
LSTM内部结构及前向传播原理——LSTM从零实现系列(1)
LSTM前向传播原理
一、前言
作为专注于时间序列分析的玩家,虽然LSTM用了很久但一直没有写过一篇自己的LSTM原理详解,所以这次要写一个LSTM的从0到1的系列,从模型原理讲解到最后不借助三方框架自己手写代码来实现LSTM模型。本文本身没有特别独到之处,因为网上其实已经有很多优秀的关于LSTM讲解的文章,文章也做了很多借鉴;本文一方面是作为后续讲解如何从0实现LSTM的前置阅读内容,另一方面是作为自己多年对LSTM学习和理解的总结,同时也为作者的后续在此方向进一步的理论研究做铺垫。
LSTM是建立在普通的神经网络之上,准确说是建立在循环神经网络RNN之上,加上其可叠加的特性,一般归为深度学习范畴。对于神经网络和RNN这些前置知识之前已经写过很多文章,可参考下面链接。本文重点讲解LSTM的算法机制,为后续实现手写LSTM模型做铺垫。
人工智能专题研究![]() https://blog.csdn.net/yangwohenmai1/category_9126892.html
https://blog.csdn.net/yangwohenmai1/category_9126892.html
LSTM主要解决了RNN的梯度消失和梯度爆炸问题,实现了时间序列的长期预测功能,这一机制的实现方案类似残差网络,利用一条单独通路,将过去的记忆尽可能多的向未来传递,再通过LSTM模型内部的各种控制门来对过去的记忆内容进行提取,舍弃,修正,变成当前的输出结果。再将当前时间步的结果和修改过的记忆信息向下一个LSTM单元传递。
LSTM的缺点是如果我们输入的历史序列很长,则LSTM模型的内存和训练时间会大大增加,这是由于LSTM内部的计算过程复杂和监督学习数据的特殊结构所导致的。所以后来推出了简化版的LSTM,即GRU,我将其视为LSTM的儿子,LSTM则是爸爸。下面就来了解一下LSTM的原理,图片大多是从网络上借鉴而来,文尾附参考文献链接。
