
【ICLR 2023】 CrossFormer增强多元时间序列建模能力
一篇ICLR2023中,和Transformer做时间序列相关的论文。这篇文章提出了CrossFrormer,用来解决多元时间序列问题。CrossFromer主要的切入点在于,之前的Transformer更多的考虑是如何通过时间维度attention建立时序上的关系,而缺少面对多元时间序列预测时,对不同变量关系之间的刻画。这篇文章填补了这个空白,提出了时间维度、变量维度两阶段attention,尤
一篇ICLR2023中,和Transformer做时间序列相关的论文。这篇文章提出了CrossFrormer,用来解决多元时间序列问题。CrossFromer主要的切入点在于,之前的Transformer更多的考虑是如何通过时间维度attention建立时序上的关系,而缺少面对多元时间序列预测时,对不同变量关系之间的刻画。这篇文章填补了这个空白,提出了时间维度、变量维度两阶段attention,尤其是在变量维度,提出了一种高效的路由attention机制。

论文标题:CROSSFORMER: TRANSFORMER UTILIZING CROSSDIMENSION DEPENDENCY FOR MULTIVARIATE TIME SERIES FORECASTING
下载地址:https://openreview.net/pdf?id=vSVLM2j9eie
1
Motivation
之前用Transformer解决时间序列问题的工作,大多集中在如何更合理的进行时间维度的关系建模上。利用时间维度的自注意力机制,建立不同时间步之间的关系。
而在多元时间序列预测中,各个变量之间的关系也很重要。之前的解法,主要是将每个时间步的多元变量压缩成一个embedding(如下图中的b),再进行时间维度的attention。这种方法的问题是缺少对不同变量之间关系的建模。因为时间序列不同变量的含义是不同的,每个变量应该在哪个时间片段进行对齐无法提前预知,直接每个时间步融合的方式显然太粗糙了。

基于以上考虑,本文对Transformer在多元时间序列预测的应用中进行了改造,将多元时间序列转换成patch,增加了变量维度之间的attention(如上图中的c),并考虑到效率问题,提出了基于路由的变量间attention机制。
2
模型结构概览
模型整体包含3个主要模块:
