
《保护我们的数字遗产:DNA数据存储》白皮书发布
2021年6月,联盟发布首份白皮书《保存我们的数字遗产:DNA数据存储》(Preserving Our Digital Legacy: An Introductionto DNA Data Storage)。白皮书介绍了DNA存储的基本原理、技术概述、潜在的新存储介质的成本,讨论了使用DNA存储的必要性,以及其在解决数字数据指数增长方面的前景。
编者按:
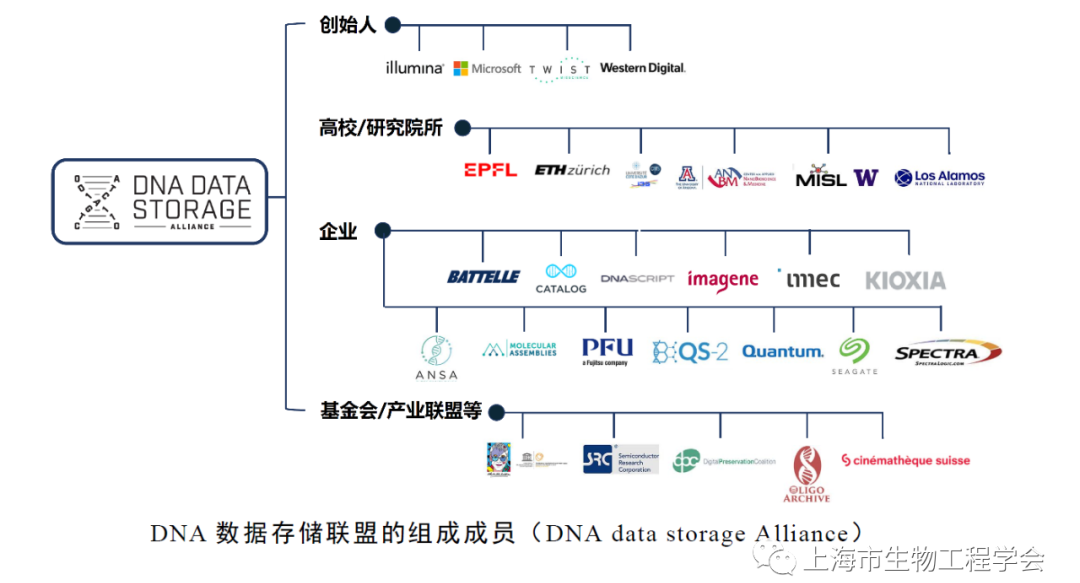
2020年10月,Twist Bioscience、Illumina、Western Digital(西部数据)、微软研究院等公司和机构联合成立DNA数据存储联盟(DNA data storage Alliance)。联盟的目标是创建可互操作的存储生态系统,并利用人造DNA作为数据存储介质。目前,该联盟成员已经超过25家机构。2021年6月,联盟发布首份白皮书《保存我们的数字遗产:DNA数据存储》(Preserving Our Digital Legacy: An Introductionto DNA Data Storage)。白皮书介绍了DNA存储的基本原理、技术概述、潜在的新存储介质的成本,讨论了使用DNA存储的必要性,以及其在解决数字数据指数增长方面的前景。
1 数字数据增长势态:海量数据
以数据的创造、购买、销售和积累为特征的全球信息时代正在考验着我们分析、存储、处理和保护这些珍贵数据的能力。根据国际数据公司(IDC)DataSpher全球预测报告显示,2020-2025年间,全球生成的数据(包括新生成和复制副本)预计将以23%的复合年增长率(CAGR)增长,到2025年达到180 ZB。短短三年时间,新创建的数据就从2017年的3ZB增加到2020年的64 ZB。IDC还指出,除了新数据的数量外,复制数据与最初捕获数据的比例也在增加。
数据保存和数据挖掘推动“海量数据”的产生。机器人、智能城市、自动驾驶汽车、医疗保健、天文学、气候科学等不同领域的用户都在寻求容量更大的数据集,以便未来进行数据挖掘,保持竞争力和/或推动科学发现。如果能够以更低的总成本存储更多数据,在权衡保存或丢弃数据之间的利弊时,就可以保存更多原始数据以供未来进行数据挖掘时使用。
此外,相关政府也在制定数据存储相关的法案,例如,美国针对所有上市公司和一些私营公司制定了《健康保险携带和责任法案》(HIPAA)以及《Sarbanes-Oxley法案》(SOX)。因此,数据增长率、数据挖掘的商业/科学潜力,以及监管要求都在推动更长时间内储存更多数据的需求。