二、LSTM结构特点
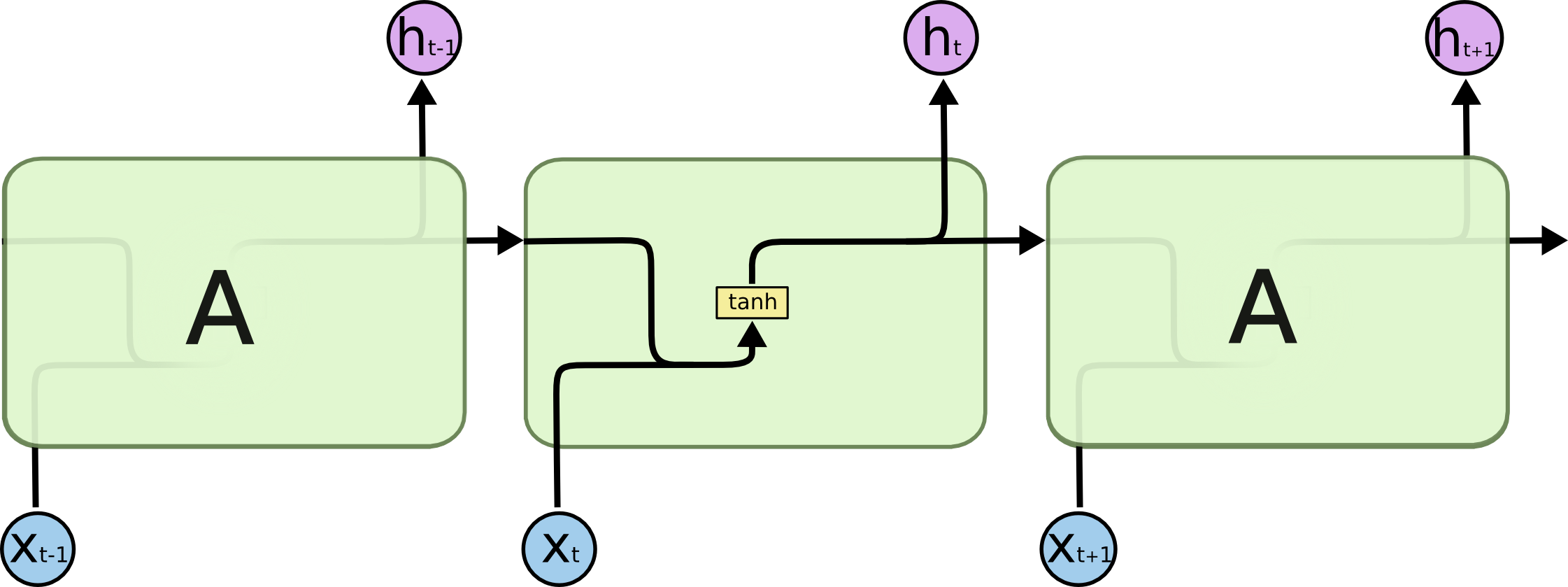
一般的RNN可以理解为多个相同的单元循环链接,将本次循环的状态向后传递,作为下次循环输入的一部分。缺点是不论激活函数如何选择,都会出现梯度爆炸或梯度消失的问题,因为最后链式求导过程都是连乘的形式。常见的RNN结构如下:
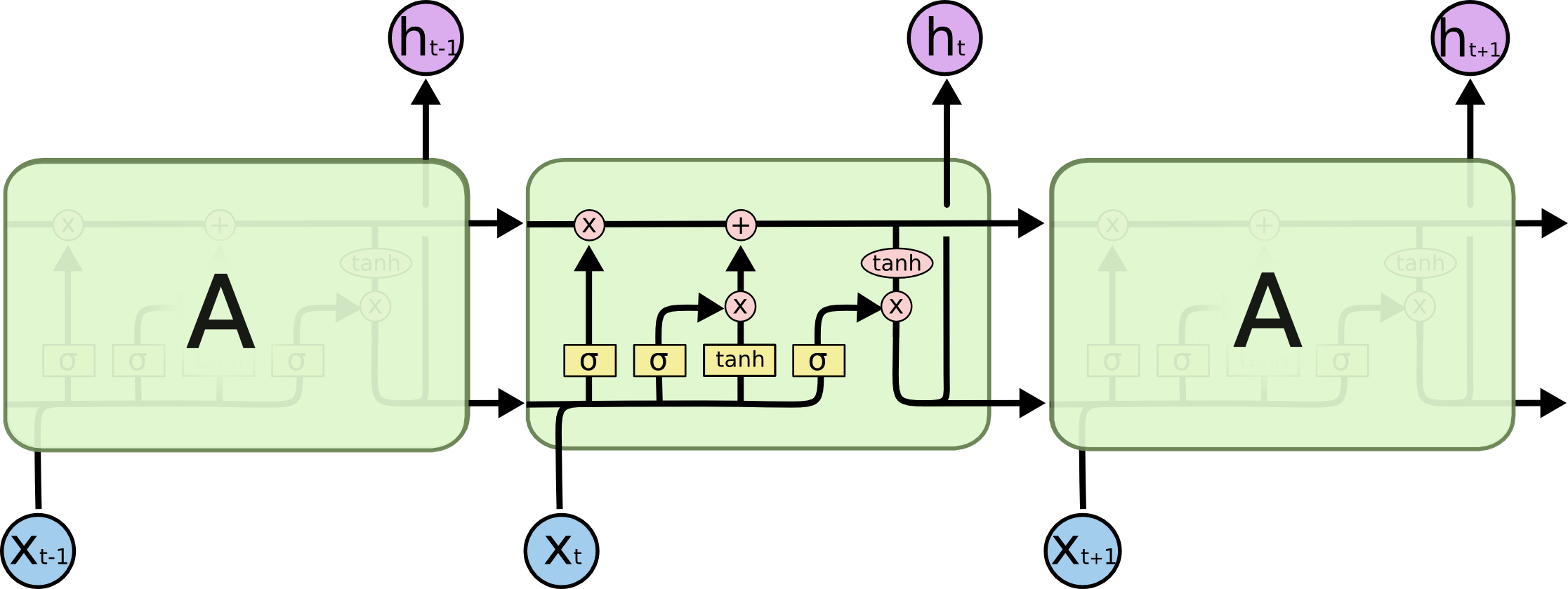
LSTM比RNN内部结构复杂的多,总的来说有三大控制门,分别是遗忘门、候选记忆门、输出门,还有一条负责传送长期记忆的传送带。就是这些门对历史信息进行提取、舍弃、更新这些精细化控制,同时也保证了模型不会出现梯度消失和梯度爆炸的情况。LSTM网络结构如下:
LSTM最核心的机制就是这个历史信息“传送带”,一方面它贯穿了整个“循环网络”,将历史的信息顺畅的向后传递,另一方面每个单元在更新历史信息时使用的是“+”而不是“×”,这使得链式求导时避免了连乘的出现,从而解决了梯度爆炸和梯度消失的问题。对应功能模块如下:

LSTM整体结构的中文示意图如下,这个结构中有两个重要参数分别是“记忆细胞”C和“隐藏状态”H,一般来说我们称C为长期记忆,H为短期记忆。原则上不建议也不应该用拟人的方式去解释神经网络,但是为了方便理解各个功能模块后续就沿用这种描述方式。下面我们就对每个过程进行拆分讲解。
三、LSTM原理分步解析
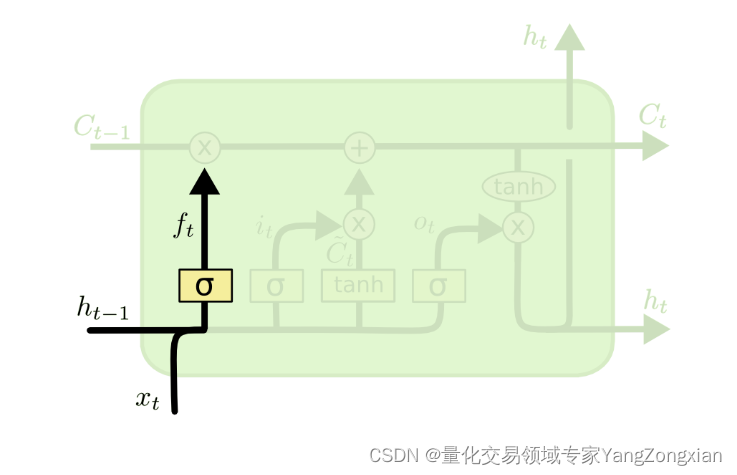
3.1.遗忘门的原理:
遗忘门可表示为下式,其中
表示输入
传递到
对应的权重矩阵,
表示上一时间步状态
传递到
对应的权重矩阵,