Dimension-Segment-Wise Embedding:这个模块的主要目标是将时间序列分成patch形式,得到patch embedding,作为后续模型的输入,将每个变量的时间序列按照一定的窗口与划分成多个区块,每个区块通过全连接进行映射,本文不再详细介绍;
Two-Stage Attention Layer:两阶段的attention,第一阶段在时间维度进行attention,第二阶段在多变量之间进行attention;
Hierarchical Encoder-Decoder:采用不同的patch尺寸和划分方式,形成层次的编码和解码结构。
3
两阶段Attention机制
两阶段Attention指的是时间维度attention和空间维度attention。输入先过一层时间维度attention,独立的进行每个序列时序上的建模;然后徐再输入到一层空间维度attention,对齐不同变量各个时间步的编码,这部分也是本文的核心点。
时间维度attention就是正常的Transformer模型,每个变量的时间序列转换成patch后,输入到Transformer中,输出self-attention后每个变量每个patch的表示,由于在上篇文章Transformer在时间序列预测中不如线性模型?ICLR 2023最新回应来了!也详细介绍过这种建模方式了,这里不再详细介绍。
空间维度的attention,指的是对齐不同变量的各个时间步。如下图,空间维度的对齐,目的是在变量之间寻找两两时间步的关系,这样能深入刻画一个变量对另一个变量的影响。具体的做法为,在变量维度做self-attention,如下面的图b。
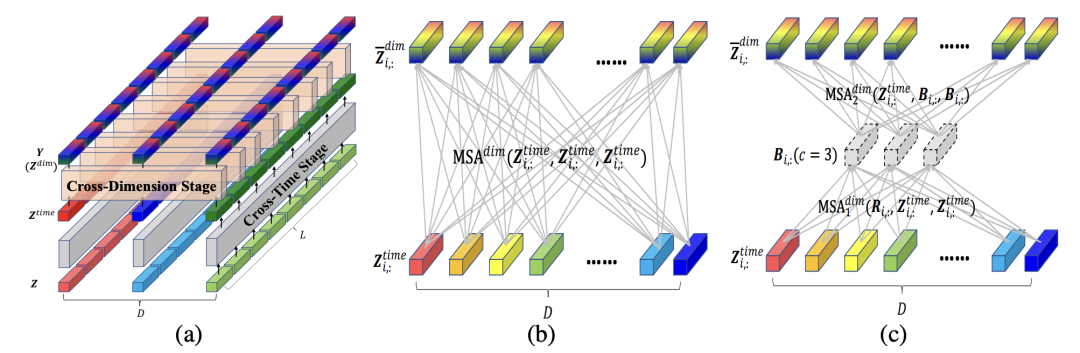
但是这种歌做法会导致运算复杂度较高,因此本文提出了使用路由的方式,增加几个中间向量,将变量各个时间步的信息先利用一层attention汇聚到中间向量上,再利用中间向量和原序列做self-attention,中间向量可以看成是一种路由,也有点像胶囊网络的思路,先对输入信息做个聚类,再进一步分发,起到了降低运算量的作用。上图的图c为示意图,具体的计算公式如下:
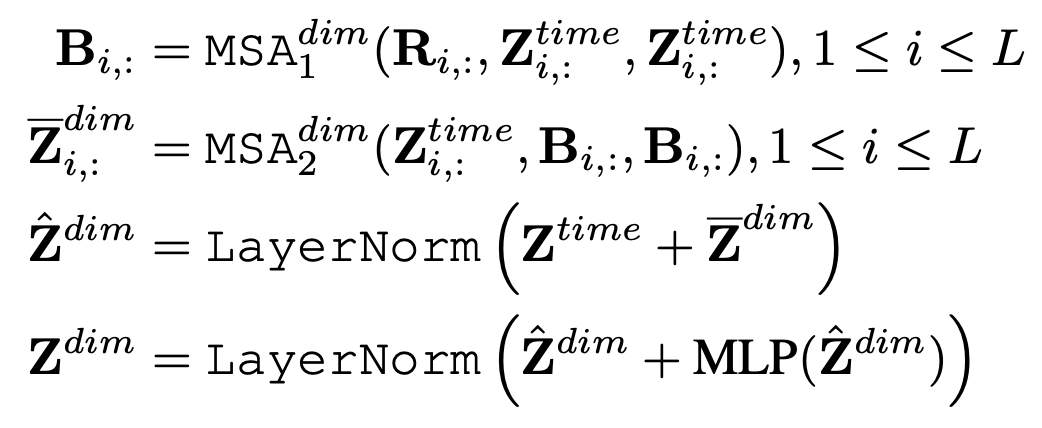
