

基于LSTM的股票预测
RNN主要用来处理序列数据,在传统的神经网络模型中,是从输入层到隐含 层再到输出层,每层内的节点之间无连接,循环神经网络中一个当前神经元的输出与前面的输出也有关,网络会对前面的信息进行记忆并应用于当前神经元的计算中,隐藏层之间的节点是有连接的,并且隐藏层的输入不仅包含输入层的输出还包含上一时刻隐藏层的输出。理论上,RNN可以对任意长度的序列数据进行处理。一个RNN可认为是同一网络的多次重复执行,每
1、概述
1.1 RNN(循环神经网络)
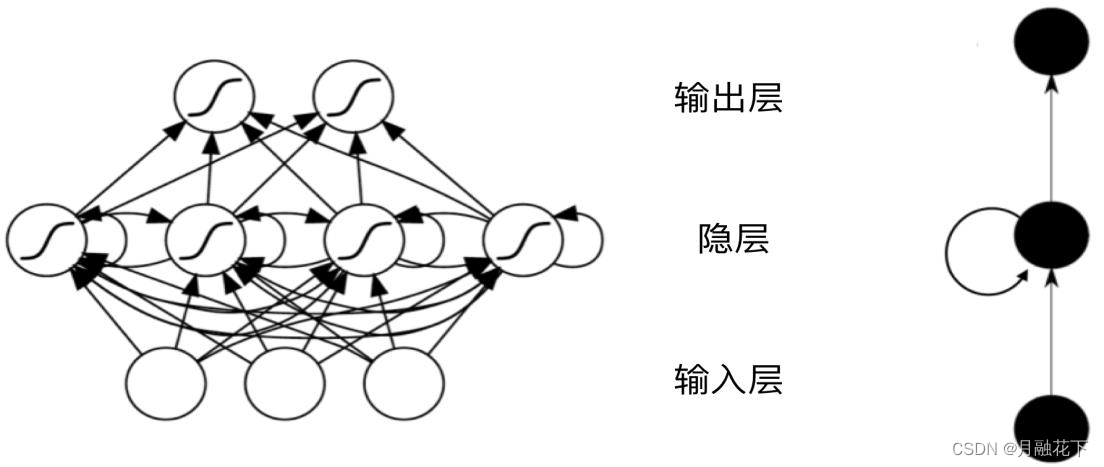
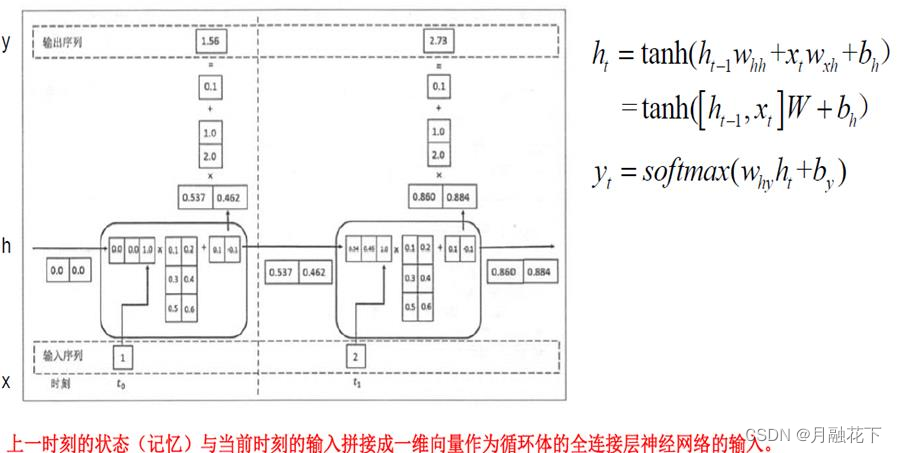
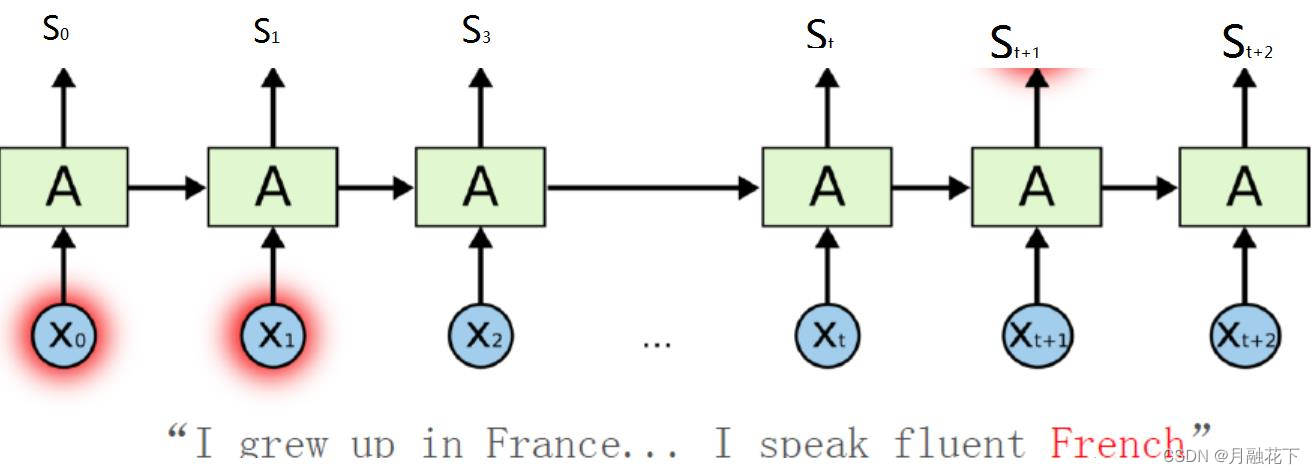
RNN缺陷:长期依赖(Long Term Dependencies)问题,产生长跨度依赖的问题。
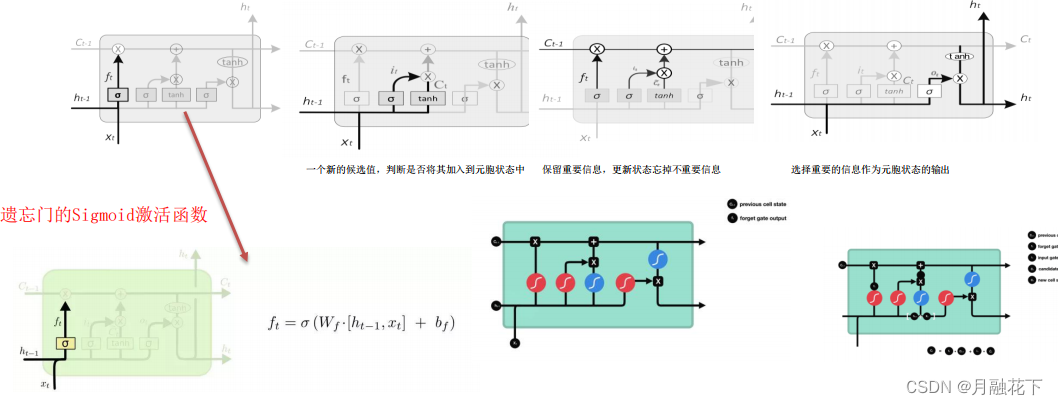
1.2 LSTM(长短期记忆神经网络)
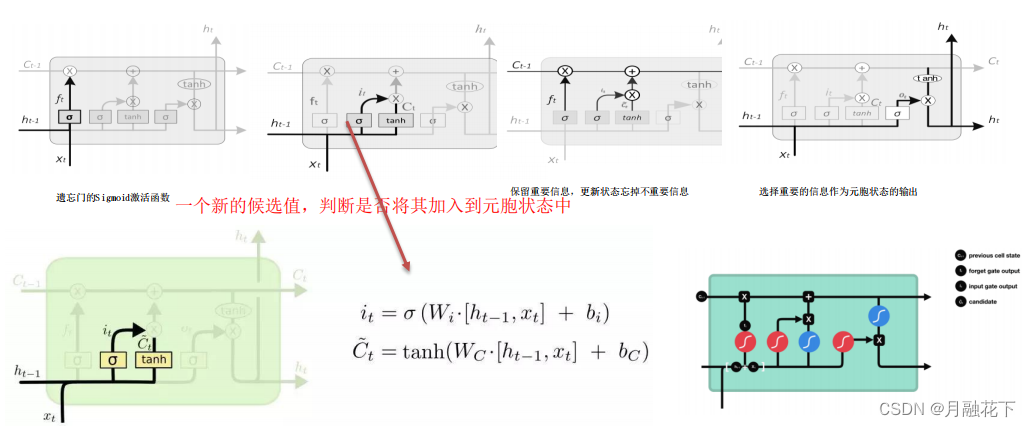
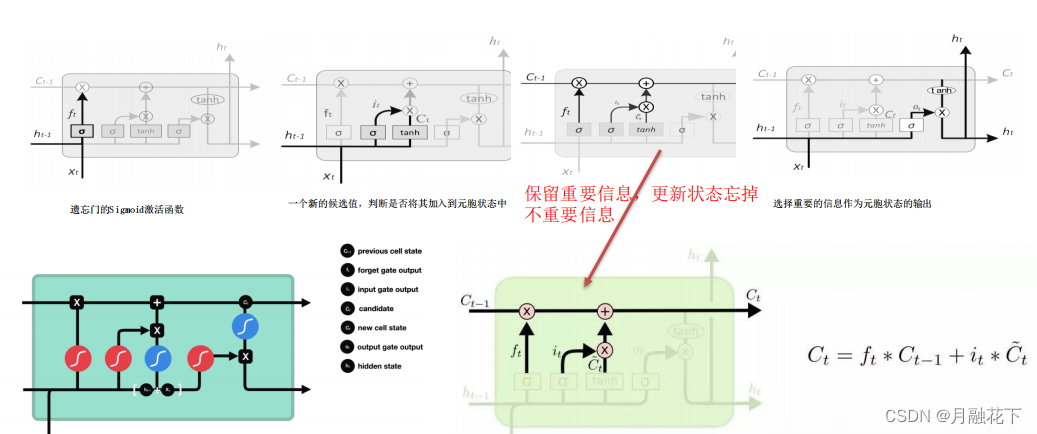
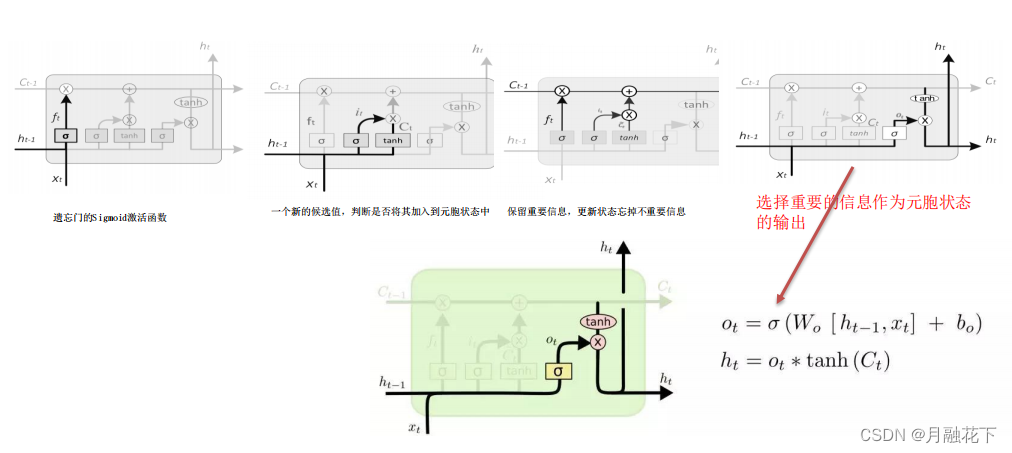
2、实验部分
2.1 模块加载
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import math
import sklearn
import sklearn.preprocessing
import os
from datetime import datetime
import pandas as pd2.2 准备数据
# import all stock prices
df = pd.read_csv("./sh300index.csv", index_col = 0)
df.info()
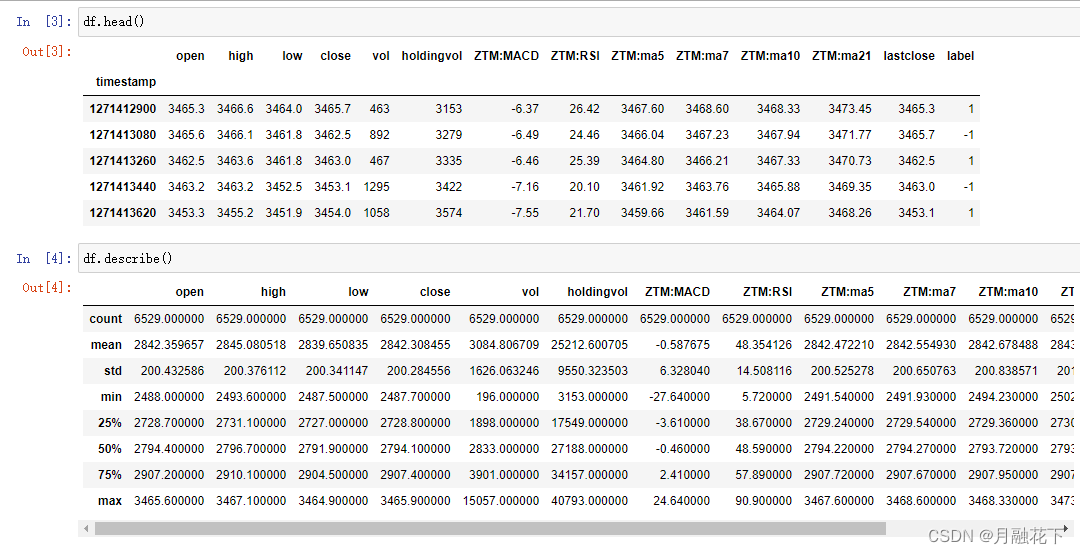
2.3 数据可视化
plt.figure(figsize=(15, 5));
plt.subplot(2,1,1);
plt.plot(df.open.values, color='red', label='open')
plt.plot(df.close.values, color='green', label='close')
plt.plot(df.low.values, color='blue', label='low')
plt.plot(df.high.values, color='black', label='high')
plt.title('stock price')
plt.xlabel('time [days]')
plt.ylabel('price')
plt.legend(loc='best')
plt.subplot(2,1,2);
plt.plot(df.vol.values, color='black', label='volume')
plt.title('stock volume')
