
目标检测之小目标检测和遮挡问题
小目标检测trick小目标难检测原因小目标在原图中尺寸比较小,通用目标检测模型中,一般的基础骨干神经网络(VGG系列和Resnet系列)都有几次下采样处理:导致小目标在特征图的尺寸基本上只有个位数的像素大小,导致设计的目标检测分类器对小目标的分类效果差。如果分类和回归操作在经过几层下采样处理的 特征层进行,小目标特征的感受野映射回原图将可能大于小目标在原图的尺寸,造成检测效果差。小目标在原图中的数
小目标难检测原因
小目标在原图中尺寸比较小,通用目标检测模型中,一般的基础骨干神经网络(VGG系列和Resnet系列)都有几次下采样处理:
- 导致小目标在特征图的尺寸基本上只有个位数的像素大小,导致设计的目标检测分类器对小目标的分类效果差。
- 如果分类和回归操作在经过几层下采样处理的 特征层进行,小目标特征的感受野映射回原图将可能大于小目标在原图的尺寸,造成检测效果差。
小目标在原图中的数量较少,检测器提取的特征较少,导致小目标的检测效果差。
神经网络在学习中被大目标主导,小目标在整个学习过程被忽视,导致导致小目标的检测效果差。
Tricks
(1) data-augmentation.简单粗暴,比如将图像放大,利用 image pyramid多尺度检测,最后将检测结果融合.缺点是操作复杂,计算量大,实际情况中不实用;
(2) 特征融合方法:FPN这些,多尺度feature map预测,feature stride可以从更小的开始;
(3)合适的训练方法:CVPR2018的SNIP以及SNIPER;
(4)设置更小更稠密的anchor,回归的好不如预设的好, 设计anchor match strategy等,参考S3FD;
(5)利用GAN将小物体放大再检测,CVPR2018有这样的论文;
(6)利用context信息,建立object和context的联系,比如relation network;
(7)有密集遮挡,如何把location 和Classification 做的更好,参考IoU loss, repulsion loss等.
(8)卷积神经网络设计时尽量采用步长为1,尽可能保留多的目标特征。
(9)matching strategy。对于小物体不设置过于严格的 IoU threshold,或者借鉴 Cascade R-CNN 的思路。
那么,有一个十分简单的方法可以提升小物体的精度,那就是为 bounding box regression 这项损失上,加一个针对于小物体的权重。
以 YOLOv3 为例,默认对于 regression 损失都会上一个
(
2
−
w
×
h
)
(2-w \times h)
(2−w×h) 的损失,w 和 h 分别是ground truth 的宽和高。如果不减去
w
×
h
w\times h
w×h,AP 会有一个明显下降。如果继续往上加,如
(
2
−
w
×
h
)
×
1.5
(2-w\times h)\times1.5
(2−w×h)×1.5,总体的 AP 还会涨一个点左右(包括验证集和测试集)。当然这大概也有 COCO 中小物体实在太多的原因。
有遮挡的目标检测
Repulsion Loss: Detecting Pedestrians in a Crowd-CVPR2018
遮挡情况
目标检测中存在两类遮挡,(1)待检测的目标之间相互遮挡;(2)待检测的目标被干扰物体遮挡。比如下图

具体来说,如果检测任务的目标是汽车和人,那么汽车被人遮挡,而且人被干扰物体(牛)遮挡。因为算法只学习待检测的物体的特征,所以第二种遮挡只能通过增加样本来优化检测效果。
在现实的检测任务中,只有比较特殊的场景需要考虑遮挡问题,比如行人检测、公交车上密集人群检测、牲畜数量计算等
问题描述

如图所示,其中T1,T2为Groundtruth框,而P1,P2,P3为anchors,由于P2中包含了T2的部分区域,所以P2对应的proposals很容易受到T2的干扰,导致回归出来的proposal同时包含了目标T1,T2的部分区域,不精准
假设图中的预测框P1不存在,也即T1对应的proposals只有P2,如果T2对应的max score的proposal近似为P3,那么当P2和P3的IOU大于阈值时,在后处理nms阶段就会把P2过滤掉,从而导致更严重的情况,T1被漏召回了
方案一:repulsion loss
针对不精准和漏召回的情况,使用repulsion loss(斥力损失),类比磁铁的吸引力和排斥力作用
斥力损失的作用是对预测的proposal进行约束,使其不仅要靠近target T(引力作用),还要远离其他的Groundtruth物体B以及B对应的proposals(斥力作用).如果T的Surrounding Groundtruth包含了除B以外的其他目标,则斥力损失会要求预测的proposal远离所有这些目标