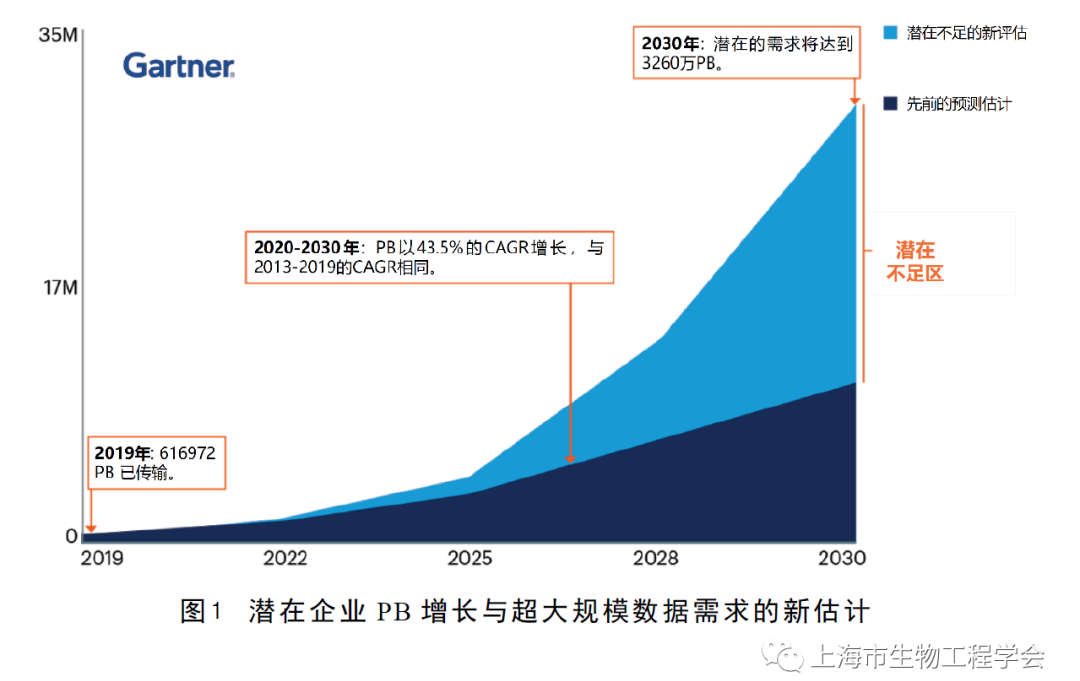
尽管上述因素推动了前所未有的存储需求的增长,但存储供应并没有跟上快速增长的需求。据IDC StorageSphere报告估计,存储设备总安装基数预计将以19%的CAGR(2020-2025年)增长。另一方面,Gartner咨询公司指出,目前存在潜在的不足区(图1),并估计超大规模供应商存储需求已经超过目前的增长速度:2013-2019年,以近35%的CAGR增长,2020-2030年有可能飙升至50%。
2 数字存储的发展动态
存储行业的创新实现了密度、尺寸和总容量方面的惊人进步。历史上首个硬盘驱动器(HDD)于1956年推出,尺寸相当于一台冰箱大小,容量为5MB,价格为1万美元/MB。随着磁记录技术的逐步改进,人们已经在3.5英寸的外形尺寸中实现18-20TB的规模。2019年,近线硬盘的平均售价约为20美元/TB,比1956年的硬盘售价低了9个数量级。
2.1 存储技术面临的挑战
尽管技术不断改进,考虑到ZB规模和长存储时间的需求,当前的存储技术仍然面临关键挑战。
2.2.1 存储维护和更换成本
今天的存储介质(磁性、半导体等)在保管妥当的情况下可以保存数据几十年,但就像任何有形资产一样,它们会随时间的推移而磨损和退化。因此,必须定期检查以确保数据的完整性。
此外,介质的固有格式与读写技术紧密结合。由于技术或商业原因,某些存储设备的阅读器或物理介质格式已经过时,使得这些存储设备的数据无法再读取。因此,存储在当前任何存储设备上的数据都需要定期被重写到新一代设备上,以确保能继续访问。
2.2.2 密度限制
1975年,Gordon Moore阐明了摩尔定律——可封装在集成电路中的晶体管数量每两年就会翻一番。该预测自发表以来一直保持不变,CAGR约为40%。对于存储,介质密度的增长率各不相同。例如,HDD驱动器1998-2002年的面密度CAGR为108%,2003-2009年为39%、2009-2018年为7.9%。尽管诸如能量辅助记录等技术的进步正在推动HDD面密度发展,但磁介质面密度的总体趋势正在放缓。NAND闪存已达到周期性扩展限制;2D NAND存储单元尺寸在平面(x-y)维度上减小, 2012年左右达到缩放限制;使用3D NAND(在z维度上构建单元)可以恢复增长,但最终也会达到极限。
这些趋势对当今ZB级的数据存储提出了资本支出和运营成本等方面的挑战,但并不意味着当前的存储解决方案会过时。相反,它表明需要在存储结构中增加新级别,以经济高效的扩展方式,满足不断发展的存储生态系统中数据的爆炸性增长。