plt.xlabel('time [days]')
plt.ylabel('volume')
plt.legend(loc='best');
plt.show() 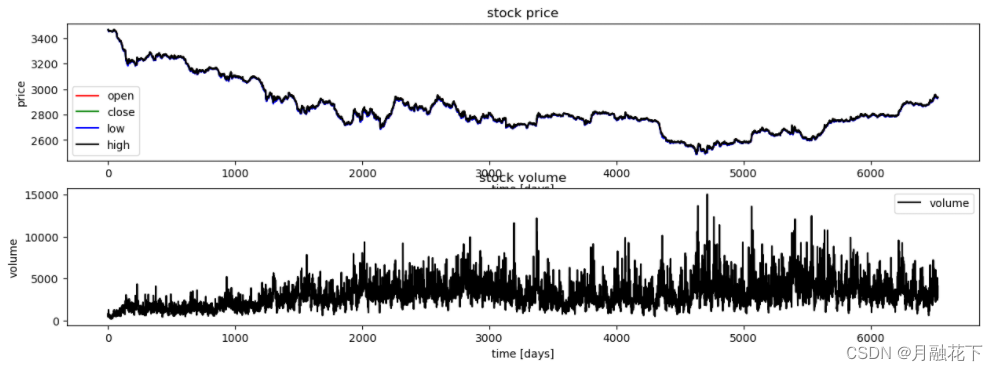
2.4 数据预处理
#按照80%/10%/10%,划分训练集,验证集和测试集
vaild_set_size_percentage = 10
test_set_size_percentage = 10
#min-max 归一化 只选择open、high、low、close的数据
def normalize_data(df):
min_max_scaler = sklearn.preprocessing.MinMaxScaler()
df['open'] = min_max_scaler.fit_transform(df.open.values.reshape(-1,1))
df['high'] = min_max_scaler.fit_transform(df.high.values.reshape(-1,1))
df['low'] = min_max_scaler.fit_transform(df.low.values.reshape(-1,1))
df['close'] = min_max_scaler.fit_transform(df['close'].values.reshape(-1,1))
return df
#划分数据集
def load_data(stock, seq_len):
#转换矩阵
data_raw = stock.to_numpy() # pd to numpy array
data = []
# create all possible sequences of length seq_len
#len(data_raw) 6529
for index in range(len(data_raw) - seq_len):
data.append(data_raw[index: index + seq_len])
#矩阵
data = np.array(data);
#data.shape (6509, 20, 4)
#valid_set_size 651
valid_set_size = int(np.round(vaild_set_size_percentage/100*data.shape[0]));
#test_set_size 651
test_set_size = int(np.round(test_set_size_percentage/100*data.shape[0]));
#train_set_size 5207
train_set_size = data.shape[0] - (valid_set_size + test_set_size);
x_train = data[:train_set_size,:-1,:]
y_train = data[:train_set_size,-1,:]
x_valid = data[train_set_size:train_set_size+valid_set_size,:-1,:]
