PyTorch实现Seq2Seq模型详解
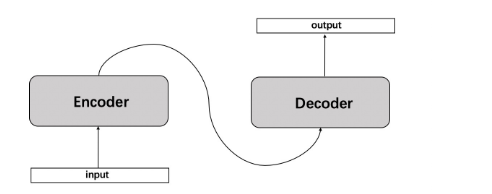
Seq2Seq是一种循环神经网络的变种,是一种端到端的模型,包括 Encoder编码器和 Decoder解码器部分,在nlp任务中是一种重要的模型,在翻译,文本自动摘要生成和机器人自动问答以及一些回归预测任务上有着广泛的运用。Seq2Seq其实就是结构的网络,它的输入是一个序列,输出也是一个序列。在Encoder编码中,将序列转换成一个固定长度的向量,然后通过Decoder将该向量转换成我们想要的
Seq2Seq模型介绍以及Pytorch版本代码详解
一、Seq2Seq模型的概述
Seq2Seq是一种循环神经网络的变种,是一种端到端的模型,包括 Encoder编码器和 Decoder解码器部分,在nlp任务中是一种重要的模型,在翻译,文本自动摘要生成和机器人自动问答以及一些回归预测任务上有着广泛的运用。
Seq2Seq其实就是
Encoder-Decoder
结构的网络,它的输入是一个序列,输出也是一个序列。在Encoder编码中,将序列转换成一个固定长度的向量,然后通过Decoder将该向量转换成我们想要的序列输出出来

Encoder和Decoder一般都是RNN,通常为LSTM或者GRU
二、Seq2Seq模型的结构
2.1 模型结构
针对目前
RNN网络
来说常见的任务来分,主要是有三种情况;
(1).
多对多, N vs N
, 包括N个输入和N个输出,输入和输出序列中长度是相等的,适用于词性标注任务和语言模型训练任务
(2).
一对多, 1 vs N,
包括1个输入和N个输出,一般的是输入X传给第一个神经元,或者是同样传递给所有的神经元,适用于,图像生成文字,小说、影视类型 生成相应的小说
(3).
多对一, N vs 1,
有 N 个输入
x
1,
x
2, …,
x
N,和一个
输出
y,适用于,序列分类任务,一段语言,一段文字,情感分析等
**常见的三种RNN结构,对于输入和输出都是有一定长度限制,但是在实际情况中,长度是不固定的,比如,机器翻译中,翻译前后的句子的长度是不一样的,对话系统中,问句和答案的长度也是不一致的,进而 一种新的 RNN结构 Seq2Seq的模型诞生了。包括两个部分,
Encoder**
用于编码序列的信息,将任意长度的序列信息编码到一个向量
c
里。而
Decoder
是解码器,解码器得到上下文信息向量
c
之后可以将信息解码,并输出为序列。Seq2Seq 模型结构有很多种,下面是几种比较常见的:
(1).

(2).

(3).

三种seq2seq的模型结构中的 Encoder 编码层都是一样的,主要的是 Decoder 不一样
2.2 编码器Encoder 和解码器 Decoder
1. 编码器Encoder
**上文中简单说明了三种不同的seq2seq结构,Encoder的结构都是相同的,主要是Decoder不一样。Encoder的输入接受输入X,最终输出一个编码,
表示所有的上下文信息向量C
,Decoder主要输入向量C,然后解码出需要的信息**

上下文信息向量C
,可以直接使用最后一个神经元输出的隐层状态
;也可以在
后面进行某种变化后输出;
上下文信息向量C
,也可以使用所有的隐层状态
,
,
,…,
,进行加权平均得到,总之可以尝试多种变换,得到最终的输出C
2. 解码器 Decoder
**第一种Decoder,
上文Decoder中有三种不同结构,从上文得到第一种形式;**

红色的C 表示Encoder的编码输出,这种结构比较简单,直接将
向量C
作为 Decoder的初始隐藏状态 ,不接受其他的x输入,后续Decoder中只是接受上一个神经元的隐层状态
输入
第二种Decoder

第二种Decoder使用 初始化的隐层状态信息
,Encoder编码输出的向量c 不在作为Decoder的隐层状态输入,而是作为RNN 每一个神经元的输入,从上文可以看到Decoder中每一个神经元都有向量C作为输入
第三种Decoder

第三种Decoder 结构和第二种类似,只是在输入部分多输入上一个神经元的输出,每一个神经元的输入包括: 上一个神经元的隐层向量
,上一个神经元的的输出
,当前的输入C(之前Encoder编码输出), 第一个输入
,一般是句子的起始位置embedding ,后面讲解代码会详细说明
三、Seq2Seq模型的代码讲解
本小结主要是结合前面的第一种seq2seq的模型 来实现下简单的机器翻译任务,结合下图来简单的介绍下(图片来至于网络)

