
rbf神经网络_RBF-Softmax: 让模型学到更具表达能力的类别表示
摘要交叉熵是深度学习中非常常用的一种损失,通过交叉熵学到的特征表示会有比较大的类内的多样性。因为传统的softmax损失优化的是类内和类间的差异的最大化,也就是类内和类间的距离(logits)的差别的最大化,没有办法得到表示类别的向量表示来对类内距离进行正则化。之前的方法都是想办法增加类内的内聚性,而忽视了不同的类别之间的关系。本文提出了Radial Basis Function(RBF)距离来代

摘要
交叉熵是深度学习中非常常用的一种损失,通过交叉熵学到的特征表示会有比较大的类内的多样性。因为传统的softmax损失优化的是类内和类间的差异的最大化,也就是类内和类间的距离(logits)的差别的最大化,没有办法得到表示类别的向量表示来对类内距离进行正则化。之前的方法都是想办法增加类内的内聚性,而忽视了不同的类别之间的关系。本文提出了Radial Basis Function(RBF)距离来代替原来的softmax中的內积,这样可以自适应的给类内和类间距离施加正则化,可以得到更好的表示类别的向量,从而提高性能。
1. 介绍
在使用交叉熵损失进行分类的时候,一般我们会将样本通过一个卷积神经网络,得到样本的特征表示,然后再来决定样本的类别标签。确定类别标签的时候,我们先计算样本表示向量和表示类别的向量的距离,得到logits,一般来说,距离的度量方式包括內积,余弦以及欧式距离,都可以用来得到logits。在很多现有的方法中,得到的logits会进行softmax的归一化,得到每个类别的概率。
欧式距离是一种很常用的相似性度量方法,而且具有很清晰的几何意义。但是,现有的基于softmax的方法并不是直接去优化欧式距离,而是优化类内和类间的相对差别。对比损失和三元组损失则是直接去优化欧式距离,也得到了很好的效果,但是需要比较麻烦的样本挖掘方法,而且比较不容易收敛,所以,无法完全取代传统的softmax损失。
本文的贡献有:
1、讨论了传统的softmax的主要缺陷。
2、提出了RBF softmax的方法来解决传统softmax的问题。
3、通过实验证明了RBF softmax在分类上的有效性。
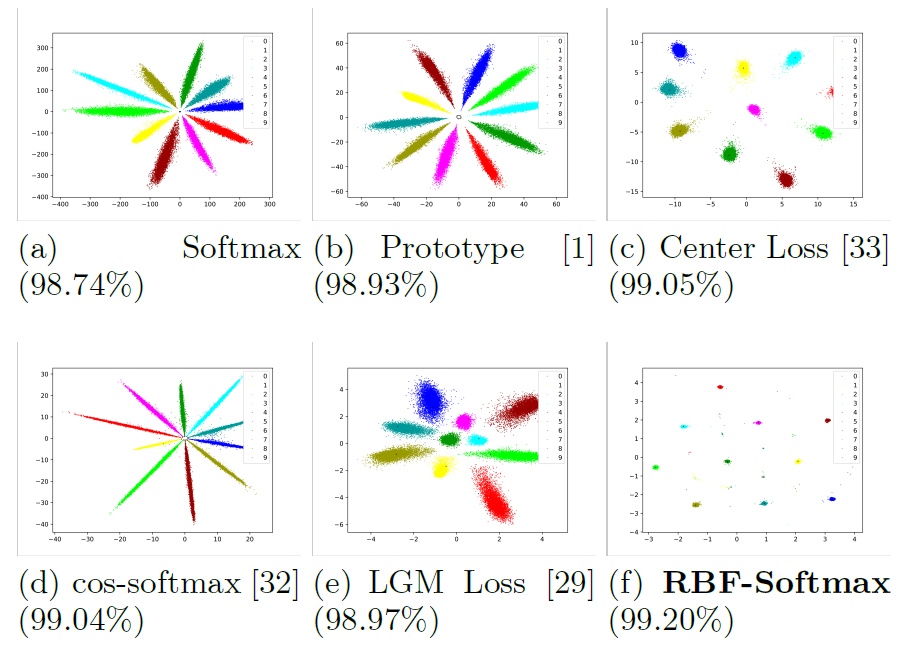
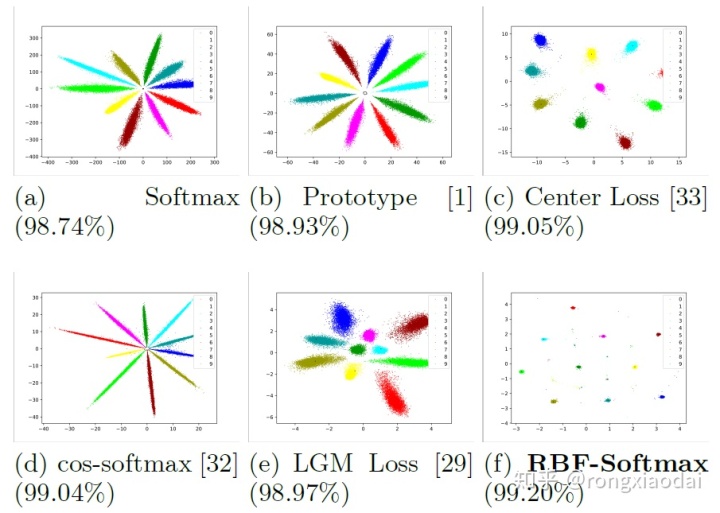
在mnist数据集中各种softmax的特征可视化如下:
2. 方法
2.1 softmax交叉熵损失以及Prototype的分析
传统的softmax交叉熵损失的计算方式为:
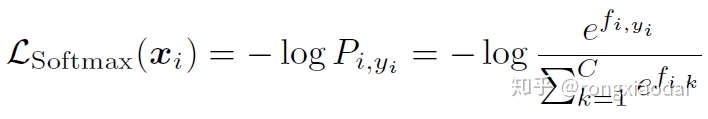
其中,fij表示样本xi与类别特征Wj的相似度,当j=yi时,表示的就是xi与其对应的类别的特征Wj的相似度,也就是类内的sample-prototype距离,在文中我们叫做类内logit。对应的,j≠yi的时候,叫做类间logit。在度量相似度的时候,常常会用內积和欧式距离。
在softmax损失中,prototype可以看做是一个特定类别的所有样本的代表,直觉上,这个理想的prototype应该在该类别的所有样本的特征向量的几何中心上。因此,prototype需要非常显著的表达能力,包括两个方面:
1、Prototype应该具有显著的区别不同类别的样本的能力。类间的距离需要大于类内的距离。
2、Prototype应该可以显示出类别之间的关系,也就是说相似的类别应该比差别明显的类别靠的更近。
图2中描述了这两个方面:

最后的特征分布非常依赖于使用的损失函数。softmax的logit的计算方法会导致两种缺陷。
训练的开始会有损失分配的偏差。因为刚开始训练的时候,特征xi和prototype Wyj并不能很好的表示他们之间的相似度,我们希望给样本的损失一些约束,以免受到离群点较大的负面影响。如图2(b)。表1显示了在训练开始的时候,样本的类内距离具有很大的多样性。最终,这种有偏差的损失分配会导致类别的prototype之间的显著的偏差,并影响真实的特征分布。
