风格迁移adaIN 和DiT的adaLN
BN主要缺点是对batchsize的大小比较敏感,由于每次计算均值和方差是在一个batch上,所以如果batchsize太小,则计算的均值、方差不足以代表整个数据分布。因为在图像风格化中,生成结果主要依赖于某个图像实例,所以对整个batch归一化不适合图像风格化中,因而对HW做归一化。可以加速模型收敛,并且保持每个图像实例之间的独立。LayerNorm:channel方向做归一化,算CxHxW的均
BN、LN、IN、GN的区别
- NLP领域和音频领域很像,只有[B,T,C]维度,因为每个batch中相同位置的元素大概率不是一个类别,直接做batch norm 效果会比较差,更适合单个样本内部做layer norm;
- 音频的时间维度如果被压缩,计算得到==【B,1,C】的统计特征,保留了不同channel的特征,压缩了随时间变化的特征,更多统计的是单个音频全局不变的特征,比如音色;如果对C维度进行压缩,得到【B,T,1】==,音频各个频率域的区别被抹掉;时间维度的信息变化很大,得到的可能更偏向于内容维度的特征;

- NLP中的layer norm实现
import torch
batch_size, seq_size, dim = , ,
embedding = torch.randn(batch_size, seq_size, dim)
layer_norm = torch.nn.LayerNorm(dim, elementwise_affine = False)
print("y: ", layer_norm(embedding))
eps: float = 0.00001
mean = torch.mean(embedding[:, :, :], dim=(-1), keepdim=True)
var = torch.square(embedding[:, :, :] - mean).mean(dim=(-1), keepdim=True)
print("mean: ", mean.shape)
print("y_custom: ", (embedding[:, :, :] - mean) / torch.sqrt(var + eps))
- 更适合做batch-norm 的样本类型

 - BatchNorm:batch方向做归一化,算NxHxW的均值,对小batchsize效果不好;BN主要缺点是对batchsize的大小比较敏感,由于每次计算均值和方差是在一个batch上,所以如果batchsize太小,则计算的均值、方差不足以代表整个数据分布。- LayerNorm:channel方向做归一化,算CxHxW的均值,主要对RNN(处理序列)作用明显,目前大火的Transformer也是使用的这种归一化操作;- InstanceNorm:一个channel内做归一化,算H*W的均值,用在风格化迁移;因为在图像风格化中,生成结果主要依赖于某个图像实例,所以对整个batch归一化不适合图像风格化中,因而对HW做归一化。可以加速模型收敛,并且保持每个图像实例之间的独立。- GroupNorm:将channel方向分group,然后每个group内做归一化,算(C//G)HW的均值;这样与batchsize无关,不受其约束,在分割与检测领域作用较好。
- BatchNorm:batch方向做归一化,算NxHxW的均值,对小batchsize效果不好;BN主要缺点是对batchsize的大小比较敏感,由于每次计算均值和方差是在一个batch上,所以如果batchsize太小,则计算的均值、方差不足以代表整个数据分布。- LayerNorm:channel方向做归一化,算CxHxW的均值,主要对RNN(处理序列)作用明显,目前大火的Transformer也是使用的这种归一化操作;- InstanceNorm:一个channel内做归一化,算H*W的均值,用在风格化迁移;因为在图像风格化中,生成结果主要依赖于某个图像实例,所以对整个batch归一化不适合图像风格化中,因而对HW做归一化。可以加速模型收敛,并且保持每个图像实例之间的独立。- GroupNorm:将channel方向分group,然后每个group内做归一化,算(C//G)HW的均值;这样与batchsize无关,不受其约束,在分割与检测领域作用较好。
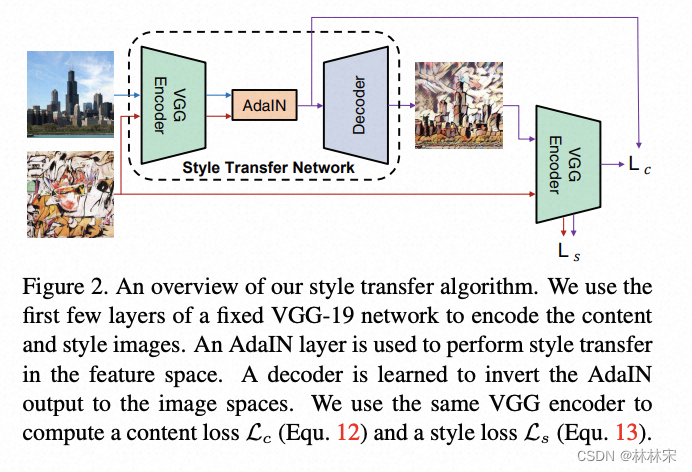
图像风格迁移adaIN


