

游戏引擎Flax Engine源码分析(二)渲染
2021SC@SDUSC之后几篇博客主要围绕Flax Engine的渲染部分做分析,因此在源代码分析开始前将简单介绍一下渲染,让整个学习过程更加完整。一、渲染简介渲染,是CG的最后一道工序,也是最终使图像符合的3D场景的阶段。一般来说,三维软件已经提供了四个默认的摄像机(这里的摄像机可以理解为从各个视角看三维图像,因此摄像机的位置决定了渲染的内容),那就是软件中四个主要的窗口,分为顶视图、正视图、
2021SC@SDUSC
之后几篇博客主要围绕Flax Engine的渲染部分做分析,因此在源代码分析开始前将简单介绍一下渲染,让整个学习过程更加完整。
由于本人是边学习相关知识边进行代码分析,因此开始时进度可能较慢,也可能有错误的地方,若有不正确希望能指出,这些博客仅是记录学习和分析过程。
一、渲染简介
渲染,是CG的最后一道工序,也是最终使图像符合的3D场景的阶段。
一般来说,三维软件已经提供了四个默认的摄像机(这里的摄像机可以理解为从各个视角看三维图像,因此摄像机的位置决定了渲染的内容),那就是软件中四个主要的窗口,分为顶视图、正视图、侧视图和透视图。我们大多数时候渲染的是透视图而不是其它视图,透视图的摄像机基本遵循真实摄像机的原理,所以我们看到的结果才会和真实的三维世界一样,具备立体感。
渲染程序通过摄像机获取了需要渲染的范围之后,要计算光源对物体的影响,这和真实世界的情况是一样的。许多三维软件都有默认的光源,否则,我们是看不到透视图中的着色效果的,更不要说渲染了。因此,渲染程序就是要计算我们在场景中添加的每一个光源对物体的影响。和真实世界中光源不同的是,渲染程序往往要计算大量的辅助光源。
简单来说,渲染其实就是由一个个含有可编程管线的函数组成,输入参数是各种贴图以及
Buffer ,渲染过程就是一遍一遍执行这些函数。
二、Flax Engine渲染介绍
首先是2D渲染,我们看一下文件结构:

其次是3D渲染:

Flax Engine 中的渲染系统使用最新图形 API(DirectX 12、Vulkan 等)管道的全部功能来创建丰富的效果,包括延迟着色、全局照明、全场景反射和后期处理。
单桢渲染流程图如下:
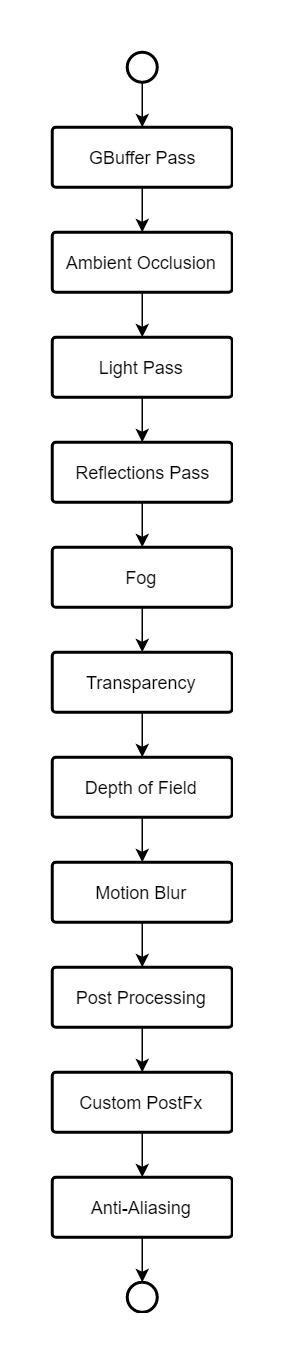
(注:Pass:就是一次像素处理和一次顶点处理,也就是一次绘制。简单来说一个pass就是走完图形渲染底层一个渲染流程,,从顶点计算 着色 光栅化等这一套流程,从而得到一帧数据的过程。)
(一)GBuffer:指Geometry Buffer,亦即"几何缓冲"。区别于普通的仅将颜色渲染到纹理中,G-Buffer指包含颜色、法线、世界空间坐标的缓冲区,亦即指包含颜色、法线、世界空间坐标的纹理。
(二)Ambient Occlusion :环境光遮蔽,AO是来描绘物体和物体相交或靠近的时候遮挡周围漫反射光线的效果。AO特效在直观上给我们玩家的感受主要体现在画面的明暗度上。
(三)Light Pass:这里我理解为光线的计算渲染过程。
(四)Reflections Pass:反射
(五)Transparency:透明度
(六)Depth of Field:景深
(七)Motion Blur:运动模糊
(八)Post Processing:后处理
(九)custom PostFx:定制后期处理(定制动态模糊)
(十)Anti-aliasing:抗锯齿
三、2D渲染
我们首先看Render2D下的头文件,Render2D.h,主要声明了一个FLAXENGINE_API Render2D:
#include "Engine/Core/Math/Color.h"
#include "Engine/Scripting/ScriptingType.h"
#include "Engine/Core/Types/Span.h"
struct SpriteHandle;
struct TextLayoutOptions;
struct Matrix;
struct Matrix3x3;
struct Viewport;