2.2.3 能源和可持续性问题
据估计,2018年,数据中心消耗了全球总电力的约1%;未来10年内可能会增加3倍或4倍。如果不持续提高能效,到2030年,数据中心的用电量可能会增长到全球总用电量的3%-13%。此外,传统存储设备的材料,尤其是HDD和磁带依赖具有复杂供应链的稀土金属制成,给可持续发展带来挑战。
2.2 存储介质的总拥有成本
根据总拥有成本(TCO)查看存储层次结构非常重要。存储可以根据数据访问的频率进行分层(图2)。频繁访问的数据(“热数据”)通常存储在高性能设备(例如SSD)上。访问频率较高的数据(“暖数据”)通常存储在HDD上。不经常访问的数据(“冷数据”)通常存储在磁带上。
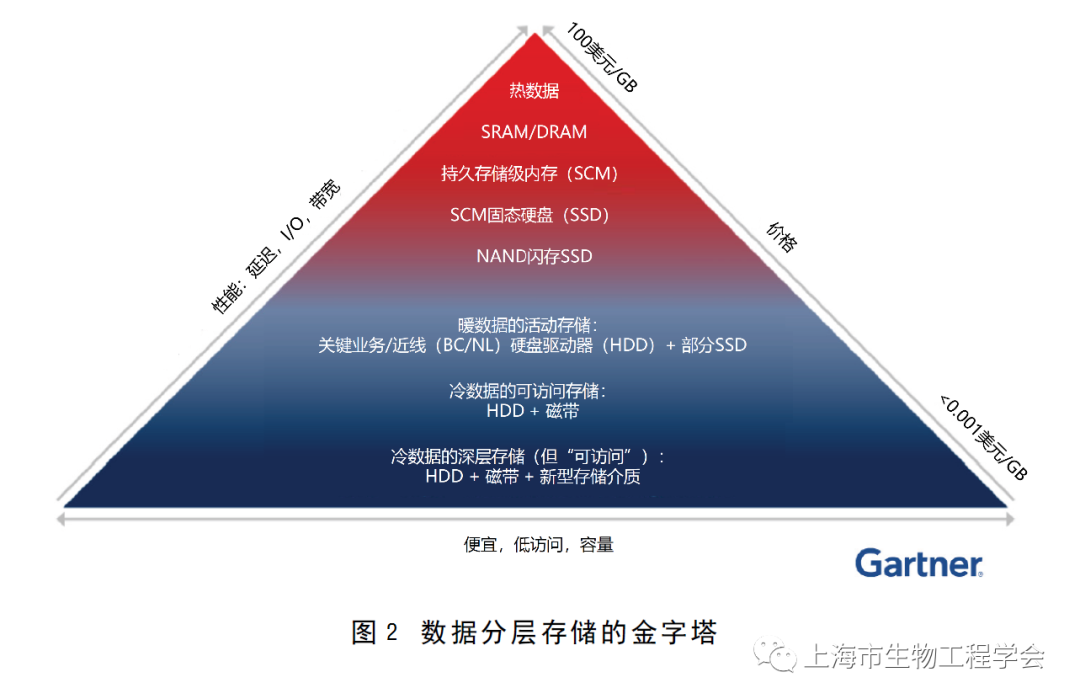
随着金字塔向上移动,存储介质获取和更换成本会推高TCO。此外,金字塔中较高层的存储设备与较低层的设备会消耗更多电力,进而推高TCO。每个存储层中的总位数与该层的基础成本成反比。在数据中心,SSD和HDD的频繁也增加了维护成本,增加了TCO。
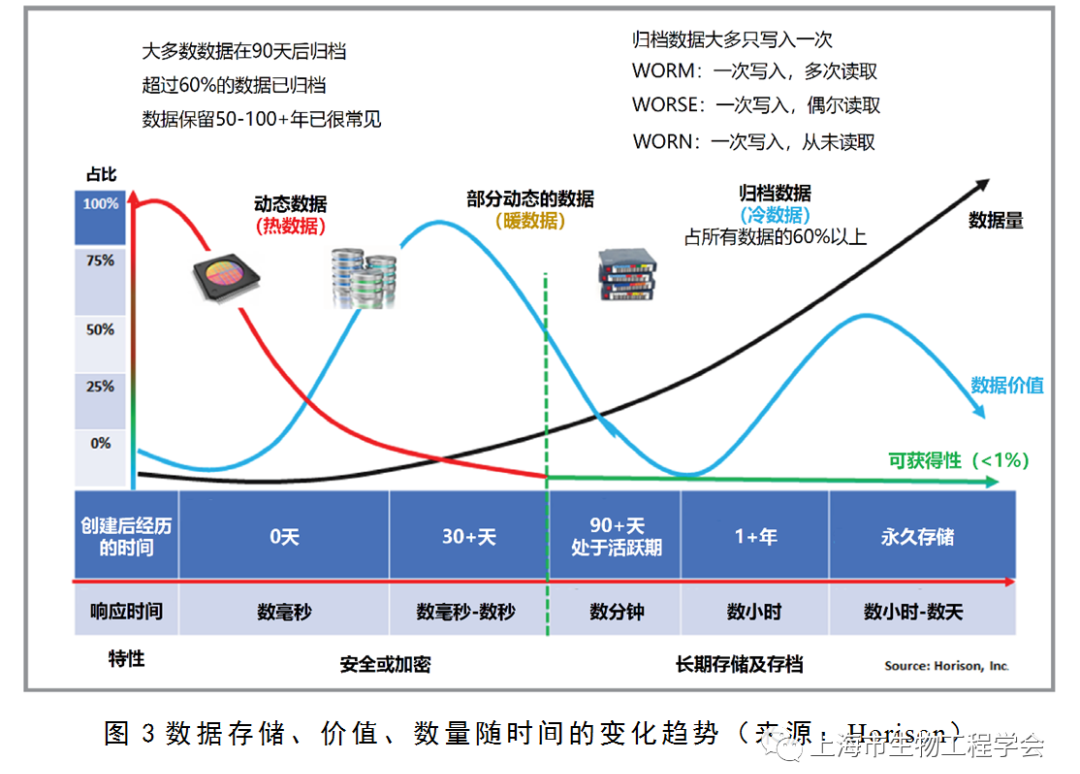
推高TCO的另一个因素是冷数据量的增长速度快于其他层次的数据,也就是说,需要长期存储的数据越来越多。图3显示了数据的访问频率(红绿线)、商业价值(蓝线)和数量(黑线)随时间的变化趋势。
因此,数据存储的总拥有成本(TCO)包括以下几大因素:硬件和介质的购置成本、数据存储的时间范围、数据写入的成本、存储数据的年增长率、检索数据的数量和频率、存储的副本量、年迁移量、电力设施的成本、迁移的成本,员工成本等。
3 DNA作为存储介质
基于DNA的数据存储是既能减少传统存储的物理和碳足迹,同时又可以显著降低归档层TCO的解决方案。如果存储得当,DNA数据可以稳定保存数千年,甚至没有损耗且极少需要维护或更新。基于DNA的数据存储的存储密度、耐久性和低功耗从根本上降低了TCO,使其成为长期存档数据存储的有力竞争者。
3.1 生物与合成(人造)DNA
DNA是自然界可靠、长期存储遗传信息的系统。自然界中,DNA通常以双链螺旋(dsDNA)形式存在,但某些生物中以单链聚合物链(ssDNA)形式存在。dsDNA或ssDNA均可用于DNA数据存储。然而,在数字数据存储的环境中,DNA是人造的:DNA数据存储介质的创建不需要任何细胞、生物体或生命的创建或修改,同样,生成的存储数据也不会导致任何细胞、生物体或生命的创建或修改。
3.2 DNA存档的特性
DNA的独特特性使其成为存储档案数据数十年、数百年甚至数千年的理想介质。
