
万字长文详解如何构建自己的大模型
如今大模型百花齐放,关于大模型的文章也非常多,但是介绍如何从0开始构建自己的大模型的介绍比较少,本文系统性地介绍了如何选择合适的基座模型,以及如何使用自己的数据微调大模型。来源:知乎作者:绝密伏击链接:https://zhuanlan.zhihu.com/p/673308333。
随着大模型的快速发展,目前出现了各种各样的大模型,如OpenAI的GPT模型、Meta的Llama模型、百度的文心一言模型、科大讯飞的讯飞星火模型、百川的Baichuan-13B,阿里的Qwen-14B和Qwen-72B、清华的GLM。
本文将介绍如何部署大模型,包括环境安装和模型加载,并分享一些低成本的部署技巧,让读者可以在个人电脑上运行大模型。
本文的重点是如何通过有监督微调,构建自己的大模型,让大模型能够适应您的使用场景,发挥最大的价值。
一、选择基座模型
在大模型应用中,选择一款合适的基座模型非常关键,它要求既能达到优秀的效果,又能降低部署的成本。这样就可以方便地在私有数据上进行微调,并且实现低成本的部署。
根据开源评测平台OpenCompass的数据,目前综合能力最好的10个开源基座模型如表1-1所示。从表中可以看出,排名第一的是清华大学于2023年10月发布的60亿参数的大模型ChatGLM3-6B。它在前10名中参数量最少,但是效果最佳,是选择基座模型的最佳候选。
表1-1 开源大模型(基座)评测排名(数据来源自OpenCompass)
| 模型 | 发布时间 | 所属机构 | 参数量 | 综合得分 |
|---|---|---|---|---|
| ChatGLM3-6B | 2023/10/27 | 清华大学 | 6B | 65.3 |
| Qwen-14B | 2023/9/25 | 阿里巴巴 | 14B | 62.4 |
| XunYuan-70B | 2023/9/22 | 度小满 | 70B | 60.0 |
| InternLM-20B | 2023/9/20 | 商汤科技 | 20B | 59.3 |
| LLaMA-2-70B | 2023/7/19 | Meta | 70B | 57.4 |
| TigerBot-70B-Base-V1 | 2023/9/6 | 虎博科技 | 70B | 55.7 |
| Qwen-7B | 2023/9/25 | 阿里巴巴 | 7B | 55.2 |
| LLaMA-65B | 2023/2/24 | Meta | 65B | 51.9 |
| Mistral-7B-v0.1 | 2023/9/27 | Mistral AI | 7B | 51.2 |
| TigerBot-13B-Base-V1 | 2023/8/8 | 虎博科技 | 13B | 50.3 |
1.1 环境安装
ChatGLM3是由智谱AI和清华大学KEG实验室联合发布的新一代对话预训练模型,其中ChatGLM3-6B是开源的对话模型,具有以下特性。
-
更强大的基础模型:ChatGLM3-6B基于ChatGLM3-6B-Base进行微调,后者使用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在不同角度的数据集上测评显示,ChatGLM3-6B-Base在10B以下的基础模型中表现最优。
-
更完整的功能支持:ChatGLM3-6B采用了全新设计的 提示(Prompt) 格式,除了支持多轮对话外,还支持工具调用、代码执行等复杂场景。
-
更全面的开源序列:除了对话模型ChatGLM3-6B外,还开源了基础模型ChatGLM3-6B-Base、长文本对话模型ChatGLM3-6B-32K。
为了使用ChatGLM3-6B作为基座模型,首先需要安装环境,可以从gitHub上克隆代码仓库,然后使用pip安装依赖。
git clone https://github.com/THUDM/ChatGLM3
cd ChatGLM3
pip install -r requirements.txt
其中transformers库版本推荐为4.30.2,torch推荐使用2.0及以上的版本,以获得最佳的推理性能。
1.2 模型加载
要想加载 ChatGLM3-6B 模型,有多种方式可以选择,例如代码调用、网页版、命令行、工具调用等。下面先来看看如何通过代码调用的方式加载模型。
代码调用
可以使用下面的方式生成对话,只需调用ChatGLM3-6B模型即可,无须手动下载模型实现和参数,transformers会自动完成这些工作。
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True)
model = AutoModel.from_pretrained(
"THUDM/chatglm3-6b", trust_remote_code=True, device='cuda')