struct TextRange;几个结构体:角色句柄,文本布局选项,矩阵矩阵3x3,视口,文本范围
我们再看下面这段代码 :
API_ENUM(Attributes="Flags") enum class RenderingFeatures
{
/// <summary>
/// The none.
/// </summary>
None = 0,
/// <summary>
/// Enables automatic geometry vertices snapping to integer coordinates in screen space. Reduces aliasing and sampling artifacts. Might be disabled for 3D projection viewport or for complex UI transformations.
/// </summary>
VertexSnapping = 1,
};这里的API_ENUM是一个宏(计算机科学里的宏是一种抽象,它根据一系列预定义的规则替换一定的文本模式。在遇到宏时会自动进行这一模式替换。对于编译语言,宏展开在编译时发生) ,且是一个可变参数宏。
其定义部分在Config.h文件中,同时还定义了其他几个脚本API:
// Scripting API defines (see C++ scripting documentation for more info)
#define API_ENUM(...)
#define API_CLASS(...)
#define API_INTERFACE(...)
#define API_STRUCT(...)
#define API_FUNCTION(...)
#define API_PROPERTY(...)
#define API_FIELD(...)
#define API_EVENT(...)
#define API_PARAM(...)
#define API_INJECT_CPP_CODE(...)
#define API_AUTO_SERIALIZATION(...) public: void Serialize(SerializeStream& stream, const void* otherObj) override; void Deserialize(DeserializeStream& stream, ISerializeModifier* modifier) override;
#define DECLARE_SCRIPTING_TYPE_MINIMAL(type) public: friend class type##Internal; static struct ScriptingTypeInitializer TypeInitializer;
缺省号代表一个可以变化的参数表。使用保留名 __VA_ARGS__ 把参数传递给宏。
然后是枚举类RenderingFeatures,这里简单介绍一下枚举类的作用,因为这也是一篇学习博客。
枚举类也称限定作用域的枚举类。传统C++的enum却特殊,只要有作用域包含这个枚举类型,那么在这个作用域内这个枚举的变量名就生效了。即枚举量的名字泄露到了包含这个枚举类型的作用域内。在这个作用域内就不能有其他实体取相同的名字。
枚举类有以下几个优点:1.降低命名空间污染,在其他地方使用枚举中的变量就要声明命名空间;2.避免发生隐式转换,如果非要转换,按就只能使用static_cast进行强制转换。3.可以进行前置声明,即型别名字可以比其中的枚举量先声明。
关于枚举类中的两个枚举类型None=0和VertexSnapping = 1,其中VertexSnapping = 1 代表启用自动几何顶点捕捉到屏幕空间中的整数坐标。 减少混叠和采样伪影。 对于 3D 投影视口或复杂的 UI 转换,可能会被禁用。
/// <summary>
/// The active rendering features flags.
