【数学建模笔记】【第十讲(2)】聚类模型之:系统(层次)聚类及spss实现
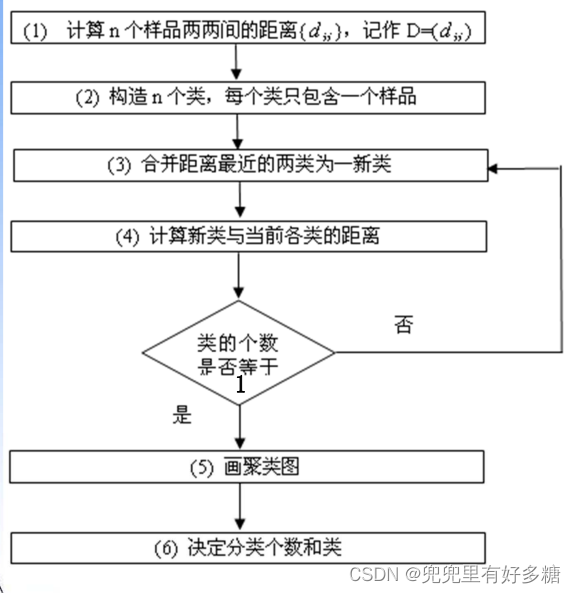
系统聚类的合并算法通过计算两类数据点间的距离,对最为接近的两类数据点进行组合,并反复迭代这一过程,直到将所有数据点合成一类,并生成聚类谱系图。我们可以根据这个图来确定聚类的个数。系统(层次)聚类的算法流程:将每个对象看作一类,计算两两之间的最小距离;将距离最小的两个类合并成一个新类;重新计算新类与所有类之间的距离;重复二三两步,直到所有类最后合并成一类;结束。【举例说明】对上面这一组数据进行聚类分
系统(层次)聚类解决了K-均值聚类的一个最大的问题:聚类的个数需要自己给定。
一、系统聚类的定义
系统聚类的合并算法通过计算两类数据点间的距离,对最为接近的两类数据点进行组合,并反复迭代这一过程,直到将所有数据 点合成一类,并生成聚类谱系图。我们可以根据这个图来确定聚类的个数。

二、具体步骤介绍:

系统(层次)聚类的算法流程:
-
将每个对象看作一类,计算两两之间的最小距离;
-
将距离最小的两个类合并成一个新类;
-
重新计算新类与所有类之间的距离;
-
重复二三两步,直到所有类最后合并成一类;
-
结束。
【举例说明】

对上面这一组数据进行聚类分析:

横坐标为学生的物理成绩,纵坐标为学生的数学成绩,可以绘制成一个二维坐标图。
首先要计算每一个样本点之间的距离。看那两个点之间的距离最小,可以算作一个聚类。
比如最右上角的两个点距离最小,则把他们归为一个聚类。
以此类推,当所有样本都已经被归为聚类之后再计算各个聚类之间的距离。距离近的再次归为一个聚类。直到只剩下一个聚类为止。
上面描述了两种距离:一个是样本与样本之间的距离,一种是聚类之间的距离。这两种距离都有多种定义方式,我们在实际运用时可以是具体情况而定。
三、样本与样本之间的距离




四、类与类之间的常用距离:

1.最短距离法

2.最长距离法:

3、组间平均连接法:

4.组内平均连接法:

5.重心法:

五、举例说明:
根据五个学生的六门课的成绩,对这五个学生进行分类

1.写出样品间的距离矩阵(以欧氏距离为例)

横着的分别是:G1,G2,G3,G4,G5.
所以这个矩阵里的每一个数字表示Gi与Gj的距离。由于与自己的距离是0,所以斜着的一列是0。
在最初每一个样本就可以视作一个类。
2.将每一个样品看做是一个类,观察D(G1,G5)=15.8最小,故将G1与G5合为一类,名为G6。计算新类与其余各类之间的距离,得到新的距离矩阵D1。(这里以最短距离法为例)


3.观察D(G2,G4)=15.9最小,故将G2和G4聚为一类,记为G7。计算新类与其余各类之间的距离,得到新的距离矩阵D2。(这里以最短距离法为例)


4.观察D(G6,G7)=18.2最小,故将G和G7聚为一类,记为G8。计算新类与其余各类之间的距离,得到新的距离矩阵D3。(这里以最短距离法为例)