介质耐久性:DNA是生物系统中信息存储的首选分子。在干燥的室温环境下,它可以完好无损地保存数千年。斯德哥尔摩古遗传学中心领导的国际团队发现并成功测序了120万年前的哥伦比亚猛犸象遗骸的DNA。这种化学稳定性确保DNA编码的数据可以稳定地保存很长时间。
维护简单性:如今的存储介质必须定期进行固定检查,以确保数据的可读性。由于DNA的持久性和其他特性,预计其静态维护将比传统存储解决方案简单,也会显著降低数据保存成本。
格式不变性:区分DNA作为存储介质的一个基本因素是其分子结构。如今保存在DNA中的数字数据将在数千年后以化学方式读取。与传统存储相比,此特性为基于DNA的存储提供了显著优势。DNA的不可变格式确保了存储数字数据的DNA始终能够被读取,并且只要编写数据的编码(逻辑结构与物理设备)可用就可以解码。
密度:DNA介质使多种形式的储存成为可能,包括三维存储。DNA碱基的大小约为数十个原子,体积约为1立方纳米。因此,即使考虑到大量实际开销,1mm3卷积中可存储的DNA位数估计为9 TB,大约是18TB LTO-9磁带(大约23.5万mm3)容量的一半。如果LTO磁带内的空间填满DNA二进制位,磁带将容纳约200万TB的数据,约为LTO-9磁带容量的11.5万倍。
能源效率和可持续性:与当前的数据中心和存储技术相比,存储在DNA中的数据在静止状态下消耗最少。虽然目前的数据中心使用了大量的电力和土地,但在DNA数据存储下这些需求或将忽略不计。由于DNA的耐用性和密度,其对环境的影响比废弃的磁带驱动器或HDD要小得多。
成本:在处理需要持续数十年或更长时间的归档数据时,这种不会随时间产生额外成本的存储介质非常具有吸引力。
4 将数字数据导入DNA
为了在DNA中存储数据,原始数字数据被编码(从1和0映射到DNA碱基序列),然后合成(写入)并存储。当需要存储的数据时,对DNA分子进行测序(读取)和解码(从DNA碱基重新映射回1和0)。
编码(将二进制位转换为碱基):DNA数据存储编码的基本概念是将原始数字数据的1和0转换为组成DNA的碱基(ACGT)。编码方法与所使用的合成和测序方法紧密结合,实现可接受的二进制位密度,补偿错误率,能够将原始二进制数据分割成DNA链,也能将DNA链重新组装回二进制数据。
合成(写入):合成是制造DNA的阶段。基于一系列化学步骤,由编码步骤确定的DNA分子以反映“位对碱基”或其他编码方法的各种不同方式组装。
DNA的物理存储:DNA合成后,被封装以长期保存并放在DNA存储库中。封装有多种类型,包括用惰性气体将DNA密封在胶囊中,或将其与有助于保存DNA的化学物质混合。