y_valid = data[train_set_size:train_set_size+valid_set_size,-1,:]
x_test = data[train_set_size+valid_set_size:,:-1,:]
y_test = data[train_set_size+valid_set_size:,-1,:]
return [x_train, y_train, x_valid, y_valid, x_test, y_test]去除多余的数据:
DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')
功能:删除数据集中多余的数据
参数:
labels:待删除的行名or列名;
axis:删除时所参考的轴,0为行,1为列;
index:待删除的行名
columns:待删除的列名
level:多级列表时使用,暂时不作说明
inplace:布尔值,默认为False,这是返回的是一个copy;若为True,返回的是删除相应数据后的版本
errors一般用不到,这里不作解释
#去除冗余指标
df_stock = df.copy()
df_stock.drop(['vol'],1,inplace=True)
df_stock.drop(['lastclose'],1,inplace=True)
df_stock.drop(['label'],1,inplace=True)
df_stock.drop(['ZTM:ma5'],1,inplace=True)
df_stock.drop(['ZTM:ma7'],1,inplace=True)
df_stock.drop(['ZTM:ma10'],1,inplace=True)
df_stock.drop(['ZTM:ma21'],1,inplace=True)
df_stock.drop(['holdingvol'],1,inplace=True)
df_stock.drop(['ZTM:MACD'],1,inplace=True)
df_stock.drop(['ZTM:RSI'],1,inplace=True)
#查看数据
df_stock.head()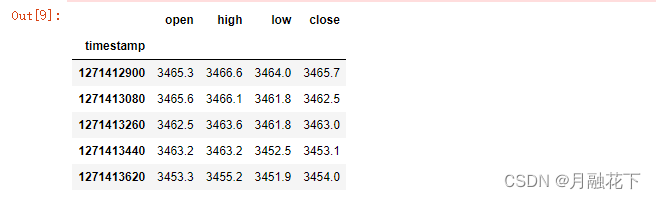
#输出输入列名
cols = list(df_stock.columns.values)
print(cols)![]()
#对指标进行归一化处理
df_stock_norm = normalize_data(df_stock)
df_stock_norm.head()
#查看训练集、验证集和测试集情况
seq_len = 20; #设置最长序列长度
x_train,y_train,x_valid,y_valid,x_test,y_test = load_data(df_stock_norm,seq_len)
print('x_train.shape = ',x_train.shape)
print('y_train.shape = ', y_train.shape)