- 作者做实验,对IN 和BN 的loss区别原因进行对比,发现图片计算的均值/方差代表图片的风格;因此设计AdaIN 对图片风格归一化,然后再迁移到目标风格;
def forward(self, content, style, alpha=1.0):
assert 0 <= alpha <= 1
style_feats = self.encode_with_intermediate(style)
content_feat = self.encode(content)
t = adain(content_feat, style_feats[-1])
t = alpha * t + (1 - alpha) * content_feat # 控制内容和风格的比例
g_t = self.decoder(t)
g_t_feats = self.encode_with_intermediate(g_t)
loss_c = self.calc_content_loss(g_t_feats[-1], t)
loss_s = self.calc_style_loss(g_t_feats[0], style_feats[0])
for i in range(1, 4):
loss_s += self.calc_style_loss(g_t_feats[i], style_feats[i])
return loss_c, loss_s
- adain 只用在encoder-decoder 之间;实验发现encoder-adain-decoder(IN) 效果会变差;
- 控制内容和风格的比例 t = alpha * t + (1 - alpha) * content_feat
DiT adaLN

import numpy as np
class LayerNorm:
def __init__(self, epsilon=1e-6):
self.epsilon = epsilon
def __call__(self, x: np.ndarray, gamma: np.ndarray, beta: np.ndarray) -> np.ndarray:
"""
Args:
x (np.ndarray): shape: (batch_size, sequence_length, feature_dim)
gamma (np.ndarray): shape: (batch_size, 1, feature_dim), generated by condition embedding
beta (np.ndarray): shape: (batch_size, 1, feature_dim), generated by condition embedding
return:
x_layer_norm (np.ndarray): shape: (batch_size, sequence_length, feature_dim)
"""
_mean = np.mean(x, axis=-1, keepdims=True)
_std = np.var(x, axis=-1, keepdims=True)
x_layer_norm = self.gamma * (x - _mean / (_std + self.epsilon)) + self.beta
return x_layer_norm
class DiTAdaLayerNorm:
def __init__(self,feature_dim, epsilon=1e-6):
self.epsilon = epsilon
self.weight = np.random.rand(feature_dim, feature_dim * 2)
def __call__(self, x, condition):
"""
Args:
x (np.ndarray): shape: (batch_size, sequence_length, feature_dim)
condition (np.ndarray): shape: (batch_size, 1, feature_dim)
Ps: condition = time_cond_embedding + class_cond_embedding
return:
x_layer_norm (np.ndarray): shape: (batch_size, sequence_length, feature_dim)
"""
affine = condition @ self.weight # shape: (batch_size, 1, feature_dim * 2)
gamma, beta = np.split(affine, 2, axis=-1)
_mean = np.mean(x, axis=-1, keepdims=True)
_std = np.var(x, axis=-1, keepdims=True)
x_layer_norm = gamma * (x - _mean / (_std + self.epsilon)) + beta
return x_layer_norm
class DiTBlock:
def __init__(self, feature_dim):
self.MultiHeadSelfAttention = lambda x: x # mock multi-head self-attention
self.layer_norm = LayerNorm()
self.MLP = lambda x: x # mock multi-layer perceptron
self.weight = np.random.rand(feature_dim, feature_dim * 6)
def __call__(self, x: np.ndarray, time_embedding: np.ndarray, class_emnedding: np.ndarray) -> np.ndarray:
"""
Args:
x (np.ndarray): shape: (batch_size, sequence_length, feature_dim)
time_embedding (np.ndarray): shape: (batch_size, 1, feature_dim)
class_emnedding (np.ndarray): shape: (batch_size, 1, feature_dim)
return:
x (np.ndarray): shape: (batch_size, sequence_length, feature_dim)
"""
condition_embedding = time_embedding + class_emnedding
affine_params = condition_embedding @ self.weight # shape: (batch_size, 1, feature_dim * 6)
gamma_1, beta_1, alpha_1, gamma_2, beta_2, alpha_2 = np.split(affine_params, 6, axis=-1)
x = x + alpha_1 * self.MultiHeadSelfAttention(self.layer_norm(x, gamma_1, beta_1))
x = x + alpha_2 * self.MLP(self.layer_norm(x, gamma_2, beta_2))
return x
- class condition的引入,用adaLN替换常规的LN。adaLN和adaLN-Zero的区别在于,用于scale的均值方差是随机初始化的,还是可以训练的;

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)