.</span><span class="n">Dense</span><span class="p">(</span><span class="mi">10</span><span class="p">,</span> <span class="n">activation</span><span class="o">=</span><span class="s1">'softmax'</span><span class="p">,</span> <span class="n">kernel_regularizer</span><span class="o">=</span><span class="n">tf</span><span class="o">.</span><span class="n">keras</span><span class="o">.</span><span class="n">regularizers</span><span class="o">.</span><span class="n">l2</span><span class="p">())</span>
<span class="k">def</span> <span class="nf">call</span><span class="p">(</span><span class="bp">self</span><span class="p">,</span> <span class="n">inputs</span><span class="p">):</span>
<span class="n">x</span> <span class="o">=</span> <span class="bp">self</span><span class="o">.</span><span class="n">c1</span><span class="p">(</span><span class="n">inputs</span><span class="p">)</span>
<span class="n">x</span> <span class="o">=</span> <span class="bp">self</span><span class="o">.</span><span class="n">b1</span><span class="p">(</span><span class="n">x</span><span class="p">)</span>
<span class="n">x</span> <span class="o">=</span> <span class="bp">self</span><span class="o">.</span><span class="n">a1</span><span class="p">(</span><span class="n">x</span><span class="p">)</span>
<span class="n">x</span> <span class="o">=</span> <span class="bp">self</span><span class="o">.</span><span class="n">blocks</span><span class="p">(</span><span class="n">x</span><span class="p">)</span>
<span class="n">x</span> <span class="o">=</span> <span class="bp">self</span><span class="o">.</span><span class="n">p1</span><span class="p">(</span><span class="n">x</span><span class="p">)</span>
<span class="n">y</span> <span class="o">=</span> <span class="bp">self</span><span class="o">.</span><span class="n">f1</span><span class="p">(</span><span class="n">x</span><span class="p">)</span>
<span class="k">return</span> <span class="n">y</span>
model = ResNet18 ([ 2 , 2 , 2 , 2 ])
为加速收敛,可将history中的batch_size调整为128。
2.6 对比
经典卷积网络对比:













 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)