

千万级中文公开免费聊天语料数据分享
分享一个包含千万级聊天语料的资源。地址:https://github.com/codemayq/chaotbot_corpus_Chinese该库是对目前市面上已有的开源中文聊天语料的搜集和系统化整理工作该库搜集了包含·chatterbot·豆瓣多轮·PTT八卦语料·青云语料·电视剧对白语料·贴吧论坛回帖语料·微博语...
分享一个包含千万级聊天语料的资源。地址:https://github.com/codemayq/chaotbot_corpus_Chinese
该库是对目前市面上已有的开源中文聊天语料的搜集和系统化整理工作
该库搜集了包含
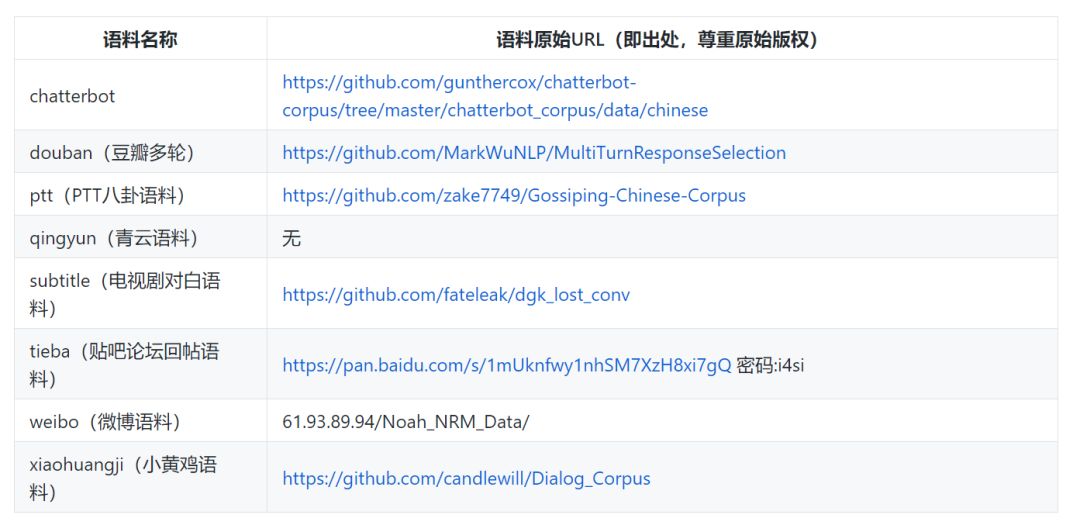
· chatterbot
· 豆瓣多轮
· PTT八卦语料
· 青云语料
· 电视剧对白语料
· 贴吧论坛回帖语料
· 微博语料
· 小黄鸡语料
共8个公开闲聊常用语料和短信,白鹭时代问答等语料。
并对8个常见语料的数据进行了统一化规整和处理,达到直接可以粗略使用的目的。
使用该项目,即可对所有的聊天语料进行一次性的处理和统一下载,不需要到处自己去搜集下载和分别处理各种不同的格式。
注意
以下所有语料都已经统一下载好,存在 https://pan.baidu.com/s/1szmNZQrwh9y994uO8DFL_A 提取码:f2ex 中。给出的语料原链接是为了说明该语料的原始出处是在哪里
环境
python3
处理过程
将各个来源的语料按照其原格式进行提取,提取后进行繁体字转换,然后统一变成一轮一轮的对话。
数据来源及说明

使用方法
下载语料 https://pan.baidu.com/s/1szmNZQrwh9y994uO8DFL_A 提取码:f2ex
将解压后的raw_chat_corpus文件夹放到当前目录下 目录结构为
raw_chat_corpus
-- language
-- process_pipelines
-- raw_chat_corpus
---- chatterbot-1k
---- douban-multiturn-100w
---- ....
-- main.py
-- ...
执行命令即可
python main.py
或者
python3 main.py
生成结果
每个来源的语料分别生成一个独立的*.tsv文件,都放在新生成的clean_chat_corpus文件夹下。
生成结果格式为 tsv格式,每行是一个样本,先是query,再是answer
query \t answer
结果的使用
这个就根据每个人不同的情况自主使用即可。
往期精品内容推荐
Tensorflow官方视频课程-深度学习工具 TensorFlow入门
斯坦福NLP组-2019-《CS224n: NLP与深度学习》-分享
DeepMind-1123-深度学习与强化学习高阶课程分享(带中英文字幕)
UC Berkeley-18-最新深度强化学习课程(中英字幕)
吴恩达-中文完整版《Mechine Learning Yearning》分享

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 0
0 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)