具体实现-repulsion loss
论文提出了两个损失函数,RepGT和RepBox,前者用于对proposal向其他目标(gt)偏移的情况进行惩罚,从而实现斥力作用(编号为A),后者用于对proposal向其他目标(gt)对应的proposals靠近的情况进行惩罚,从而实现斥力作用(编号为B),因此检测结果对NMS算法更加鲁棒

为了简化,只考虑了两类的情况,前景和背景,所有前景为同一类别

引力作用
对于指定的anchor
P
∈
P
+
P\in P_+
P∈P+,可以计算它与所有的groundtruth框的IOU,取IOU最大的作为target框
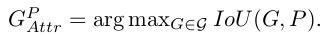
定义
B
P
B^P
BP为anchor P对应的预测框,那么需要满足预测框逼近target框,度量两个框的逼近程度的方式包括欧式距离,smoothL1距离,IOU等,论文中使用了smoothL1距离,并且对于训练集batch中的每一张图,需要考虑所有的anchors,因此表达式如下
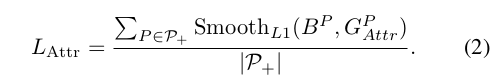
斥力作用A
对于指定的anchor
P
∈
P
+
P\in P_+
P∈P+,可以计算它与所有的groundtruth框的IOU,取IOU第二大的作为target框,公式如下
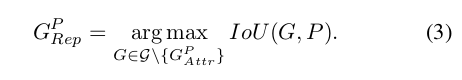
斥力作用A用于对
B
P
B^P
BP逼近
G
R
e
p
P
G_{Rep}^P
GRepP的情况进行惩罚,作者使用了IoG(intersection over Groundtruth)指标来衡量逼近程度,公式如下

斥力作用B
当不同Target对应的预测框太近时,容易出现漏召回的情况,斥力作用B用于将不同Target对应的预测框分离开

对于所有的groundtruth框
G
0
=
G
G^0={G}
G0=G,每个框
G
G
G都对应了一组anchors,那么所有的anchors可以分为
∣
G
0
∣
|G^0|
∣G0∣组
Occlusion-aware R-CNN: Detecting pedestrians in a Crowd-ECCV2018
方案二:Occlusion-aware R-CNN
loss优化
- 所有的预测框逼近对应的target框 closely
- 属于同一target框的多个预测框尽量集中 compactly


网络优化-PORoI
PORoI,全称为“Part Occlusion-aware RoI Pooling Unit”,在Faster RCNN算法中,RPN部分会生成目标的候选区域,如下图中的红色方框所示,ROI Pooling会将该红色区域缩放到固定尺寸,记作m×m,对于行人检测任务,作者考虑到人体具有特殊的结构,为了充分利用这一prior knowledge,从红色候选区域中切分出5个子区域,如图中蓝色的框所示。每一个蓝色框经过ROI Pooling操作后都会变成尺寸为m×m的特征图。
因为这5个子区域可能会有遮挡,图中的“Occlusion process unit”是用来生成对应子区域的“可见度”打分,若该子区域被遮挡,则打分较低,否则打分较高,作者作用用了element-wise sum操作将所有子区域的特征合并,用于最终的分类和定位任务。
笔者认为,该PORoI层存在两处待改进的地方,(1)将人体分成5个子区域是否合理,分成更多的子区域是否会效果更好,作者文中没有贴相关对比;(2)因为不同子区域对应不同的特征,“Eltw sum”操作进行特征融合,破坏了特征的结构性,需要探索更加合理的特征融合方式,使它能结合位置先验信息。

总结
两篇文章都是针对行人检测中的遮挡问题,提出解决办法
第一篇文章仅从优化目标的角度考虑,第二篇文章同时从优化目标和网络结构的角度考虑
两篇文章都是基于Faster RCNN算法框架做优化,且效果基本相当

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)