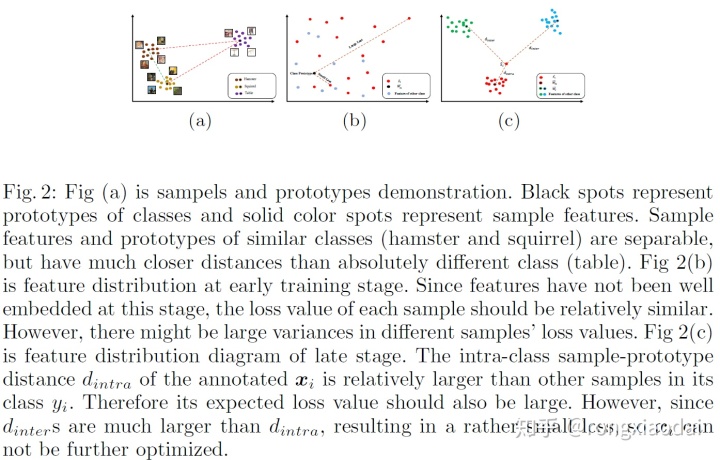
训练后期的大类内sample-prototype距离。在训练的后期,softmax也会有问题。如图2(c)所示,当一个样本的类间sample-prototype距离显著大于其类内的sample-prototype距离的时候,损失会很小,即便此时类内的logit很大。但是,我们希望能有个较大的loss来让这个样本可以更加靠近其类别的prototype。
2.2 RBF-Softmax损失函数
为了解决上面的两个问题,我们提出了一个距离,叫做Radial Basis Function kernel distance(RBF-score),用来度量xi和Wj之间的相似度:
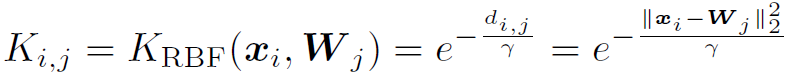
其中,dij是xi和wj之间的欧式距离,γ是超参数。相比于无界的內积和欧式距离,RBF-score在欧式距离变大的时候会衰减,其值域是0到1,RBF-score很好的度量了xi和wj之间的相似度,可以用作softmax中的logit。我们这样定义RBF-Softmax:
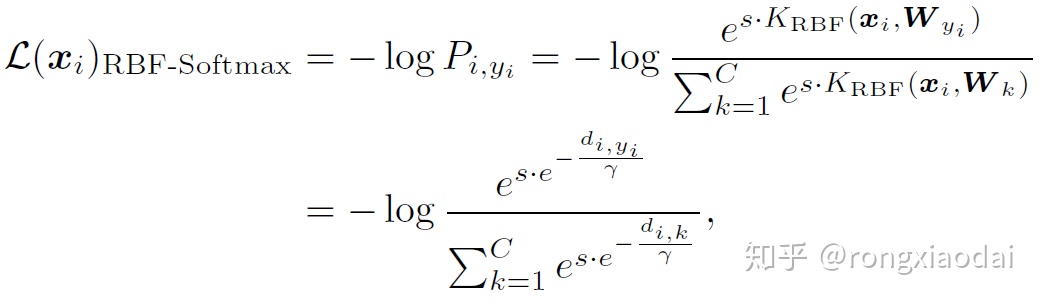
其中,s是超参数,用来扩展RBF-score的尺度。
我们再看下RBF-Softmax是如何克服上面说的两个问题的。
刚开始训练的时候,我们需要平衡类内的logits,而开始的时候,类内的logits往往会比较大,我们通过RBF kernel可以将非常大的欧式距离映射成相对小的RBF-score,这样就显著的减小了类内的多样性。这样的话,训练的开始阶段,类内的偏差就会显著的变小。另一方面,在训练的后期,传统的softmax给出的概率很容易就可以到1,但是用了RBF的概率很难到1,这样可以持续的进行优化。
超参数的影响。我们看下不同的超参数γ,s对训练的影响,如下图。