/// </summary>
API_FIELD() static RenderingFeatures Features;活动渲染功能标志。
接下来头文件中是各种相关函数的声明,其具体实现在Render2D.cpp文件中,我们将在下一篇博客中进行分析,这里我们选取几个函数进行简单的解读:
/// <summary>
/// Gets the current rendering viewport.
/// </summary>
static const Viewport& GetViewport();
获取当前渲染视点 。
这里有几个重载函数Begin,我们看看其中一个,其他几个只是参数不同:
/// <summary>
/// Begins the rendering phrase.
/// </summary>
/// <param name="context">The GPU commands context to use.</param>
/// <param name="output">The output target.</param>
/// <param name="depthBuffer">The depth buffer.</param>
API_FUNCTION() static void Begin(GPUContext* context, GPUTexture* output, GPUTexture* depthBuffer = nullptr);这个函数的作用是开始渲染短语,几个参数分别是context(要使用的 GPU 命令上下文),output(输出目标),depthBuffer(深度缓冲区)。其他三个重载函数有两个参数不同:
API_FUNCTION() static void Begin(GPUContext* context, GPUTexture* output, GPUTexture* depthBuffer, API_PARAM(Ref) const Matrix& viewProjection);
API_FUNCTION() static void Begin(GPUContext* context, GPUTextureView* output, GPUTextureView* depthBuffer, API_PARAM(Ref) const Viewport& viewport);
API_FUNCTION() static void Begin(GPUContext* context, GPUTextureView* output, GPUTextureView* depthBuffer, API_PARAM(Ref) const Viewport& viewport, API_PARAM(Ref) const Matrix& viewProjection);viewport(输出视口),viewProjection(视图*投影矩阵。 允许以 3D 或自定义转换呈现 GUI)
与Begin函数相对的End函数,结束渲染短句:
/// <summary>
/// Ends the rendering phrase.
/// </summary>
API_FUNCTION() static void End();这里有两个内联函数:
/// <summary>
/// Draws a rectangle borders.
/// </summary>
/// <param name="rect">The rectangle to draw.</param>
/// <param name="color">The color to use.</param>
/// <param name="thickness">The line thickness.</param>
API_FUNCTION() FORCE_INLINE static void DrawRectangle(const Rectangle& rect, const Color& color, float thickness = 1.0f)
{
DrawRectangle(rect, color, color, color, color, thickness);
}
/// <summary>
/// Draws a line.
/// </summary>
/// <param name="p1">The start point.</param>
/// <param name="p2">The end point.</param>
/// <param name="color">The line color.</param>
/// <param name="thickness">The line thickness.</param>
API_FUNCTION() FORCE_INLINE static void DrawLine(const Vector2& p1, const Vector2& p2, const Color& color, float thickness = 1.0f)
{
DrawLine(p1, p2, color, color, thickness);
}DrawRectangle()画出矩形边框;DrawLine()画出线条。
FORCE_INLINE相关定义位于Compiler.h中:
#define INLINE __inline
#define FORCE_INLINE __forceinline__inline与inline等同。inline和__inline通知编译器将该函数的内容拷贝一份放在调用函数的地方,称之为内联。内联减少了函数调用的开销,但却增加了代码量。__forceinline关键字则是不基于编译器的性能和优化分析而依赖于程序员的判断进行内联,但它也不保证一定内联,有些情况函数是肯定不能内联的。对于__forceinline,不加考虑的使用它将会造成代码量的膨胀而只得到很小的性能回报,甚至造成性能下降。
这一次的分析暂时到这里,其余函数声明不再赘述,下一篇博客将会具体分析函数的实现,感谢。

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)