
树莓派4B部署YOLOv5n[YOLOv5 PyQt5 ONNX]
简单Demo:利用pyqt设计yolov5目标检测GUI界面,使用ONNX框架部署在树莓派4B上运行。
·
文章目录
前言
基于YOLOv5目标检测算法,设计GUI软件,通过ONNX推理框架部署到树莓派上运行。
工程已上传gitee,点击下载即可。
一、树莓派系统环境配置
1.树莓派4B
| 内容 | 参数 |
|---|---|
| 运行内存 | 4GB |
| TF卡 | 64GB |
| 操作系统 | Linux (Raspberry Pi OS with Desktop) |
| 系统位数 | 32位 |
树莓派Linux操作系统可以从树莓派官方或镜像源进行下载,系统烧录过程(略)。
2.树莓派系统环境依赖安装
opencv安装可参考流浪猫博主分享的《超简单教你在树莓派上安装opencv(一)》
numpy、onnxruntime、pyqt5安装使用pip进行安装即可。
pip install numpy / onnxruntime / pyqt5
二、设计GUI界面
1.打开Qtdesigner设计GUI界面
简单Demo:
界面元素:
一个QLabel:用于视频显示
两个pushButton(按钮):打开和关闭摄像头
设计完成后,点击保存,生成ui文件

2.ui文件格式转换
利用PyQt5的PyUIC工具将其ui文件转换成py文件,如下图:

demo1.py:
# -*- coding: utf-8 -*-
# Form implementation generated from reading ui file 'demo1.ui'
#
# Created by: PyQt5 UI code generator 5.15.4
#
# WARNING: Any manual changes made to this file will be lost when pyuic5 is
# run again. Do not edit this file unless you know what you are doing.
from PyQt5 import QtCore, QtGui, QtWidgets
class Ui_MainWindow(object):
def setupUi(self, MainWindow):
MainWindow.setObjectName("MainWindow")
MainWindow.resize(794, 600)
self.centralwidget = QtWidgets.QWidget(MainWindow)
self.centralwidget.setObjectName("centralwidget")
self.horizontalLayout = QtWidgets.QHBoxLayout(self.centralwidget)
self.horizontalLayout.setObjectName("horizontalLayout")
self.verticalLayout = QtWidgets.QVBoxLayout()
self.verticalLayout.setSizeConstraint(QtWidgets.QLayout.SetNoConstraint)
self.verticalLayout.setContentsMargins(10, 0, 10, -1)
self.verticalLayout.setSpacing(7)
self.verticalLayout.setObjectName("verticalLayout")
self.pushButton = QtWidgets.QPushButton(self.centralwidget)
self.pushButton.setObjectName("pushButton")
self.verticalLayout.addWidget(self.pushButton)
self.pushButton_2 = QtWidgets.QPushButton(self.centralwidget)
self.pushButton_2.setObjectName("pushButton_2")
self.verticalLayout.addWidget(self.pushButton_2)
self.horizontalLayout.addLayout(self.verticalLayout)
self.label = QtWidgets.QLabel(self.centralwidget)
self.label.setText("")
self.label.setObjectName("label")
self.horizontalLayout.addWidget(self.label)
self.horizontalLayout.setStretch(0, 2)
self.horizontalLayout.setStretch(1, 5)
MainWindow.setCentralWidget(self.centralwidget)
self.menubar = QtWidgets.QMenuBar(MainWindow)
self.menubar.setGeometry(QtCore.QRect(0, 0, 794, 26))
self.menubar.setObjectName("menubar")
MainWindow.setMenuBar(self.menubar)
self.toolBar = QtWidgets.QToolBar(MainWindow)
self.toolBar.setObjectName("toolBar")
MainWindow.addToolBar(QtCore.Qt.TopToolBarArea, self.toolBar)
self.retranslateUi(MainWindow)
QtCore.QMetaObject.connectSlotsByName(MainWindow)
def retranslateUi(self, MainWindow):
_translate = QtCore.QCoreApplication.translate
MainWindow.setWindowTitle(_translate("MainWindow", "MainWindow"))
self.pushButton.setText(_translate("MainWindow", "打开摄像头"))
self.pushButton_2.setText(_translate("MainWindow", "关闭摄像头"))
self.toolBar.setWindowTitle(_translate("MainWindow", "toolBar"))
3.编写运行代码
demo1_main.py:
# here put the import lib
import math
import sys
from PyQt5 import QtGui, QtWidgets
from general import plot_one_box, infer_img
from demo1 import Ui_MainWindow
import numpy as np
import cv2
# import time
# from random import uniform
from PyQt5.Qt import *
import onnxruntime as ort
class Open_Camera(QtWidgets.QMainWindow, Ui_MainWindow):
def __init__(self):
super(Open_Camera, self).__init__()
self.setupUi(self) # 创建窗体对象
self.setWindowTitle('yolov5目标检测demo')
self.init()
self.openfile_name_model = 'best.onnx' # 模型名称
# self.so = ort.SessionOptions() # 树莓派上保留以下两段代码,注释下面那行代码
# self.net = ort.InferenceSession(self.openfile_name_model, self.so)
# ['TensorrtExecutionProvider', 'CUDAExecutionProvider', 'CPUExecutionProvider']
# CUDAExecutionProvider: GPU推理;
self.net = ort.InferenceSession(self.openfile_name_model,
providers=['CUDAExecutionProvider']) # 在树莓派上这里不需指定推理设备
# 标签字典
self.dic_labels = {0: 'person'}
# 模型参数
self.model_h = 320
self.model_w = 320
def init(self):
# self.label.setScaledContents(True) # 图片自适应
# 定时器让其定时读取显示图片
self.camera_timer = QTimer()
self.camera_timer.timeout.connect(self.show_image)
# 打开摄像头
self.pushButton.clicked.connect(self.open_camera)
# 关闭摄像头
self.pushButton_2.clicked.connect(self.close_camera)
'''开启摄像头'''
def open_camera(self):
self.cap = cv2.VideoCapture(0) # 初始化摄像头
self.camera_timer.start(40) # 每40毫秒读取一次,即刷新率为25帧
self.show_image()
'''关闭摄像头'''
def close_camera(self):
self.cap.release() # 释放摄像头
self.label.clear() # 清除label组件上的图片
self.camera_timer.stop() # 停止读取
'''显示图片'''
def show_image(self):
flag, self.image = self.cap.read() # 从视频流中读取图片
if flag:
# image_show = cv2.resize(self.image, (1280, 720)) # 把读到的帧的大小重新设置为 600*360
image_show = self.image
width, height = image_show.shape[:2] # 行:宽,列:高
# image_show = cv2.cvtColor(image_show, cv2.COLOR_BGR2RGB) # opencv读的通道是BGR,要转成RGB
# image_show = cv2.flip(image_show, 1) # 水平翻转,因为摄像头拍的是镜像的。 用相机不用翻转
# start 图片检测
det_boxes, scores, ids = infer_img(image_show, self.net, self.model_h, self.model_w,
thred_nms=0.5, thred_cond=0.75)
# image_show = self.image
for box, score, id in zip(det_boxes, scores, ids):
label = '%s:%.2f' % (self.dic_labels[id], score)
plot_one_box(box.astype(np.int16), image_show, color=(255, 0, 0), label=label, line_thickness=None)
image_show = cv2.cvtColor(image_show, cv2.COLOR_BGR2RGB) # opencv读的通道是BGR,要转成RGB
# 把读取到的视频数据变成QImage形式(图片数据、高、宽、RGB颜色空间,三个通道各有2**8=256种颜色)
self.showImage = QtGui.QImage(image_show.data, height, width, QImage.Format_RGB888)
self.label.setPixmap(QPixmap.fromImage(self.showImage)) # 往显示视频的Label里显示QImage
self.label.setScaledContents(True) # 图片自适应
if __name__ == '__main__':
app = QtWidgets.QApplication(sys.argv)
ui = Open_Camera()
ui.show()
sys.exit(app.exec_())
general.py:
import numpy as np
import cv2
import random
# 标注目标
def plot_one_box(x, img, color=None, label=None, line_thickness=None):
"""
description: Plots one bounding box on image img,
this function comes from YoLov5 project.
param:
x: a box likes [x1,y1,x2,y2]
img: a opencv image object
color: color to draw rectangle, such as (0,255,0)
label: str
line_thickness: int
return:
no return
"""
tl = (
line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1
) # line/font thickness
color = color or [random.randint(0, 255) for _ in range(3)]
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
if label:
tf = max(tl - 1, 1) # font thickness
t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled
cv2.putText(
img,
label,
(c1[0], c1[1] - 2),
0,
tl / 3,
[225, 255, 255],
thickness=tf,
lineType=cv2.LINE_AA,
)
# 极大值抑制
def post_process_opencv(outputs, model_h, model_w, img_h, img_w, thred_nms, thred_cond):
conf = outputs[:, 4].tolist()
c_x = outputs[:, 0] / model_w * img_w
c_y = outputs[:, 1] / model_h * img_h
w = outputs[:, 2] / model_w * img_w
h = outputs[:, 3] / model_h * img_h
p_cls = outputs[:, 5:]
if len(p_cls.shape) == 1:
p_cls = np.expand_dims(p_cls, 1)
cls_id = np.argmax(p_cls, axis=1)
p_x1 = np.expand_dims(c_x - w / 2, -1)
p_y1 = np.expand_dims(c_y - h / 2, -1)
p_x2 = np.expand_dims(c_x + w / 2, -1)
p_y2 = np.expand_dims(c_y + h / 2, -1)
areas = np.concatenate((p_x1, p_y1, p_x2, p_y2), axis=-1)
areas = areas.tolist()
ids = cv2.dnn.NMSBoxes(areas, conf, thred_cond, thred_nms)
if len(ids) > 0:
return np.array(areas)[ids], np.array(conf)[ids], cls_id[ids]
else:
return [], [], []
# 推理
def infer_img(img0, net, model_h, model_w, thred_nms=0.4, thred_cond=0.5):
# 图像预处理
img = cv2.resize(img0, [model_w, model_h], interpolation=cv2.INTER_AREA) # 缩放
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 格式转换
img = img.astype(np.float32) / 255.0 # 归一化
blob = np.expand_dims(np.transpose(img, (2, 0, 1)), axis=0) # 维度转换
# 模型推理
outs = net.run(None, {net.get_inputs()[0].name: blob})[0].squeeze(axis=0)
# 输出坐标矫正
# outs = cal_outputs(outs, nl, na, model_w, model_h, anchor_grid, stride)
# 检测框计算
img_h, img_w, _ = np.shape(img0)
boxes, confs, ids = post_process_opencv(outs, model_h, model_w, img_h, img_w, thred_nms, thred_cond)
return boxes, confs, ids
4.准备权重文件
下载yolov5n.pt并将其转换成yolov5.onnx,放在工程同目录下。
三、树莓派运行效果
1.将文件传到树莓派