从上文得到信息,seq2seq模型有三个变量,一个是Encoder 编码层的输入,
enc_input
变量
一个是 Decoder编码层的输入
dec_input
, 另一个是Decoder的输出,
dec_output
Context是经过Encoder 编码得到的向量C,表示结束符号,用E 表示, 表示起始符号,用S表示
下图代码中,都已经添加了注释了
问题分析:
(1). Train过程中,Decoder什么时候终止?:
训练过程中,Decoder的长度事先计算好的,输出到已知规定长度,即可输出,计算loss
(2). Test 过程中,Decoder 怎么计算终止,什么时候停止?:
测试过程中,Decoder的输入是特定长度的,无意义符号P占位符,假如输出的Decoder编码中有多个end符号E,最终输出,计算到第一个E符号为止
import numpy as np
import torch
import torch.nn as nn
import pdb
# S: Symbol that shows starting of decoding input
# E: Symbol that shows starting of decoding output
# P: Symbol that will fill in blank sequence if current batch data size is short than time steps, pad 补充,不够长度就pad
## seq_data = [['man', 'women'], ['black', 'white']]
def make_batch():
input_batch, output_batch, target_batch = [], [], []
for seq in seq_data:
for i in range(2):
seq[i] = seq[i] + 'P' * (n_step - len(seq[i])) ### 不够长度的 补充pad
print(" seq[i] =",seq[i])
input = [num_dic[n] for n in seq[0]] ## seq = ['manPP', 'women']
output = [num_dic[n] for n in ('S' + seq[1])]
# output = [num_dic[n] for n in ('S' + 'P' * n_step)] ## test is ok ?
target = [num_dic[n] for n in (seq[1] + 'E')] ### 表示输出结果
input_batch.append(np.eye(n_class)[input]) ## np.eye(n_class)[input] 生成 one-hot词向量 5*29
output_batch.append(np.eye(n_class)[output])
target_batch.append(target) # not one-hot
# make tensor
return torch.FloatTensor(input_batch), torch.FloatTensor(output_batch), torch.LongTensor(target_batch)
# make test batch 测试数据构建
def make_testbatch(input_word):
input_batch, output_batch = [], []
input_w = input_word + 'P' * (n_step - len(input_word))
input = [num_dic[n] for n in input_w]
output = [num_dic[n] for n in ('S' + 'P' * n_step)]
input_batch = np.eye(n_class)[input]
output_batch = np.eye(n_class)[output]
return torch.FloatTensor(input_batch).unsqueeze(0), torch.FloatTensor(output_batch).unsqueeze(0)
# Model
class Seq2Seq(nn.Module):
def __init__(self):
super(Seq2Seq, self).__init__()
self.enc_cell = nn.RNN(input_size=n_class, hidden_size=n_hidden, dropout=0.5)
self.dec_cell = nn.RNN(input_size=n_class, hidden_size=n_hidden, dropout=0.5)
self.fc = nn.Linear(n_hidden, n_class)
def forward(self, enc_input, enc_hidden, dec_input):
enc_input = enc_input.transpose(0, 1) # enc_input: [max_len(=n_step, time step), batch_size, n_class] (6,5,29)-> (5,6,29)
dec_input = dec_input.transpose(0, 1) # dec_input: [max_len(=n_step, time step), batch_size, n_class]
# enc_states : [num_layers(=1) * num_directions(=1), batch_size, n_hidden]
_, enc_states = self.enc_cell(enc_input, enc_hidden) ## 输出隐层的向量
# outputs : [max_len+1(=6), batch_size, num_directions(=1) * n_hidden(=128)]
outputs, _ = self.dec_cell(dec_input, enc_states)
model = self.fc(outputs) # model : [max_len+1(=6), batch_size, n_class]
return model
if __name__ == '__main__':
n_step = 5 ##长度
n_hidden = 128
char_arr = [c for c in 'SEPabcdefghijklmnopqrstuvwxyz']
num_dic = {n: i for i, n in enumerate(char_arr)}
seq_data = [['man', 'man'], ['black', 'white'], ['king', 'queen'], ['girl', 'boy'], ['up', 'down'], ['high', 'low']]
n_class = len(num_dic)
batch_size = len(seq_data)
model = Seq2Seq()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
input_batch, output_batch, target_batch = make_batch()
for epoch in range(5000):
# make hidden shape [num_layers * num_directions, batch_size, n_hidden]
hidden = torch.zeros(1, batch_size, n_hidden) ## 隐层向量初始化
# pdb.set_trace()
optimizer.zero_grad()
# input_batch : [batch_size, max_len(=n_step, time step), n_class]
# output_batch : [batch_size, max_len+1(=n_step, time step) (becase of 'S' or 'E'), n_class]
# target_batch : [batch_size, max_len+1(=n_step, time step)], not one-hot
output = model(input_batch, hidden, output_batch)
# output : [max_len+1, batch_size, n_class]
output = output.transpose(0, 1) # [batch_size, max_len+1(=6), n_class]
loss = 0
for i in range(0, len(target_batch)):
# output[i] : [max_len+1, n_class, target_batch[i] : max_len+1]
loss += criterion(output[i], target_batch[i])
if (epoch + 1) % 1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
loss.backward()
optimizer.step()
print(' now is starting test ....')
# Test
def translate(word):
input_batch, output_batch = make_testbatch(word)
# make hidden shape [num_layers * num_directions, batch_size, n_hidden]
hidden = torch.zeros(1, 1, n_hidden) ## 隐层向量初始化
output = model(input_batch, hidden, output_batch)
# output : [max_len+1(=6), batch_size(=1), n_class]
predict = output.data.max(2, keepdim=True)[1] # select n_class dimension get index
decoded = [char_arr[i] for i in predict]
end = decoded.index('E')
translated = ''.join(decoded[:end])
return translated.replace('P', '')
print('test')
print('man ->', translate('man'))
print('mans ->', translate('mans'))
print('king ->', translate('king'))
print('black ->', translate('black'))
print('ups ->', translate('ups'))
Referenced:
Seq2Seq的PyTorch实现 - 云+社区 - 腾讯云

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)