检索(从文库中检索):存储后,一旦需要数据,就可以从文库中检索编码的DNA并为测序作准备。通常还包括为测序方法制作的分子副本,这是分子密集型的,适用于更多副本服务分发或进一步存储需求的情况。
测序(读取):测序是确定DNA片段中DNA碱基(ACGT)的身份和顺序的过程。目前使用的测序方法多种多样,例如合成测序(SBS)、纳米孔测序等。
解码(将碱基转换回二进制位):解码涉及到将DNA测序中的碱基映射回数字数据。重要的是,它涉及从合成、保存到测序期间的纠错。解码完成后,数据将以数字形式重新组合并返回给用户。
5 DNA数据存储的经济性
当前,用于数据存储的DNA写入(合成)和读取(测序)其实并没有实现大规模应用。然而,这些应用是有发展前景的。合成成本是所有应用案例的基础,而测序成本对需要频繁读取的数据的归档尤为重要。
5.1 合 成
DNA数据存储的合成成本取决于位如何编码到DNA碱基中,以及合成DNA的具体方法。由于当今商业应用不包括DNA数据存储,因此难以对与DNA数据存储直接相关的合成进行定价估算。美国情报高级计划研究局(IARPA)正在通过分子信息存储项目(MIST)资助该领域的工作,并且已经制定了目标路线图——到2024年合成成本为1美元/GB,到2030年为1美元/TB。
除了成本趋势,用于数据存储的DNA合成还有一个与遗留存储相关的特性。对于遗留存储,数据集的第一个或任何后续副本的成本与写入原始副本的成本相同,即每种情况下的介质容量成本。相比之下,对于DNA数据存储,创建数据集的第一个副本有与合成相关的成本,但由于PCR等工具的特性,创建后续副本的成本基本上为零,在这些工具中,副本是该过程的自然产物。基于DNA存储的这种“免费副本”属性与当今大规模存储系统的趋势非常吻合。
5.2 测 序
讨论DNA测序过程可以读取多少数据到底意味着什么?以人类基因组测序为例,美国国家人类基因组研究所(NHGRI)估计,人类基因组测序成本从2001年的1亿美元下降到2020年的1000美元。整个人类基因组包含约60亿个DNA碱基,如果将每DNA编码一个二进制位,一个人类基因组可以编码约0.75 GB数据,相当于在1000美元/人类基因组的情况下,数据成本价约为1300美元/GB。这个成本与当今高端商业DNA测序平台的通量一致,当转换为数字承载能力时,假设每个DNA碱基为1个二进制位,其成本为800-1500美元/GB。
此外,Illumina和其他公司预计,未来几年内,可能仅需100美元就可在最高通量测序平台进行人类基因组测序。这意味着成本又减少了10倍,约为130美元/GB。鉴于IARPA的目标是到2030年达到1美元/TB,以及当今主流存储技术在读写成本没有太大差异的情况下,预计DNA数据存储生态系统的成本或将接近测序成本。