2.修改代码demo1_main.py代码

3.运行代码
在命令行窗口切换到工程文件路径下,运行代码
python demo1_main.py
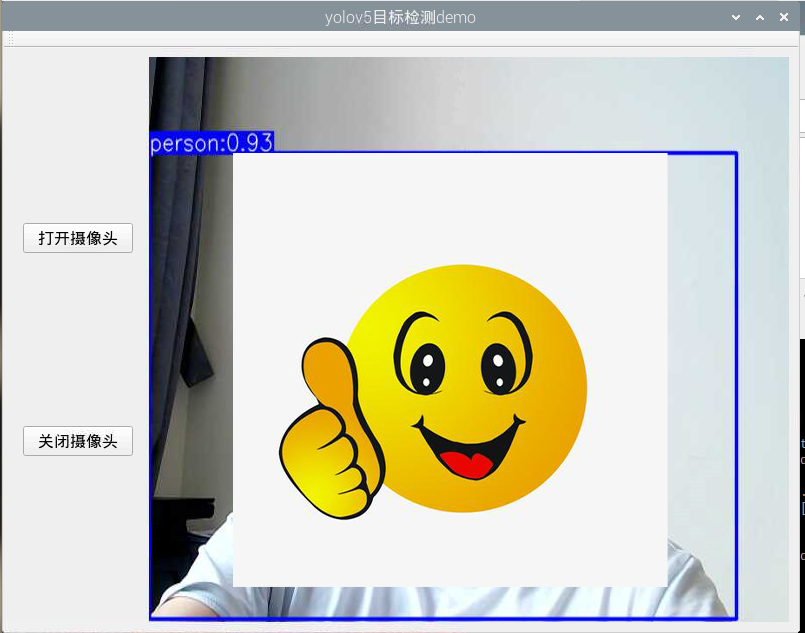
运行效果:

yolov5n模型在树莓派上部署,FPS大约为5-6FPS。
四、UI软件打包
如果你想将qt文件进行打包输出exe,可参考pyqt打包输出exe。
选中demo1_main.py进行输出,应该最后要将general.py改成general.pyc放在输出的exe同路径下。
总结
将YOLOv5通过ONNX推理引擎部署在树莓派上,同时利用PyQt技术设计了简单的GUI界面。(仅个人记录分享)

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)