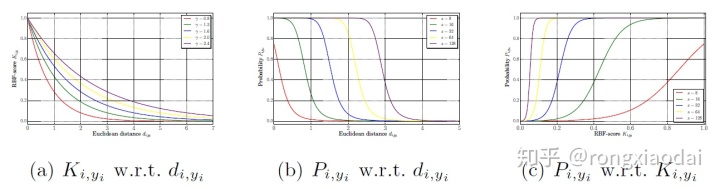
图3(a)中,当γ变大的时候,RBF-score也会变大,样本及其对应的prototype的相似度也会变大,优化任务变得简单。图3(b)(c)显示了不同的s下将欧式距离和RBF-score映射到概率的表现。s控制了概率的范围以及分类任务的难易程度:对于固定的欧式距离和RBF-score,小的s导致了概率的狭窄的范围,使得分类任务变得困难。从梯度的角度也能得到相似的结论,RBF-score和s决定了梯度的大小。
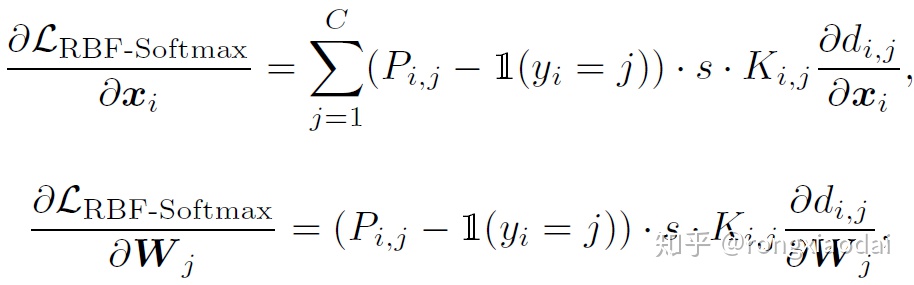
3. 实验
3.1 Prototype的探索实验
图4显示了WordNet上的不同类别的prototype的相似度矩阵:
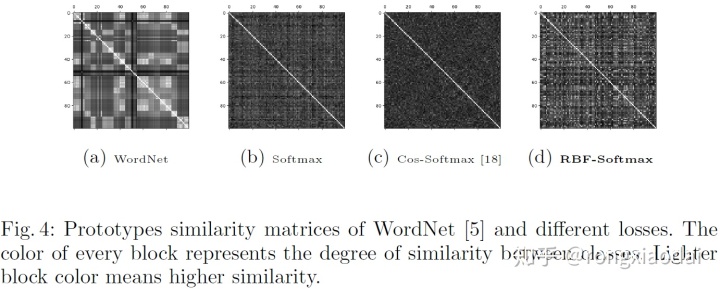
很明显,RBF-Softmax得到的相似度矩阵和WordNet的相似度矩阵更加类似。
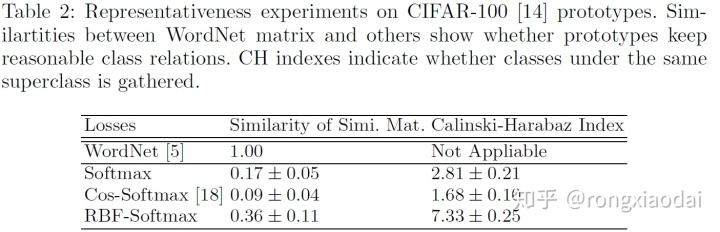
表2显示了两种不同的指标:
3.2 MNIST上的探索实验
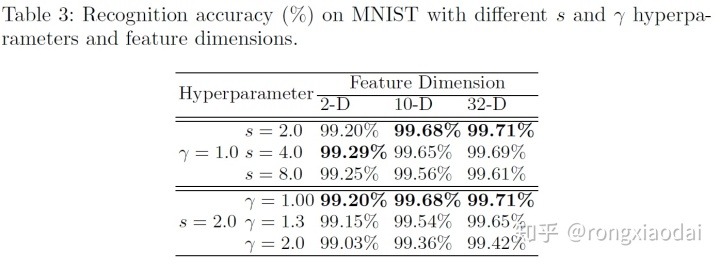
不同超参数下的准确率。
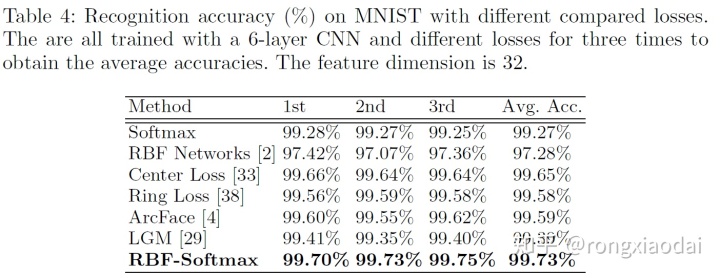
不同loss的准确率:
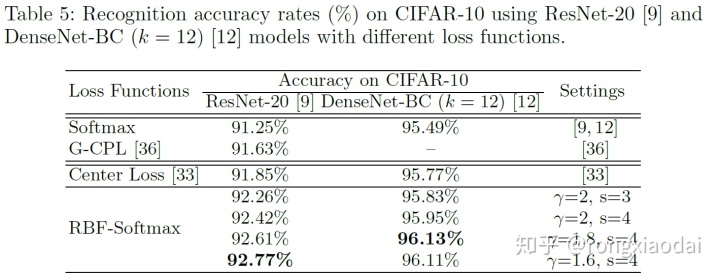
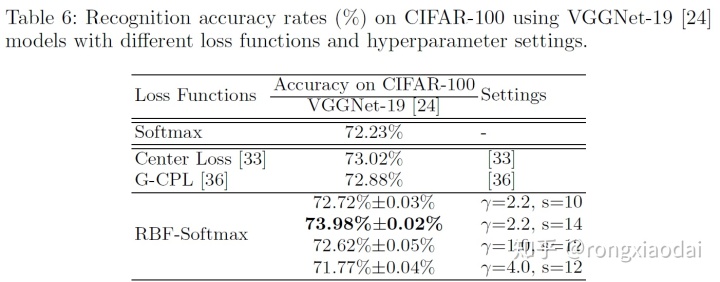
3.3 CIFAR-10/100上的实验
不同损失函数的准确率:
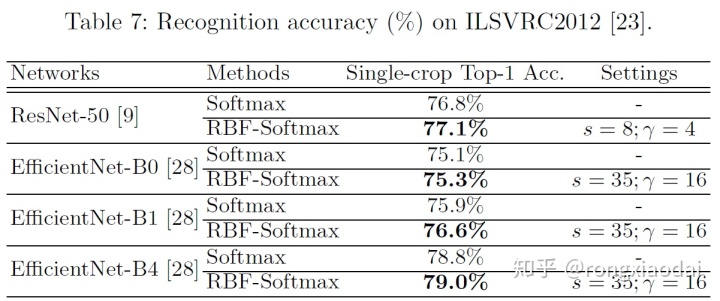
3.4 ImageNet的实验
更多内容,请关注微信公众号“AI公园”。

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)