print('x_valid.shape = ',x_valid.shape)
print('y_valid.shape = ', y_valid.shape)
print('x_test.shape = ', x_test.shape)
print('y_test.shape = ',y_test.shape)
#对指标数据进行可视化
plt.figure(figsize=(15, 6));
plt.plot(df_stock_norm.open.values, color='red', label='open')
plt.plot(df_stock_norm.close.values, color='green', label='close')
plt.plot(df_stock_norm.low.values, color='blue', label='low')
plt.plot(df_stock_norm.high.values, color='black', label='high')
plt.title('stock')
plt.xlabel('time [days]')
plt.ylabel('normalized price/volume')
plt.legend(loc='best')
plt.show()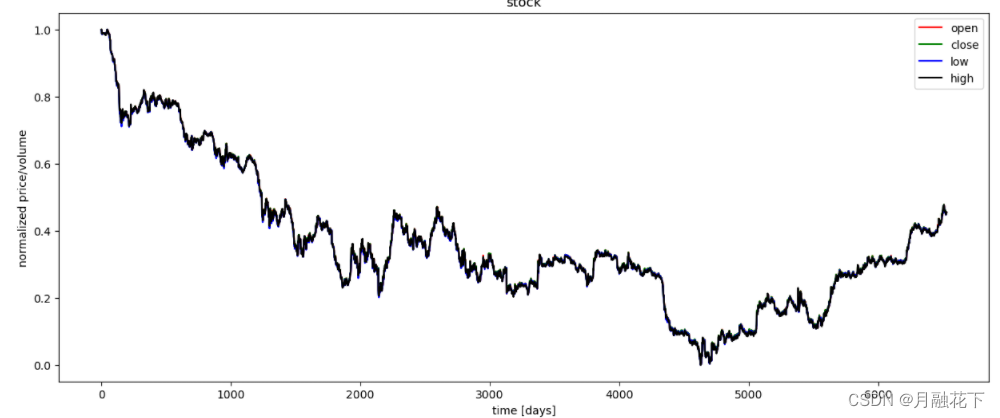
2.5 RNN建模-LSTM/GRU
#对训练数据随机处理
index_in_epoch = 0;
perm_array = np.arange(x_train.shape[0])
print(perm_array)
np.random.shuffle(perm_array)
print(perm_array)
数据读取的方式:
# 数据读取方法
def get_next_batch(batch_size):
global index_in_epoch, x_train, perm_array
start = index_in_epoch #start=0
index_in_epoch += batch_size #batch_size=50
if index_in_epoch > x_train.shape[0]:
np.random.shuffle(perm_array) # shuffle permutation array
start = 0 # start next epoch
index_in_epoch = batch_size
end = index_in_epoch
return x_train[perm_array[start:end]], y_train[perm_array[start:end]]#定义超参
n_steps = seq_len-1
#输入大小(与指标数量对应)
n_inputs = 4
n_neurons = 200
#输出大小(与指标数量对应)
n_outputs = 4
#层数
n_layers = 2
#学习率
learning_rate = 0.001
#批大小
batch_size = 50
#迭代训练次数
n_epochs = 20
#训练集大小 5207
