
使用TensorRT部署你的神经网络(2)
TensorRT提供了两种方式进行网络的部署:1. 各种parser对网络模型进行解析与转换;2. 利用TensorRT的api,Layer By Layer的方式进行模型的构建和转换。本文主要介绍如何利用TensorRT的ONNXParser对PyTorch等框架训练的模型进行部署,github上有很多类似的工作,这里以下面这个仓库为例进行介绍。Syencil/tensorRTgithub.c
TensorRT提供了两种方式进行网络的部署:1. 各种parser对网络模型进行解析与转换;2. 利用TensorRT的api,Layer By Layer的方式进行模型的构建和转换。
本文主要介绍如何利用TensorRT的ONNXParser对PyTorch等框架训练的模型进行部署,github上有很多类似的工作,这里以下面这个仓库为例进行介绍。

另一种方法,可以参考另一篇文章的介绍。

1. 代码总览
本仓库主要通过onnx->trt进行部署,并且将所有的网络实现封装成动态库,用起来比较方便。对FP32,FP16以及int8的量化实现全面,同时对前后处理使用多线程,提升了处理速度,很赞。目前实现了对yolo系列、FCOS以及文本检测网络PSENet等的支持。代码逻辑结构清晰易懂,非常推荐学习使用。
- 代码结构比较简单,大概是这个样子的。