其中,R是中间向量,B是序列和中间向量进行self-attention后的结果,这个结果会和序列再次做self-attention,得到最终的变量间信息交互的编码结果。
4
层次Encoder-Decoder
本文提出的层次Encoder-Decoder架构图下图所示,它基于上面提到的两阶段attention网络,对输入进行了不同尺寸的patch生成。例如下面图中,序列从上到下被分成了2个、4个、8个等不同的patch,每层的每个patch所包含的窗口长度不同。模型的输入最开始是细粒度patch,随着层数增加逐渐聚合成更粗粒度的patch。这种形式可以让模型从不同的粒度提取信息,也有点像空洞卷积的架构。Decoder会利用不同层次的编码进行预测,各层的预测结果加和到一起,得到最终的预测结果。

5
实验结果
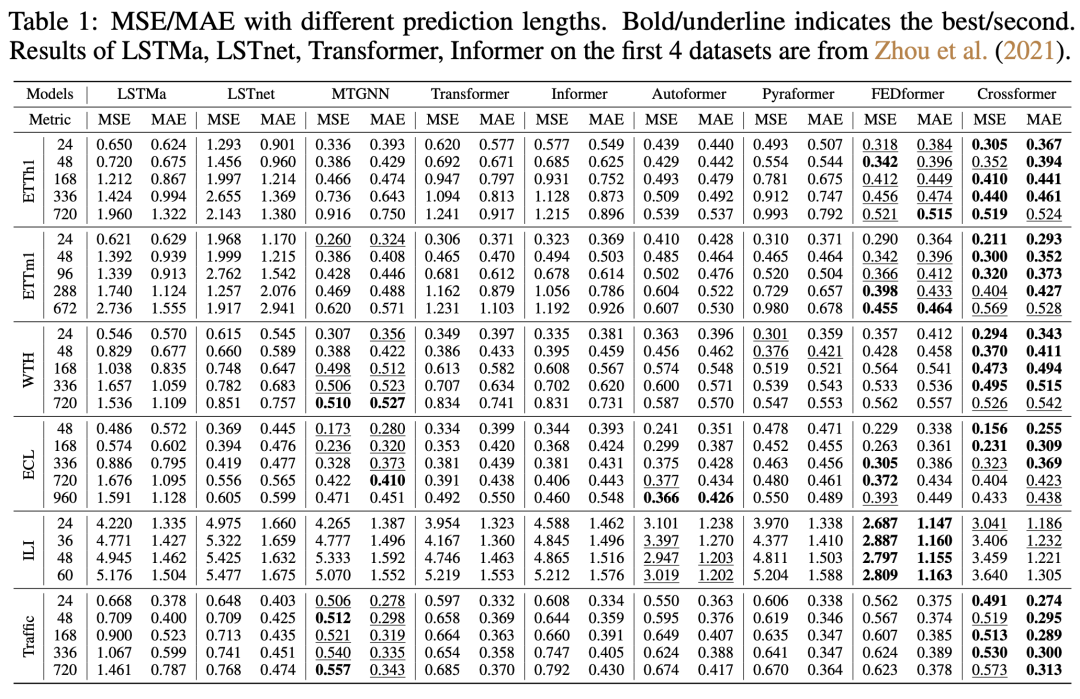
本文的实验主要对比了各个数据集不同时间窗口的预测效果,CrossFormer在多个数据集上取得了sota效果。
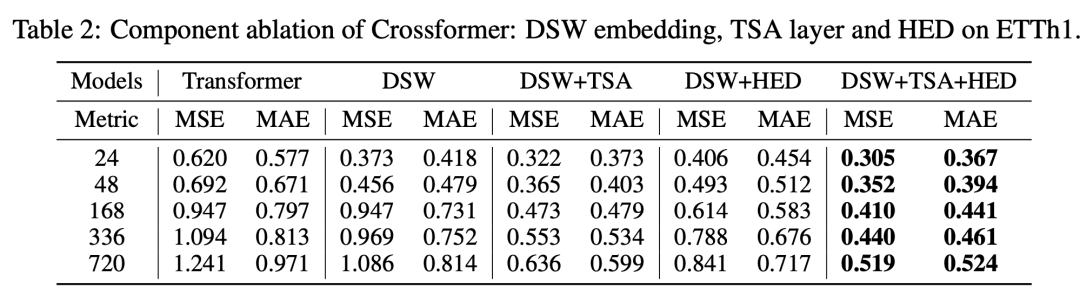
文中也进行了消融实验,对比各个模块(DSW对应patch编码,TSA对应2阶段attention,HED对应层次Encoder-Decoder)是否引入的效果差异,如下表。可以看到,相比最初的Transformer建模,DSW、TSA、HED各个模块都会给模型效果带来显著的提升。
从最近的几篇ICLR 2023时间序列预测文章中,我们也可以看出,patch+transformer的架构,逐渐成为新的深度时间序列预测模型的最优范式。这样一来,时间序列和NLP、CV领域的Transformer形成了大统一。
推荐阅读:
我的2022届互联网校招分享
我的2021总结
浅谈算法岗和开发岗的区别
互联网校招研发薪资汇总
2022届互联网求职现状,金9银10快变成铜9铁10!!
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步
发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书
瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 10
10 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)