train_set_size = x_train.shape[0]
#测试集大小 651
test_set_size = x_test.shape[0]2.6 网络结构
tensorflow版本迁移查询:tf.keras.layers.RNN | TensorFlow v2.13.0
tf.contrib.rnn.LSTMCell(
num_units,
use_peepholes=False,
cell_clip=None,
initializer=None,
num_proj=None,
proj_clip=None,
num_unit_shards=None,
num_proj_shards=None,
forget_bias=1.0,
state_is_tuple=True,
activation=None,
reuse=None,
name=None,
dtype=None,
**kwargs
)
用法:LSTM的一个单元细胞定义, LSTM由三个门组成,分别是:遗忘门,输入门、输出门
参数:
num_units: int型, LSTM网络单元的个数,即隐藏层的节点数。
use_peepholes: bool型, 默认False,True表示启用Peephole连接。
cell_clip: (可选) 一个浮点值, 是否在输出前对cell状态按照给定值进行截断处理。
initializer: (可选) 权重和映射矩阵的初始化器。
num_proj: (可选) int型, 映射矩阵的输出维度,如果为None,则不会进行映射。
proj_clip: (可选) 一个浮点值. 如果num_proj > 0 而且proj_clip不为空,那么映射后的值被逐元素裁剪到[-proj_clip, proj_clip]的分为内.
num_unit_shards: Deprecated.
num_proj_shards: Deprecated.
forget_bias: 在训练开始时,为了减小遗忘尺度,遗忘门的偏置默认初始化为1.0,当从已经训练好的CudnnLSTM的checkpoints文件恢复时,
这个值必须手动设置为0.
state_is_tuple: 如果为True, 接受的和返回的状态是一个(c, h)的二元组,其中c为细胞当前状态,h为当前时间段的输出的同时,
也是下一时间段的输入的一部分。如果为False, 那么它们会concatenated到一起. 为False的情况将来会废弃.
activation: 内部状态的激活函数,默认为tanh.
reuse: (可选)bool型,是否重用已经存在scope中的变量. 如果为False, 而且已经存在的scope中已经有同一个变量,则会出错.
name: String型, 网络层的名字,拥有相同名字的网络层将共享权重,但是为了避免出错,这种情况需要设置reuse=True.
dtype: 网络层的默认类型,默认为None,意味着使用第一次输入的类型.
**kwargs: Dict型, 一般网络层属性的关键字命名属性.
tf.contrib.rnn.GRUCell(
num_units,
activation=None,
reuse=None,