表示偏置项。通过激活函数
将
的计算结果限定在(0,1)之间。
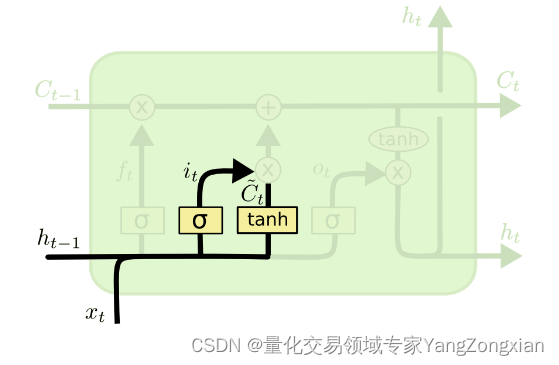
3.2.输入门的原理:
输入门可表示为下式,其中
表示输入
传递到
对应的权重矩阵,
表示上层状态
传递到
对应的权重矩阵,
表示偏置项。通过激活函数
将
的计算结果限定在(0,1)之间。
中间状态可表示为下式, 其中
表示输入
传递到
对应的权重矩阵,
表示上层状态
传递到
对应的权重矩阵,
表示偏置项。通过激活函数
将
的计算结果限定在(-1,1)之间。这里为什么使用
而不用
其实没有定论,根据经验激活函数的选择应该是作者通过超参数后得出的较优结论,不具有明确的可解释行。
3.3.候选记忆的原理:
输出状态可表示为下式,其中
是上一时间步传递过来的输出状态,
、
、
是遗忘门、输入门、中间状态的计算结果。
表示遗忘门
和上一时间步的状态
做逐点相乘,
,使矩阵中接近0的位置的内容被遗忘,接近1位置的部分被保留,达到选择性遗忘的效果。
表示输出入门
和中间状态
进行逐点相乘,得到新的候选记忆,也即需要记忆的新特征。
,决定了
的信息是完全保留还是全部忘记。
最后我们用遗忘掉历史记忆
中的信息,将新的记忆
添加到
中,构成了当前时间步的新记忆
。
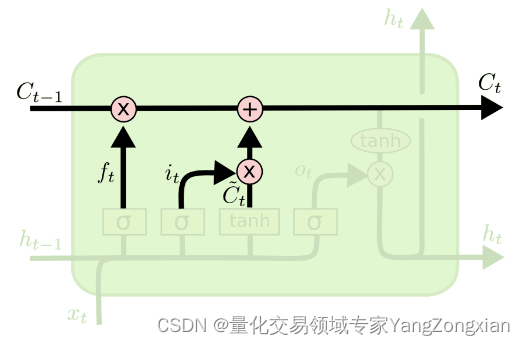
3.4.输出门的原理:
输出门可表示为下式,其中
表示输入
传递到
对应的权重矩阵,
表示上个时间步的状态
传递到
对应的权重矩阵,
表示偏置项。通过激活函数
将
的计算结果限定在(0,1)之间。
输出状态可表示为下式,将输出门
与
逐点相乘,得到当前时间步新的输出状态,作为下个时间步输入的一部分。
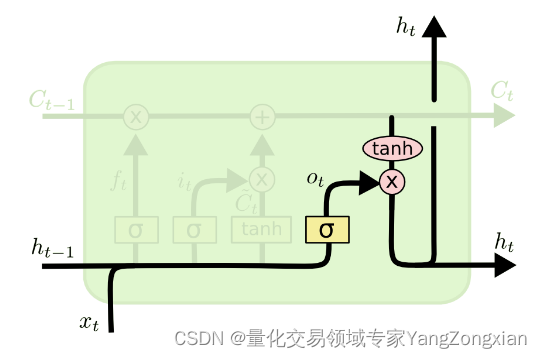
3.5.总结:
此时我们就得到一套完整的大脑机制,遗忘门忘掉没用的信息,输入门和候选记忆产生新的记忆信息,输出门负责更新记忆,再将新的记忆送给下一个神经元。
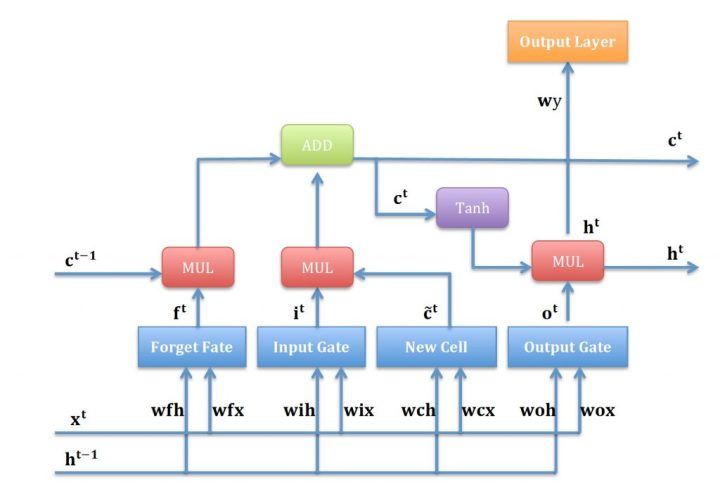
上述内容基本就是LSTM核心的工作流程,通过将每个功能模块组合起来,就构成了完整的LSTM模型,下面介绍一下数据如何在LSTM模型中流转。
四、多层LSTM以及前向传播的细节
下面问题来了,LSTM一般属于深度学习范畴,那深度学习必然会有多层模型进行叠加传参的问题。说到模型叠加一般网上就会给出类似下面这张图,这种图可能除了画图人自己,没多少人能看明白参数是怎么传递的。 那么对于LSTM这种更加复杂的RNN类模型,作者讲解一下参数是如何传递的。
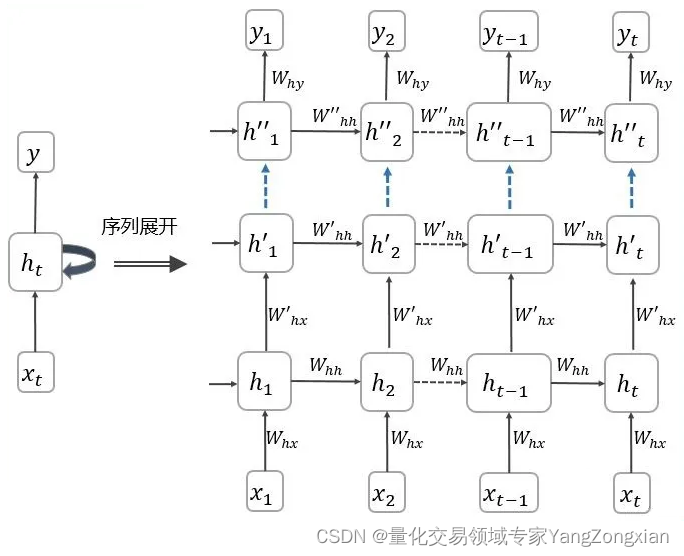
4.1.多层LSTM结构
下图是一个双层LSTM的示例,我们一起分析一下参数是如何在模型中流转的。首先要明确的是图中双层LSTM分别指第一行的3个LSTM单元和第二行的3个LSTM单元,而每一行中的3个LSTM单元表示的是当前LSTM层包含3个时间步。传播方向由第二行指向第一行。
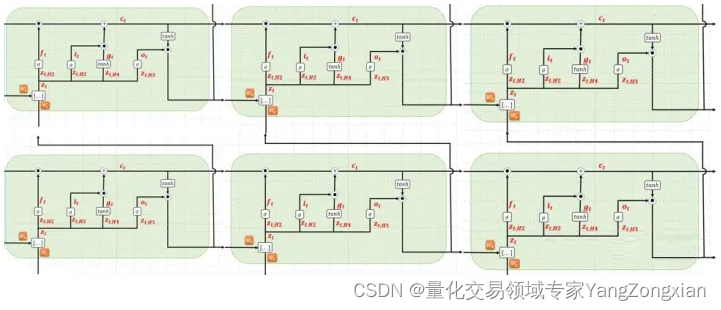
4.2.第一层LSTM计算
首先看下输入数据x在第一层LSTM中的流转,蓝色方框表示第一层LSTM。
- 我们知道LSTM单元包含三个输入参数x,c,h,首先x1作为第一个时间步,输入到第一个LSTM单元中,此时输入的初始c0和h0都是0矩阵,计算完成后,第一个LSTM单元输出新的一组h1,c1,作为本层LSTM的第二个时间步的输入参数。
- 因此第二个时间步的输入就是h1,c1,x2,而输出是h2,c2
- 因此第三个时间步的输入就是h2,c2,x3,而输出是h3,c3