5.3 存储和维护
在审查归档存储成本时,不仅要考虑读写成本,还要考虑随时间推移的总成本。图4总结了写入和存储数据的成本,其中比较了云存储、磁带存储和DNA数据随时间推移的预计成本。该分析假设DNA没有定期的数据迁移,只有固定检查和存储所需的能量消耗。可以看到,随时间推移,DNA编写成本逐渐下降,存储和维护成本逐渐增加。
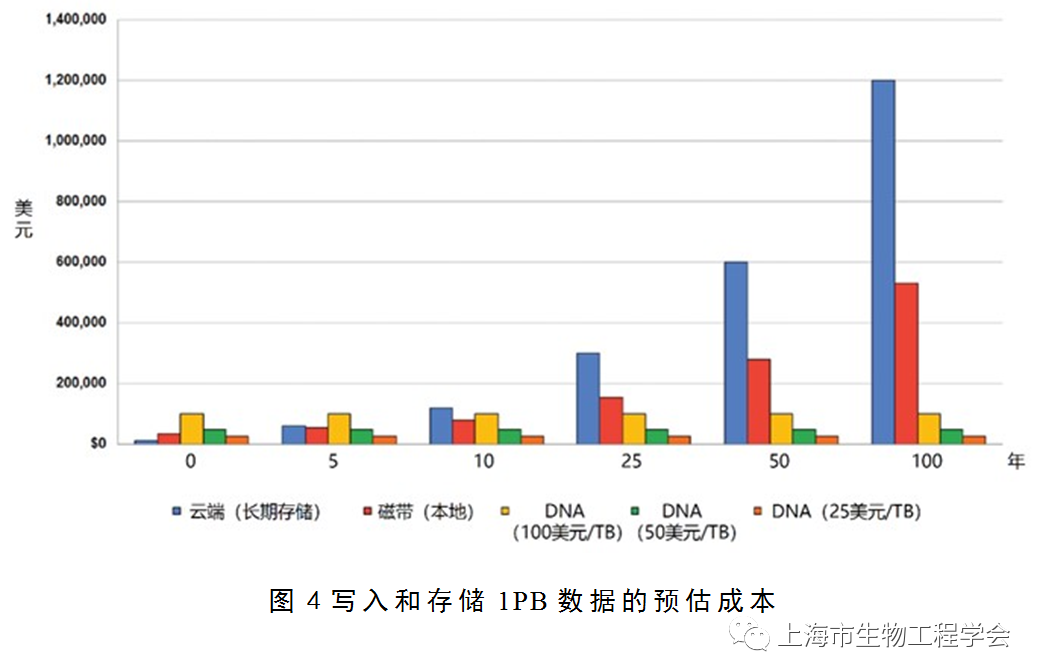
-
使用Fujifilm TCO计算器计算的磁带价格
-
价格取自Amazon AWS公开定价(2021.2.1)
-
DNA存储价格基于选定的成本方案,仅供比较
6 DNA编码的发展现状
用于存储数据的DNA编码是将原始数字1和0转换为DNA分子的碱基序列(ACGT)的过程。特定的编码算法在技术上与合成和测序方法的基础化学过程交织在一起,因此编码方法会受到DNA数据存储系统整个流程的复杂性、可扩展性、数据密度、数据可靠性以及成本的影响。
在DNA上进行编码传输时,1和0在合成前映射到DNA碱基的方式,以及DNA碱基在测序过程中映射回1和0的方式,大致类似在电气传输过程中的数字到模拟到数字的转换。ECC位和加扰模式在合成前添加到数据流中并在测序时(接收器)删除,以检测/纠正错误。
用于DNA数据存储的DNA编码另一个重要方面是分段(segmentation)和寻址(addressing)。由于合成DNA链的长度存在实际限制,因此目前所有的编码方案都是编码地址信息,以便将长数字位流分割成DNA子片段,随后在测序和解码过程中重新组装。可以使用多种寻址方案来实现分段,例如使用字段(fields)、隐式映射(implicit mapping)或外部标签。
7 DNA合成的发展现状
大多数生物研究和生物工程都涉及合成DNA。考虑到数据存储时,所有DNA合成方法的总通量?比任何现有存储技术都慢几个数量级。未来需要大规模并行化,以使DNA数据存储比传统数据存储技术更具成本竞争力。
7.1 碱基合成(化学和酶)
目前,所有商业合成DNA都是使用磷酰胺合成方法。自20世纪80年代末以来,这一过程已实现自动化,是目前构建合成DNA最可靠、测试效果最好、质量最高的方法。价格较高是该方法的主要限制之一,另一个限制是用这种方法写入DNA的速度。如今,科研人员已经在测试新方法和技术,希望通过并行方法提高速度并且降低成本。
