
牛津大学|“不变信息聚类” :Invariant Information Clustering
code: https://github.com/xu-ji/IICpaper: https://arxiv.org/abs/1807.06653人类是如此擅长“无监督”,以至于我们经常用肤浅的认知作出荒谬的结论。人类擅长“无监督”,往往是因为“滥用”过往的经验妄下结论; 而AI模型的“无监督”,是对数据“妄下”的结论。自从有了深度网络的“大锤”,曾经传统聚类的钉子(k-means, 谱聚类等)似
code: https://github.com/xu-ji/IIC
paper: https://arxiv.org/abs/1807.06653
人类是如此擅长“无监督”,以至于我们经常用肤浅的认知作出荒谬的结论。
人类擅长“无监督”,往往是因为“滥用”过往的经验妄下结论; 而AI模型的“无监督”,是对数据“妄下”的结论。自从有了深度网络的“大锤”,曾经传统聚类的钉子(k-means, 谱聚类等)似乎都被敲了一遍。

而强行结合传统聚类的深度学习方法,缺乏语义过滤,谁能保证选取的特征都是对聚类任务有意义的?(回过头还得做PCA和白化)
为了摒弃传统聚类和神经网络的强拼硬凑,IIC(不变信息聚类)被提出 。IIC没有用传统聚类,而是对CNN稍作改动,用互信息最大化目标函数和双输入(two head)CNN的架构:

重要的地方有3点,
一, CNN网络用了双输入(不要误以为用了两个CNN,注意虚线部分是共享权重的)。为了做到无监督,模型每拿到一张图片x,都对这张图片做一次转换操作(平移、旋转或crop)得到另一张图片x’ 。因此,训练时是两次正向传播 + 一次反向传播的模式,把x,x’两张图片的两个输出z,z’一次性得到再做loss计算。
二, loss采用了互信息最大化目标函数 :
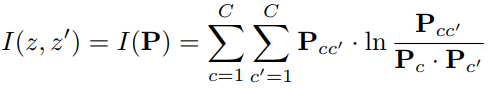
为了让模型总能在图像中辨认出(过滤出)相同类别的对象,与交叉熵(cross entropy)不同的是,最大互信息诱导出的z不会是杂乱无章的(cross entropy是对所有位一起做loss惩罚的)。最大互信息会类似one hot key,诱导每一位独立代表一个类别。
三,IIC可以用overclustering做类别更多的聚类(把那些难以聚类的对象放在更多的抽屉)。对IIC来说只要把输出的z,z’ 维数进行扩大 。
综上,IIC极力让模型学到:“当对象类别一致时,网络输出z也应该非常相似”,而最大互信息使得网络输出z有了更强的语义(对应的类别)。
比较违反直觉的是,这种无监督纯粹是把每张图像平移,旋转或crop得到成对图片的,模型最后能在这些成对图片中找到较好的聚类模式:


瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 0
0 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)