kernel_initializer=None,
bias_initializer=None,
name=None,
dtype=None
)
作用:GRU的一个单元细胞定义,GRU只有两个门了,分别为更新门和重置门
参数:
num_unit:GRU cell中神经元数量。即隐藏的神经元数量。activation:使用的激活函数
resue:布尔型,表示是否在现有的scope中重复使用变量。如果不为True,并且现有的scope中已经存在给定的变量,则会产生错误。
Kernel_initializer:可选参数,权重和投影矩阵使用的初始化器。
Bias_initializer:可选参数,偏置使用的初始化器。
name:该层的名称。拥有同样名称的层共享权重,但为了避免错误,一般会使用reuse=True
dtype:该层默认的数据类型。
————————————————————————————————————————————————
tf.contrib.rnn.MultiRNNCell(
cells,
state_is_tuple=True
)
用法:将多个单元细胞堆叠后得到一个多层的单元细胞
参数:
cells: RNNCells的列表,RNN网络将会按照这个顺序搭建.
state_is_tuple: 如果为True, 接受和返回的状态将为一个n元组,其中n = len(cells).
————————————————————————————————————————————————
tf.contrib.nn.DropoutWrapper(
cell,
input_keep_prob=1.0,
output_keep_prob=1.0,
state_keep_prob=1.0,
variational_recurrent=False,
input_size=None,
dtype=None,
seed=None,
dropout_state_filter_visitor=None
)
用法:RNN中的Dropout层,与CNN中Dropout类似
参数:
cell: 一个RNNCell, a projection to output_size is added to it.
input_keep_prob: tensor单元或者位于0~1之间的浮点数,表示输入的保留概率。如果为常数而且为1,那么输入的Dropout将不会被添加。
output_keep_prob: tensor单元或者位于0~1之间的浮点数,表示输出的保留概率,如果为常数而且为1,那么输出的Dropout将不会被添加。
state_keep_prob: tensor单元或者位于0~1之间的浮点数,表示输出的保留概率,如果为常数而且为1,那么输出的Dropout将不会被添加。
State dropout是在细胞单元的外部状态被执行. 注意,对于状态模块而言,当state_keep_prob为(0,1)时,dropout被执行,
但是状态模块依然受到dropout_state_filter_visitor参数的影响.(例如. 默认情况下,dropout模型情况下dropout模块不会应用到LSTMStateTuple的 c 模块.
