
Python爬虫学习——开始一个小爬虫(一)
Python爬虫学习文章目录Python爬虫学习前言一、什么是爬虫爬虫的矛与盾二、开启一个小爬虫1、导入urlopen包2、打开一个网址,得到响应3、解码4、保存到文件5、打开前言写项目书找资料实在头大,还有训练模型采集图片更让人头大,同样也是复习一下自己的python,于是便开启了Python爬虫之旅,为了自己以后查找资料能更加方便一、什么是爬虫网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF
Python爬虫学习
前言
写项目书找资料实在头大,还有训练模型采集图片更让人头大,同样也是复习一下自己的python,于是便开启了Python爬虫之旅,为了自己以后查找资料能更加方便
一、什么是爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
爬虫就是一段代码,从网络上自动寻找一些自己需要的资料,就比如我想搜一些资料,自己铺天盖地得搜,使用爬虫可以通过关键字筛选我们需要的。或者你想看评分很高得电影,这个时候你也可以用爬虫,找到一些评分很高得电影。
爬虫的矛与盾
1、反爬机制
2、反反爬策略
3、robots.txt(君子协议)
二、开启一个小爬虫
使用软件Pycharm
爬虫:通过编写程序来获取互联网资源
需求:用程序模拟浏览器。输入一个网址,从该网址中获得资源或者内容
1、导入urlopen包
from urllib.request import urlopen
2、打开一个网址,得到响应
from urllib.request import urlopen #导入urlopen
url = "http://www.baidu.com/" #要爬取的网址
resp = urlopen(url) #打开网址并返回响应
print(resp.read()) #打印信息

最前面有个b’,这个意思是字节,我们需要将字节转字符串
3、解码
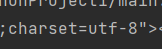
看charest等号后面的内容,通过resp.read.decode()进行解码
from urllib.request import urlopen #导入urlopen
url = "http://www.baidu.com/" #要爬取的网址
resp = urlopen(url) #打开网址并返回响应
print(resp.read().decode("utf-8")) #打印解码信息

4、保存到文件
from urllib.request import urlopen #导入urlopen
url = "http://www.baidu.com/" #要爬取的网址
resp = urlopen(url) #打开网址并返回响应
with open("mybaidu.html",mode="w",encoding='utf-8') as f: #创建html文件并保存 ,encoding设置编码
f.write(resp.read().decode("utf-8")) #读取网页的页面源代码
print("文件保存完成")
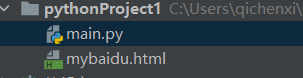

这个时候信息就保存在了html文件中了
5、打开

这个时候就会打开百度。

上面是我们搜索打开百度的网址,下面的网址很明显是不一样的

其本质是相同的,可以查看网页页面源代码,你会发现源代码是相同的,上面也有提到
f.write(resp.read().decode("utf-8")) #读取网页的页面源代码
同样也可以对央视频进行爬取
from urllib.request import urlopen #导入urlopen
url = "http://v.cctv.com/" #要爬取的网址
resp = urlopen(url) #打开网址并返回响应
#print(resp.read().decode("utf-8"))
with open("my2.html",mode="w",encoding='utf-8') as f: #创建html文件并保存 ,encoding设置编码
f.write(resp.read().decode("utf-8")) #读取网页的页面源代码
print("文件保存完成")


瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 1
1 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)