- 各个类的关系如下所示
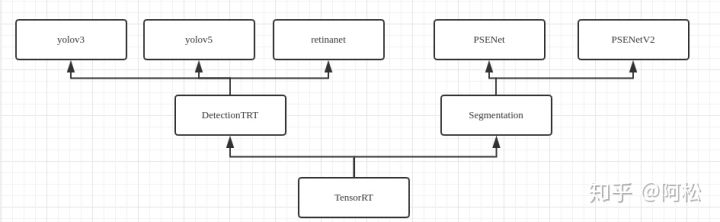
可以看到,TensorRT基类派生出来DetectionTRT和Segmentation两个类,各自派生出来很多的网络实现,如检测网络yolo以及分割网络psenet等等。
2. 代码剖析
我们就以yolov3来一探究竟吧。
sample中的yolov3是基于TensorFlow的实现(都2020年了还有人用TensorFlow?提交的记录非常有意思,大家感受一下,hhh)。
关于TF转ONNX的过程就不赘述了,我们直接看代码,yolov3头文件如下:
class Yolov3 : private DetectionTRT{
private:
void postProcessParall(unsigned long start, unsigned long length, float postThres, const float *origin_output, std::vector<common::Bbox> *bboxes);
inline void safePushBack(std::vector<common::Bbox> *bboxes, common::Bbox *bbox);
public:
//! Initializing
Yolov3(common::InputParams inputParams, common::TrtParams trtParams, common::DetectParams yoloParams);
//! Read images into buffer
std::vector<float> preProcess(const std::vector<cv::Mat> &images) override;
//! Infer
float infer(const std::vector<std::vector<float>>&InputDatas, common::BufferManager &bufferManager, cudaStream_t stream=nullptr) const override;
//! Post Process for Yolov3
std::vector<common::Bbox> postProcess(common::BufferManager &bufferManager, float postThres=-1, float nmsThres=-1) override;
//! Transform
void transform(const int &ih, const int &iw, const int &oh, const int &ow, std::vector<common::Bbox> &bboxes, bool is_padding) override ;
//! Init Inference Session
bool initSession(int initOrder) override;
//! Pred One Image
std::vector<common::Bbox> predOneImage(const cv::Mat &image, float postThres=-1, float nmsThres=-1) override ;
};
非常简洁,所有参数通过自定义的params结构体进行传递,包括网络构建有关的TrtParams,输入有关的InputParams以及输出有关的DetectionParams等。网络继承于DetectionTRT基类,整个推理流程封装到了preProcess(),infer(),postProcess()等函数中,并通过predOneImage()函数进行调用。打开cpp文件可以发现,前处理preProcess以及infer代码都是使用基类的实现,仅仅postProcess部分需要单独实现(这也和网络的输入形式都一致有关,但是针对不同的网络单独实现preProcess()方法也不是很复杂)。另外initSession()函数是对网络的加载方式进行了简单的封装,选择是使用ONNX模型进行转换生成engine还是反序列化的方式得到engine。
来看一下engine的生成方法,ONNX model生成engine的方法在TensorRT的constructNetwork()中实现,是按照TensorRT的官方sample中的固定套路实现的。主要包括:builder的构建,INetworkDefinition的构建,IBuilderConfig的构建,ONNXParser的构建,利用ONNXParser填充INetworkDefinition,以及最后builder使用INetworkDefinition构建出ICudaEngine等步骤。
auto builder = UniquePtr<nvinfer1::IBuilder>(nvinfer1::createInferBuilder(gLogger.getTRTLogger()));
if (!builder){
gLogError << "Create Builder Failed" << std::endl;
return false;
}
const auto explicitBatch = 1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
auto network = UniquePtr<nvinfer1::INetworkDefinition>(builder->createNetworkV2(explicitBatch));
if (!network){
gLogError << "Create Network Failed" << std::endl;
return false;
}
auto config = UniquePtr<nvinfer1::IBuilderConfig>(builder->createBuilderConfig());
if (!config){
gLogError << "Create Config Failed" << std::endl;
return false;
}
auto parser = UniquePtr<nvonnxparser::IParser>(nvonnxparser::createParser(*network, gLogger.getTRTLogger()));
if (!parser){
gLogError << "Create Parser Failed" << std::endl;
return false;
}
if (!parser->parseFromFile(onnxPath.c_str(), static_cast<int>(gLogger.getReportableSeverity()))){
gLogError << "Parsing File Failed" << std::endl;
return false;
}
builder->setMaxBatchSize(mInputParams.BatchSize);
config->setMaxWorkspaceSize(mTrtParams.ExtraWorkSpace);
if (mTrtParams.FP16){
if(!builder->platformHasFastFp16()){
gLogWarning << "Platform has not fast Fp16! It will still using Fp32!"<< std::endl;
}else{
config -> setFlag(nvinfer1::BuilderFlag::kFP16);
}
}
if (mTrtParams.Int8){
if(!builder->platformHasFastInt8()){
gLogWarning << "Platform has not fast Fp16! It will still using Fp32!"<< std::endl;
}else{
config->setAvgTimingIterations(mTrtParams.AvgTimingIteration);
config->setMinTimingIterations(mTrtParams.MinTimingIteration);
config -> setFlag(nvinfer1::BuilderFlag ::kINT8);
std::shared_ptr<EntropyCalibratorV2*> calibrator = std::make_shared<EntropyCalibratorV2*>(new EntropyCalibratorV2(mInputParams, mTrtParams)) ;
config->setInt8Calibrator(*calibrator.get());
}
}
mCudaEngine = std::shared_ptr<nvinfer1::ICudaEngine>(builder->buildEngineWithConfig(*network, *config),common::InferDeleter());
if (!mCudaEngine){
gLogError << "Create Engine Failed" << std::endl;
return false;
}
mContext = UniquePtr<nvinfer1::IExecutionContext>(mCudaEngine->createExecutionContext());
if(!mContext){
gLogError << "Create Context Failed" << std::endl;
return false;
}
assert(network->getNbInputs()==mInputParams.InputTensorNames.size());
assert(network->getNbOutputs()==mInputParams.OutputTensorNames.size());
return true;
不过TensorRT7已经原生支持upsample了,yololayer在推理过程中就是进行的bbox的组装,在此将yololayer中的bbox参数中求exp以及sigmoid部分放到了网络中实现,bbox的拼装部分转移到了postProcess()函数中实现,而在Yolov5中,最后层中所有的操作都放在了postProcess()函数中实现,所以ONNXParser的方法也没有遇到过多关于不支持的问题。
3. 小结
对比过使用TensorRT的API来逐层够来构建网络的流程后,才明白ONNXParser有多方便,代码也可以精简非常多,面对新模型开发调试流程也能大幅加快。并且作者的代码结构清晰,前后处理中多线程的使用,都值得学习。
不过,TensorRT本身也不是十全十美,难免会遇到不支持的网络层的问题,这在这个代码库中并没有涉及,有需要的同学可能还需要参考更多的代码进行学习。

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)