variational_recurrent: bool型,如果为True, 那么每运行一次调用,相同的dropout模式将应用到所有的时间步骤。如果设置这个参数,那么必须要提供input_size.
input_size: (可选) (possibly nested tuple of) TensorShape对象,包含输入tensor的深度.如果variational_recurrent = True为True
而且input_keep_prob < 1时需要设置这个参数.
dtype: (可选)输入、状态和输出tensor的类型,当variational_recurrent = True时,需要设置这个参数.
seed: (可选) integer型,随机数种子.
dropout_state_filter_visitor: (可选),一个函数默认为None. 该函数获取状态的任何层次级别并返回标量或深度= 1的Python布尔结构的函数,
该结构描述应该删除状态中的哪些术语。 此外,如果函数返回True,则会在此子级中应用dropout。 如果函数返回False,则不会在整个子级中应用dropout。
默认情况为:对除LSTMCellState对象的内存状态(c)之外的所有术语执行dropout,并且不要尝试将dropout应用于TensorArray对象.
tf.nn.dynamic_rnn(
cell,
inputs,
sequence_length=None,
initial_state=None,
dtype=None,
parallel_iterations=None,
swap_memory=False,
time_major=False,
scope=None
)
参数:
cell:LSTM、GRU等的记忆单元。cell参数代表一个LSTM或GRU的记忆单元,也就是一个cell。例如,cell = tf.nn.rnn_cell.LSTMCell((num_units),其中, num_units表示rnn cell中神经元个数,也就是下文的cell.output_size。返回一个LSTM或GRU cell,作为参数传入。
inputs:输入的训练或测试数据,一般格式为[batch_size, max_time, embed_size],其中batch_size是输入的这批数据的数量,max_time就是这批数据中序列的 最长长度,embed_size表示嵌入的词向量的维度。
sequence_length:是一个list,假设你输入了三句话,且三句话的长度分别是5,10,25,那么sequence_length=[5,10,25]。
time_major:决定了输出tensor的格式,如果为True, 张量的形状必须为 [max_time, batch_size,cell.output_size]。如果为False, tensor的形状必须为 [batch_size, max_time, cell.output_size],cell.output_size表示rnn cell中神经元个数。
返回值:元组(outputs, states)
outputs:outputs很容易理解,就是每个cell会有一个输出
states:states表示最终的状态,也就是序列中最后一个cell输出的状态。一般情况下states的形状为 [batch_size, cell.output_size ],但当输入的cell为 BasicLSTMCell时,state的形状为[2,batch_size, cell.output_size ],其中2也对应着LSTM中的cell state和hidden state。———————————————————————————————————————————————————————————————————————
tf.keras.layers.RNN(
cell,
return_sequences=False,
return_state=False,
go_backwards=False,
stateful=False,
unroll=False,
time_major=False,
**kwargs
)
参数:
cell:一个RNN单元实例或一个RNN单元实例列表
return_sequences:布尔值(默认为False)。是返回输出序列中的最后一个输出,还是返回整个序列。
return_state:布尔值(默认为False)。除输出外,是否返回最后一个状态。
go_backwards:布尔值(默认为False)。如果为True,则反向处理输入序列并返回反转的序列。
stateful:布尔值(默认为False)。如果为True,则一个批次中索引i处的每个样本的最后状态将用作下一个批次中索引i的样本的初始状态。
unroll:布尔值(默认为False)。如果为True,网络将展开,否则将使用符号循环。展开可以加快RNN的速度,尽管它往往占用更多的内存。展开只适用于短序列。
time_major:输入和输出张量的形状格式。如果为True,则输入和输出将是形状(timesteps, batch,…),而在False情况下,它将是(batch, timesteps,…)。使用time_major = True更有效,因为它避免了RNN计算开始和结束时的调换。然而,大多数TensorFlow数据是批处理的,因此默认情况下,该函数接受输入并以批处理的形式发出输出。
# tf.reset_default_graph()
tf.compat.v1.disable_eager_execution()
#n_steps=19 n_inputs=4
x = tf.compat.v1.placeholder(tf.float32, [None, n_steps, n_inputs]) #(None,19,4)
#n_outputs=4
y = tf.compat.v1.placeholder(tf.float32, [None, n_outputs]) #(None,4)
# 使用GRU单元结构
#n_neurons = 200 n_layers=2
#tensorflow2.0 中contrib 已经丢弃 tf.compat.rnn 改为 tf.compat.v1.nn.run_cell
#layers = [tf.compat.v1.nn.rnn_cell.GRUCell(num_units=n_neurons, activation=tf.nn.leaky_relu) for layer in range(n_layers)]
# multi_layer_cell = tf.compat.v1.nn.rnn_cell.MultiRNNCell(layers)
# #tf.compat.v1.nn.dynamic_rnn已经没有使用
# rnn_outputs, states = tf.compat.v1.nn.dynamic_rnn(multi_layer_cell, X, dtype=tf.float32)
layers = [tf.keras.layers.GRUCell(units=n_neurons, activation=tf.nn.leaky_relu) for layer in range(n_layers)]