2010年开始,一些研究人员开始探索化学合成的替代方法。酶合成技术只使用含水试剂,产生的废物副产品较少,有助于实现可持续发展;此外,该技术可以加速合成,实现更高的通量、增加聚合物长度和数据密度,以降低存储成本。尽管酶合成技术尚未进入商业市场,但正在快速发展:2018年已经实现了酶法合成150碱基长度的寡核苷酸的概念验证,且错误率低,首批产品计划在2021年底完成。
7.2 合成的连接技术
连接技术主要用于合成DNA长链,基本概念是使用合成技术创建一个预定义的寡核苷酸库,然后将这些短寡核苷酸连接起来,以可接受的错误率产生长链的核苷酸。根据编码方法的不同,较长的核苷酸构建意味着可以在较大的有效负载上进行纠错、片段重组,且成本更低。
8 保存用于数据存储的DNA
一旦DNA被合成并被数字数据编码,介质的保存涉及几个因素。在DNA数据存储应用的整个环境中,必须考虑实际方面,例如容器成本、每个容器的数据量、时间、打包/解包成本。同样,物理存储和检索的自动化也非常重要,包括收集合成输出、准备物理存储的DNA、恢复材料以服务读取请求,以及为读取过程做准备。
8.1 DNA衰变机制
DNA与一些小的有机分子、紫外线照射、水、酶、微生物、氧气、臭氧和其他大气污染物的相互作用会出现降解。由于水对氧化剂或酶的重要作用,水是DNA最主要的降解因素。据估计,在25℃条件下,埋藏在古代骨骼化石中的DNA半衰期为512年,最佳保护条件下可长达10万年以上,但暴露在潮湿环境下的DNA半衰期显著降低。因此,DNA的存储策略必须解决与湿度相关的问题。
8.2 DNA介质保护技术
目前一般有两类保护策略:分子级保护和宏观保护。DNA数据存储系统可以将两者结合。分子方法,即单个DNA分子被嵌入一种基质材料中,以防止水和氧气扩散到单个DNA分子(又称化学封装)。由于水在聚合物、有机分子和水溶性盐中的相对高的扩散速率,最合适的基质是玻璃等无机材料。宏观方法,即干燥的DNA样本在惰性气体条件下存储在密封容器中,例如金属胶囊(又称物理封装)。只要确保容器的完整性,控制氧气和水的扩散,就可以避免携带DNA分子的数据发生相互作用。
9 DNA测序的发展现状
20世纪90年代中期开始,“二代测序”的快速发展,拓宽了DNA测序的应用范围。二代测序通过大量并行实现通量、可伸缩性和速度方面的突破。目前商业上使用的二代测序包括两大类:合成测序和纳米孔测序。
9.1 合成测序
合成测序是指边合成边测序(Sequencing-by-synthesis,SBS)。Illumina公司(当时的Solexa)在2006年开创了SBS,目前主要的方法包括:
-
Illumina SBS是基于荧光标记核苷酸的成像。主要方法是将DNA库添加到流式细胞中,然后放大成簇,之后开始合成步骤;通过加入4种荧光标记的可逆终止碱基,洗去非合并核苷酸;摄像机拍摄荧光标记的核苷酸图像;最后,从DNA中去除染料和3'端阻断剂,开启下个周期。