5.最后将G8与G3聚为一类,记为G9。
聚类的系谱图:

六、系统聚类分析需要注意的问题:
- 对于一个实际问题要根据分类的目的来选取指标,指标选取的不同分类结果一般也不同。
- 样品间距离定义方式的不同,聚类结果一般也不同。
- 聚类方法的不同,聚类结果一般也不同(尤其是样品特别多的时候)。最好能通过各种方法找出其中的共性。
- 要注意指标的量纲,量纲差别太大会导致聚类结果不合理。
- 聚类分析的结果可能不令人满意,因为我们所做的是一个数学的处理,对于结果我们要找到一个合理的解释
七、系统聚类法的spss实现:
仍然是上一节所用的数据:

选择系统聚类:

”绘制“选项中勾选”树状图“可以生成聚类分析之后的谱系图:

”方法“栏中就是可以自由选择刚刚介绍的那几种距离的表示方式:
一般选择默认的方式就可以。
如果各个变量的单位不统一,则可以选择左下方的标准化,选择”Z得分“标准化。由于我们这组数据单位是统一的,所以不用进行这一步。

点击确认之后会得出具体的结果:
以下是聚类谱系图:

根据此图我们可以发现,在逐步迭代过程中,31个省份构成更少的聚类,逐步循环,最后变为一个。
我们可以根据这张图选择更易于解释的聚类个数。
下图的”系数“一栏表示的是肘部法则中的聚合系数。

到这里还是需要我们自己选择聚类的个数,只不过不像K-均值算法那样再数据分析之前就必须得给出聚类个数了。那么有没有一种法则可以帮助我i们确定到底应该分为几个聚类呢?
八、肘部法则确定聚类数目
肘部法则(Elbow Method):通过图形大致的估计出最优的聚类数量。

畸变成都就是衡量各个点到聚类的中心的距离的一个标准。这个距离越大,则畸变程度越大。我们可以想到,当聚类数目无限多,趋于样本个数时,这时每一个样本就是一个单独的聚类,也就是每一个聚类中只有一个样本。那么畸变程度就是0了。而当聚类数目极小时,畸变程度又会很大。所以畸变程度是一个随着聚类数目的增大而减小的这么一个指标。所有类的畸变程度定义为聚合系数。所以当我们把每一个聚合系数算出来,然后作图时,发现聚合系数突然变化缓慢的那个点处,就是比较理想的聚类个数所在位置。

如何绘制肘部法则的图呢?
找到上表中的聚合系数,复制到exel表格中。然后降序排列。

之后点击“插入图表”中的散点图:

改变标度之后可以得到这样一张图:

根据此图,我们可以确定选择3或者5作为聚类数目(至于原因,可以根据此图以及数据在论文中做更详细的说明)。
【解释举例如下】
根据图来进行解释:
- 根据聚合系数折线图可知,当类别数为5时, 折线的下降趋势趋缓,故可将类别数设定为5.
- 从图中可以看出, K值从1到5时,畸变程 度变化最大。超过5以后,畸变程度变化显著 降低。因此肘部就是 K=5,故可将类别数设定
为5.(当然,K=3也可以解释)
那么确定了聚类数目之后我们如何画出直观的分类图像呢?
九、作图
注意:只要当指标个数为2或者3的时候才能画图,实际上本例中指标个数有8个,是不可能做出这样的图的。
所以我们就以本例的两列及三列指标为例作图:
先将聚类个数设置为3,得到聚类分类:

可以看到此时每一个省份后面已经出现聚类的分类了:

我们选择“食品”和“衣着“两列数据进行画图:
选中“食品”和“衣着“两列数据后点击图形构建程序。

如果只有二维的数据则选择第一行的第二种图像,如果有三维数据则选择第一行的第四个图像。
选中后将其拖到中间区域。
分别将“食品”和“衣着“拖动至横坐标和纵坐标。
将”案例的类别号“拖动至右上角”颜色设置“区域,以表示根据不同的聚类类别,会绘制不同颜色的点。

然后点击”组/点 ID“,勾选”指定ID标签“,将”省份“拖动至
上方的”点ID“区域。,这样就会在每个点旁边标注出点对应的省份。

最终我们得到这样的一张图:

我们可以根据自己的喜好再改变其颜色和呈现形式。但具体的信息已经表现得很好了。
同样的可以画出三维数据分析图:


开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐


 36
36 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)