rnn_layer = tf.keras.layers.RNN(layers,return_sequences=True,return_state=True)
rnn_outputs = rnn_layer(x)
print(rnn_outputs)
stacked_rnn_outputs = tf.reshape(rnn_outputs[0], [-1, n_neurons]) #(-1,200)
stacked_outputs = tf.compat.v1.layers.dense(stacked_rnn_outputs, n_outputs) #(-1,4)
#n_steps=19
outputs = tf.reshape(stacked_outputs, [-1, n_steps, n_outputs]) #(-1,19,4)
outputs = outputs[:,n_steps-1,:] # 定义输出
print(outputs)
loss = tf.reduce_mean(tf.square(outputs - y)) # 使用MSE作为损失
optimizer = tf.compat.v1.train.AdamOptimizer(learning_rate=learning_rate)
training_op = optimizer.minimize(loss)
2.7 模型训练
# 执行训练
with tf.compat.v1.Session() as sess:
sess.run(tf.compat.v1.global_variables_initializer())
#n_epochs*train_set_size/batch_size 20*10/50=4
for iteration in range(int(n_epochs*train_set_size/batch_size)):
x_batch, y_batch = get_next_batch(batch_size) # fetch the next training batch
sess.run(training_op, feed_dict={x: x_batch, y: y_batch})
if iteration % int(5*train_set_size/batch_size) == 0:
mse_train = loss.eval(feed_dict={x: x_train, y: y_train})
mse_valid = loss.eval(feed_dict={x: x_valid, y: y_valid})
print('%.2f epochs: MSE train/valid = %.6f/%.6f'%(
iteration*batch_size/train_set_size, mse_train, mse_valid))
y_train_pred = sess.run(outputs, feed_dict={x: x_train})
y_valid_pred = sess.run(outputs, feed_dict={x: x_valid})
y_test_pred = sess.run(outputs, feed_dict={x: x_test})

2.8 模型应用-预测
ft = 0 # 0 = open, 1 = close, 2 = highest, 3 = lowest
#结果可视化
plt.figure(figsize=(15, 5));
plt.subplot(1,2,1);
plt.plot(np.arange(y_train.shape[0]), y_train[:,ft], color='blue', label='train target')
plt.plot(np.arange(y_train.shape[0], y_train.shape[0]+y_valid.shape[0]), y_valid[:,ft],
color='gray', label='valid target')
plt.plot(np.arange(y_train.shape[0]+y_valid.shape[0],
y_train.shape[0]+y_test.shape[0]+y_test.shape[0]),
y_test[:,ft], color='black', label='test target')
plt.plot(np.arange(y_train_pred.shape[0]),y_train_pred[:,ft], color='red',
label='train prediction')
plt.plot(np.arange(y_train_pred.shape[0], y_train_pred.shape[0]+y_valid_pred.shape[0]),
y_valid_pred[:,ft], color='orange', label='valid prediction')
plt.plot(np.arange(y_train_pred.shape[0]+y_valid_pred.shape[0],
y_train_pred.shape[0]+y_valid_pred.shape[0]+y_test_pred.shape[0]),
y_test_pred[:,ft], color='green', label='test prediction')
plt.title('past and future stock prices')
plt.xlabel('time [days]')
plt.ylabel('normalized price')
plt.legend(loc='best');
plt.subplot(1,2,2);
plt.plot(np.arange(y_train.shape[0], y_train.shape[0]+y_test.shape[0]),
y_test[:,ft], color='black', label='test target')
plt.plot(np.arange(y_train_pred.shape[0], y_train_pred.shape[0]+y_test_pred.shape[0]),
y_test_pred[:,ft], color='green', label='test prediction')
plt.title('future stock prices')
plt.xlabel('time [days]')
plt.ylabel('normalized price')
plt.legend(loc='best');
3、资源下载
数据集: sh300index.csv

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)