-
Pacific Biosciences公司的SMRT技术(Pacific Biosciences Single Molecule Realtime Sequencing Technology)是一种利用聚合酶,通过ssDNA模板分子合成荧光标记的碱基,并进行实时成像。该技术可以产生长时间的连续读取,单分子分辨率下的平均长度为15kb(千碱基)。
-
Thermo Fisher Scientific公司的Ion Torrent半导体测序技术是将DNA碱基编码的信息直接转换为半导体芯片上的数字信息(0和1),而不需要使用任何修饰过的核苷酸或光学元件。
9.2 纳米孔测序
纳米孔测序不同于SBS的底层机制。在纳米孔测序中,一条DNA链可以通过电解质膜上的孔,DNA链穿过孔便可进行记录,检测出原始DNA链中的碱基。纳米孔DNA测序可以实时进行,因此可立即获得结果。目前应用最广泛的纳米孔DNA测序解决方案来自Oxford Nanopore Technology公司,他们利用嵌入在脂膜中的生物孔使得传感更加精确。
10 总 结
今天,我们正处在一个数据存储变革的风口浪尖。通过数据中心的服务器、移动设备和传感器网络,大规模的信息数字化正在进行中。人工智能技术和数据处理能力使挖掘海量数据成为可能,然而将这些数据转化为知识加以利用的关键是保证数据的长期存储。
传统存储解决方案在过去几年里已经得到广泛扩展,但是磁性介质(HDD和磁带)面积密度的增长正在放缓,数据增长速度超过了目前已有的存储解决方案,需要一种更密集、更持久、更可持续、更经济的新型存储介质,以应对存档数据未来的需求。
据估计,到2030年,DNA合成成本可能达到1美元/TB,DNA测序的成本也可能达到相近水平。DNA数据存储规模是前所未有的:同样的LTO盒式磁带空间,DNA位的数量是LTO-9磁带的10万倍。DNA的持久性和分子结构的一致性非常适合长期档案存储。此外,DNA在电力、空间和可持续性方面也是一种对环境友好的介质,这将大大降低生态系统的负担。
海量数据与合成DNA的结合,提供了一种新的存储方式,它能从根本上改变存储的规模和时间,保存我们的数字遗产,也为提取、甚至创造或发现新知识提供了更多可能性。
原文公众号:上海市生物工程学会

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 2
2 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)