至此第一层LSTM的三个时间步计算完成,我们得到了三个输出结果(h1,h2,h3)。
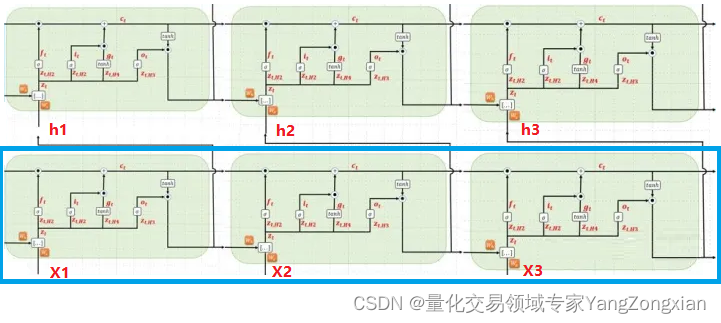
4.3.第二层LSTM计算
在下图中,蓝色方框对应的是第二层LSTM,本层没有输入参数x1,x2,x3,所以我们将第一层LSTM输出的(h1,h2,h3),作为第二层LSTM的输入x1,x2,x3。
- 第一个时间步输入的初始c0和h0都为0矩阵,计算完成后,第一个时间步输出新的一组h1,c1,作为本层LSTM的第二个时间步的输入参数。
- 因此第二个时间步的输入就是h1,c1,x2,而输出是h2,c2
- 因此第三个时间步的输入就是h2,c2,x3,而输出是h3,c3
直到LSTM的三个时间步计算完成,又会得到三个新输出(h1,h2,h3),可以继续向后传播,或者直接传入全连接层,将其映射到对应的输出结果。
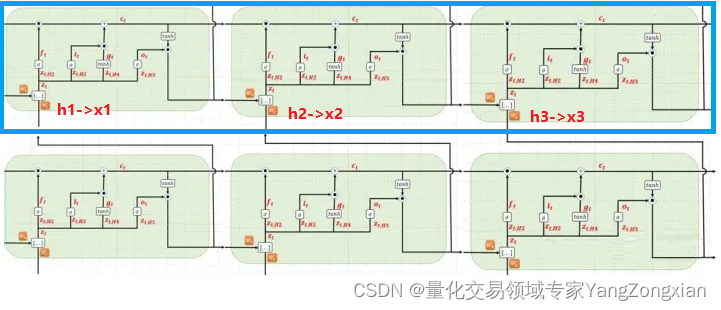
上述流程就是多层LSTM内部实现前向传播的数据流转过程。更具体的流程后续我们会在源码实现中讲解。
五、总结
本文讲解了LSTM的内部结构,原理机制,以及前向传播流程。下片文章讲解LSTM的反向传播流程。链接如下:
写作中。。。。
参考文献:
Stateful LSTM in Keras – Philippe Remy – My Blog.
https://colah.github.io/posts/2015-08-Understanding-LSTMs/

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 13
13 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)