MedCLIP:CLIP + 医学语义匹配策略,解决模型误将不同患者同病症视为不相关
MedCLIP 方法通过一种创新的方式,使得我们可以使用更多以前无法使用的数据,同时减少了假阴性错误判断的情况,从而提高了医学图像分析的准确性和效率。现有的视觉-文本对比学习,如CLIP的目标是匹配配对的图像和标题嵌入,同时将其他嵌入推开,这改善了表示的可转移性并支持零样本预测。但如果这些图像和文本来自不同的数据集(比如不同的患者),即使它们显示的是相同的病症(如肺炎),模型也会认为它们是不相关的
MedCLIP:CLIP + 医学语义匹配策略,解决模型误将不同患者同病症视为不相关
提出背景
论文:MedCLIP: Contrastive Learning from Unpaired Medical Images and Text
代码:https://github.com/RyanWangZf/MedCLIP
现有的视觉-文本对比学习,如CLIP的目标是匹配配对的图像和标题嵌入,同时将其他嵌入推开,这改善了表示的可转移性并支持零样本预测。
然而,医学图像-文本数据集的数量远低于互联网上的普通图像和标题。
此外,以前的方法遇到了许多假阴性,即来自不同患者的图像和报告可能具有相同的语义,但错误地被视为阴性。
医生们使用X光图来诊断肺炎。
现在,我们有两张X光图,每张都显示了肺炎的特征,但这两张X光图来自不同的患者。

在使用CLIP这样的传统对比学习模型时,这种模型会试图找出图像和相对应的文本(比如诊断报告)之间的匹配关系。
但如果这些图像和文本来自不同的数据集(比如不同的患者),即使它们显示的是相同的病症(如肺炎),模型也会认为它们是不相关的。
这就是所谓的“假阴性”——实际上它们是相关的,因为都显示了肺炎,但模型错误地将它们归类为不相关。
这样的错误会影响模型的判断效果,使得模型在实际应用中的准确性和有用性下降。
因此,医学领域在使用这种模型时需要特别小心,以确保不会因为这种假阴性错误而错过正确的诊断信息。
我们用基于医学知识的语义匹配损失替换InfoNCE损失,以消除对比学习中的假阴性。
此外,我们为多模态对比学习解耦图像和文本,从而以低成本将可用训练数据扩展到组合量级。
目前在医学图像分析领域存在两个主要问题:
-
可用数据有限:许多医学图像数据集只提供了疾病的标签(比如“肺炎”),而没有提供详细的诊断报告。
因为有些研究方法需要同时使用图像和对应的详细文本报告,所以如果只有图像没有文本,或者只有文本没有图像,这些数据就不能被这些方法使用。
-
解耦图像和文本:MedCLIP方法不需要每个图像都必须有对应的文本报告,反之亦然。
这样就可以使用更多原本因为不是成对的而无法使用的图像和文本数据,大大增加了可以用于训练的数据量。
-
基于医学知识的多模态学习:这个方法通过利用医学知识,而不是单纯增加数据量,来提升模型对医学图像和文本的理解能力。
MedCLIP 方法通过一种创新的方式,使得我们可以使用更多以前无法使用的数据,同时减少了假阴性错误判断的情况,从而提高了医学图像分析的准确性和效率。
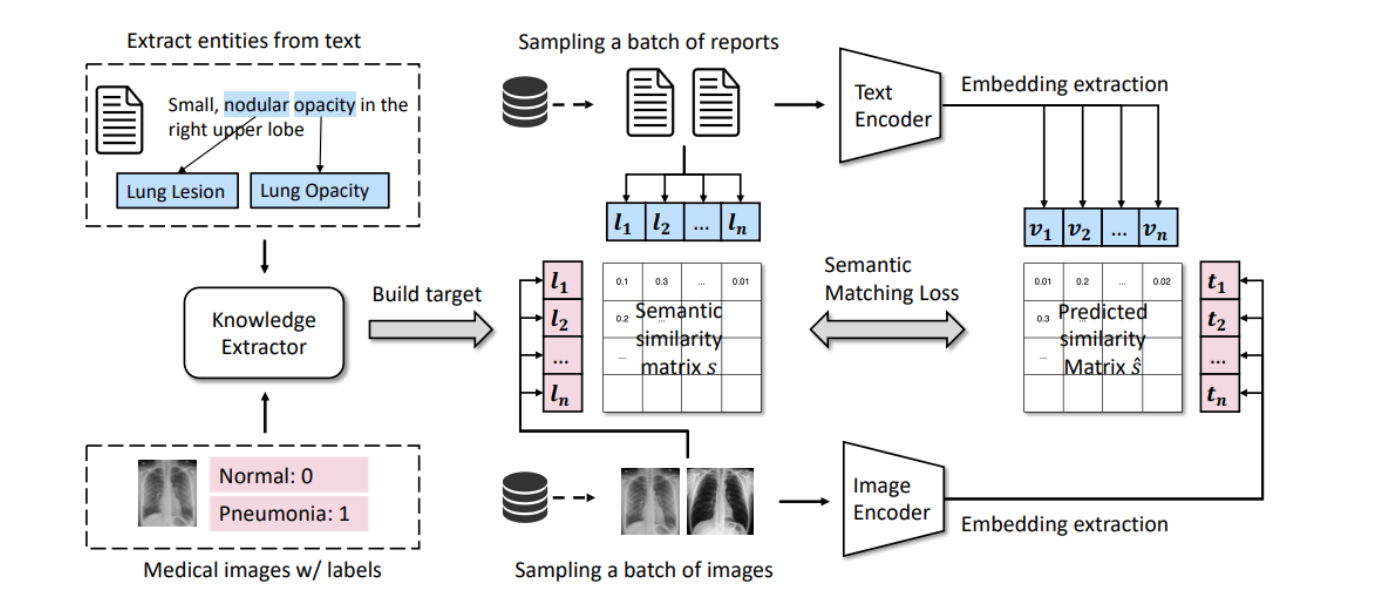
流程图

这张图展示了MedCLIP模型的工作流程。
MedCLIP是一个用于处理医学图像和文本数据的对比学习系统。下面是该图描述的各个步骤:
-
实体提取:
- 从医学文本中提取关键实体(如图中示例文本“Small, nodular opacity in the right upper lobe”中提取了"Lung Lesion"和"Lung Opacity"作为关键词)。
- 这些实体用于进一步分析和构建知识库。
-
目标构建与知识提取:
- 使用提取的实体构建目标,即知识提取器,它将帮助识别和关联图像和文本数据集中的相关信息。
-
医学图像与标签:
- 同时,系统从医学图像数据集中采样一批图像(图中的示例包括标记为“Normal: 0”和“Pneumonia: 1”的图像)。
-
编码器与嵌入提取:
- 文本编码器和图像编码器分别处理文本数据和图像数据,将它们转化为嵌入(即数学表达形式),便于机器处理。
-
语义相似性矩阵的构建:
- 根据提取的文本实体和图像标签构建一个语义相似性矩阵,该矩阵衡量不同医学实体之间的相似性。
-
语义匹配损失计算:
- 利用预测的相似性矩阵计算语义匹配损失,以优化模型的性能。这涉及比较实际的相似性(从知识提取器得出)和模型预测的相似性。
这个工作流程旨在通过构建和利用语义相似性矩阵,使得MedCLIP能够灵活地配对任意采样的图像和文本,无论它们是否原本是配对的。
解法拆解
MedCLIP由以下几个部分组成:
(1)构建语义相似性矩阵的知识提取;
(2)提取嵌入的视觉和文本编码器;
(3)训练整个模型的语义匹配损失。
子解法1:知识提取
MedCLIP利用知识提取组件构建语义相似性矩阵。
- 之所以使用知识提取,是因为需要从大量的非配对数据中提取有用信息,这有助于处理医学领域中数据配对困难的问题。
子解法2:视觉和文本编码器
MedCLIP包括一个视觉编码器和一个文本编码器,用于提取图像和文本的嵌入。
- 之所以使用视觉和文本编码器,是因为在对比学习中,精确的嵌入向量是必需的,它们能够有效地表示视觉和文本数据的特征。
子解法3:语义匹配损失
MedCLIP通过语义匹配损失来训练整个模型,优化模型对医学图像和文本的匹配准确性。
- 之所以使用语义匹配损失,是因为它可以直接针对医学语义相似性进行优化,这对于提高模型在实际医学应用中的性能至关重要。
这些子解法构成了解决问题的逻辑链条,每个子解法都针对特定的特征或问题提供了解决方案。
例如,在解决数据非配对的问题时,知识提取和语义匹配损失相结合,能够充分利用现有的医学图像和文本数据,无论它们是否配对。
这种方法不仅提高了数据的利用率,也增强了模型的适应性和准确性。
MedCLIP 的目标是利用医学专业知识提高 CLIP 模型在医学领域的适用性和准确性,特别是在处理医学图像和相关文本数据时,如X光图和病历报告。这使得 MedCLIP 特别适用于如自动病理检测、医学教育和临床决策支持等任务。
MedCLIP 的架构和方法同样适用于处理眼底数据,如光学相干断层扫描(OCT)和眼底照相(fundus images)。
MedCLIP的输入主要包括两部分:医学图像和相关的医学文本(诊断报告、治疗方案)。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 28
28 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)