
分布式处理框架 MapReduce
源于Google的MapReduce论文(2004年12月)Hadoop的MapReduce是Google论文的开源实现MapReduce优点: 海量数据离线处理&易开发MapReduce缺点: 实时流式计算。
·
3.2.1 什么是MapReduce
- 源于Google的MapReduce论文(2004年12月)
- Hadoop的MapReduce是Google论文的开源实现
- MapReduce优点: 海量数据离线处理&易开发
- MapReduce缺点: 实时流式计算
3.2.2 MapReduce编程模型
-
MapReduce分而治之的思想
- 数钱实例:一堆钞票,各种面值分别是多少
- 单点策略
- 一个人数所有的钞票,数出各种面值有多少张
- 分治策略
- 每个人分得一堆钞票,数出各种面值有多少张
- 汇总,每个人负责统计一种面值
- 解决数据可以切割进行计算的应用
- 单点策略
- 数钱实例:一堆钞票,各种面值分别是多少
-
MapReduce编程分Map和Reduce阶段
- 将作业拆分成Map阶段和Reduce阶段
- Map阶段 Map Tasks 分:把复杂的问题分解为若干"简单的任务"
- Reduce阶段: Reduce Tasks 合:reduce
-
MapReduce编程执行步骤
- 准备MapReduce的输入数据
- 准备Mapper数据
- Shuffle
- Reduce处理
- 结果输出
-
编程模型
-
借鉴函数式编程方式
-
用户只需要实现两个函数接口:
-
Map(in_key,in_value)
—>(out_key,intermediate_value) list
-
Reduce(out_key,intermediate_value) list
—>out_value list
-
-
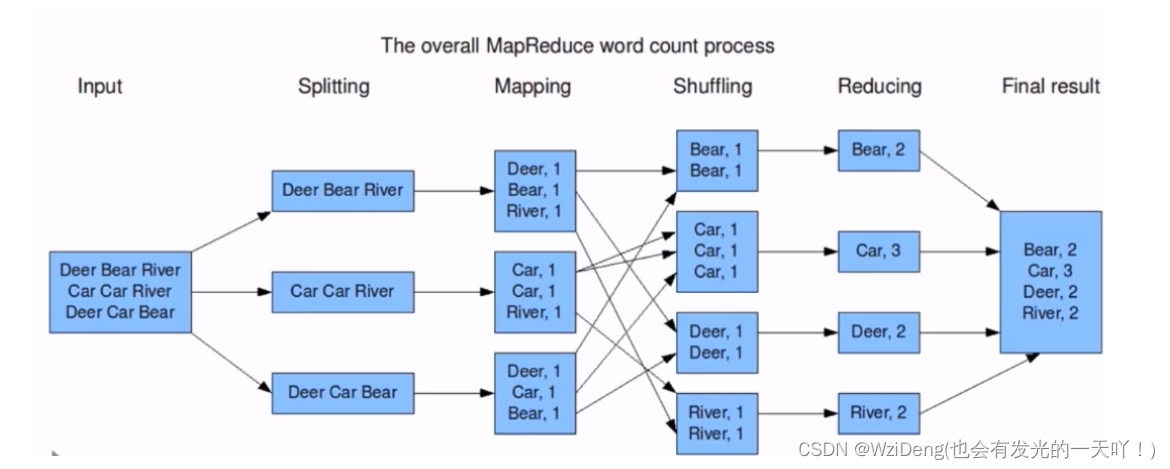
Word Count 词频统计案例
-
3.2.3 Hadoop Streaming 实现wordcount (实验 了解)
-
Mapper
import sys #输入为标准输入stdin for line in sys.stdin: #删除开头和结尾的空行 line = line.strip() #以默认空格分隔单词到words列表 words = line.split() for word in words: #输出所有单词,格式为“单词 1”以便作为Reduce的输入 print("%s %s"%(word,1)) -
Reducer
import sys current_word = None current_count = 0 word = None #获取标准输入,即mapper.py的标准输出 for line in sys.stdin: #删除开头和结尾的空行 line = line.strip() #解析mapper.py输出作为程序的输入,以tab作为分隔符 word,count = line.split() #转换count从字符型到整型 try: count = int(count) except ValueError: #count非数字时,忽略此行 continue #要求mapper.py的输出做排序(sort)操作,以便对连续的word做判断 if current_word == word: current_count += count else : #出现了一个新词 #输出当前word统计结果到标准输出 if current_word : print('%s\t%s' % (current_word,current_count)) #开始对新词的统计 current_count = count current_word = word #输出最后一个word统计 if current_word == word: print("%s\t%s"% (current_word,current_count))cat xxx.txt|python3 map.py|sort|python3 red.py
得到最终的输出
注:hadoop-streaming会主动将map的输出数据进行字典排序
-
通过Hadoop Streaming 提交作业到Hadoop集群
STREAM_JAR_PATH="/root/bigdata/hadoop/share/hadoop/tools/lib/hadoop-streaming-2.9.1.jar" # hadoop streaming jar包所在位置 INPUT_FILE_PATH_1="/The_Man_of_Property.txt" #要进行词频统计的文档在hdfs中的路径 OUTPUT_PATH="/output" #MR作业后结果的存放路径 hadoop fs -rm -r -skipTrash $OUTPUT_PATH # 输出路径如果之前存在 先删掉否则会报错 hadoop jar $STREAM_JAR_PATH \ -input $INPUT_FILE_PATH_1 \ # 指定输入文件位置 -output $OUTPUT_PATH \ #指定输出结果位置 -mapper "python map.py" \ #指定mapper执行的程序 -reducer "python red.py" \ # 指定reduce阶段执行的程序 -file ./map.py \ # 通过-file 把python源文件分发到集群的每一台机器上 -file ./red.py -
到Hadoop集群查看运行结果
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OMnyEJQr-1687851131672)(/img/mr_result.png)]](https://img-blog.csdnimg.cn/ed479ddbbc3d40198e1a48a651fc7837.png)

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)