model = model.eval()
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
你好 !我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。
response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
print(response)
晚上睡不着可能会让你感到焦虑或不舒服,但以下是一些可以帮助你入睡的方法:
1. 制定规律的睡眠时间表:保持规律的睡眠时间表可以帮助你建立健康的睡眠习惯,使你更容易入睡。尽量在每天的相同时间上床,并在同一时间起床。
2. 创造一个舒适的睡眠环境:确保睡眠环境舒适,安静,黑暗且温度适宜。可以使用舒适的床上用品,并保持房间通风。
3. 放松身心:在睡前做些放松的活动,例如泡个热水澡,听些轻柔的音乐,阅读一些有趣的书籍等,有助于缓解紧张和焦虑,使你更容易入睡。
4. 避免饮用含有咖啡因的饮料:咖啡因是一种刺激性物质,会影响你的睡眠质量。尽量避免在睡前饮用含有咖啡因的饮料,例如咖啡,茶和可乐。
5. 避免在床上做与睡眠无关的事情:在床上做些与睡眠无关的事情,例如看电影,玩游戏或工作等,可能会干扰你的睡眠。
6. 尝试呼吸技巧:深呼吸是一种放松技巧,可以帮助你缓解紧张和焦虑,使你更容易入睡。试着慢慢吸气,保持几秒钟,然后缓慢呼气。
如果这些方法无法帮助你入睡,你可以考虑咨询医生或睡眠专家,寻求进一步的建议
完整的模型实现在Hugging Face Hub。如果你的网络环境较差,下载模型参数可能会花费较长时间甚至失败。此时可以先将模型下载到本地,然后从本地加载。从 Hugging Face Hub下载模型需要先安装Git LFS。
网页版示例
您可以通过下面的命令,启动一个基于Gradio的网页版示例。
python web_demo.py
当ChatGLM3-6B模型成功启动,您就可以在网页上看到图1-1所示的界面,并开始与模型对话。
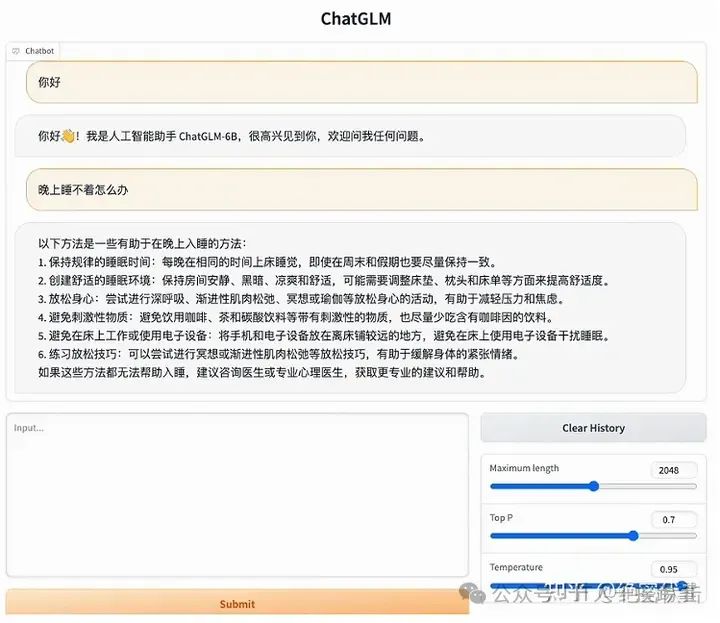
图1-1 基于Gradio启动ChatGLM3-6B
除了上面的方式外,还可以通过下面的命令,启动一个基于Streamlit的网页版示例。
streamlit run web_demo2.py
模型启动成功后,您可以在网页上看到图1-2显示的界面。您可以在左边的区域调整模型的参数,也可以在中间的区域和ChatGLM3-6B进行自由对话。
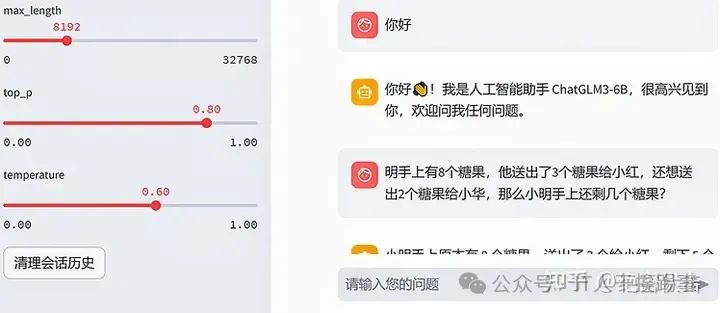
图1-2 基于Streamlit启动ChatGLM3-6B
命令行示例
运行下面代码,程序会在命令行中进行交互式的对话,在命令行中输入指示并回车即可生成回复,输入clear可以清空对话历史,输入stop终止程序。
python cli_demo.py
模型启动成功后,您可以在命令行看到如图1-3所示的界面。

图1-3 基于命令行启动ChatGLM3-6B
二、低成本部署
前面介绍了多种模型加载的方式,包括网页版和命令行版。但是这些方式都需要高性能的GPU,对于普通用户来说,不太方便。因此,下面介绍如何低成本地部署ChatGLM3-6B,让更多用户能够体验它。
2.1 模型量化
模型默认以FP16精度加载,需要约13GB的显存。如果您的GPU显存不足,您可以选择以量化方式加载模型,具体方法如下。
model = AutoModel.from_pretrained("THUDM/chatglm3-6b",trust_remote_code=True).quantize(4)
量化会降低一些模型的性能,但是测试结果表明,ChatGLM3-6B 在 4-比特量化下仍然能够生成自然流畅的对话。
2.2 CPU部署
您也可以在CPU上运行模型,但是推理速度会慢很多。具体方法如下(需要至少32GB 的内存)。
model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True).float()
2.3 Mac部署
如果您的Mac使用了Apple Silicon或AMD GPU,您可以使用MPS后端在GPU上运行 ChatGLM3-6B。您需要按照Apple的官方说明安装PyTorch-Nightly(请注意版本号应该是 2.x.x.dev2023xxxx,而不是 2.x.x)。目前MacOS上只支持从本地加载模型。
model = AutoModel.from_pretrained("your local path", trust_remote_code=True).to('mps')
加载半精度的 ChatGLM3-6B 模型需要约 13GB 的内存。如果您的机器内存较小(比如 16GB 的 MacBook Pro),在内存不足时会使用硬盘上的虚拟内存,这会导致推理速度大幅降低。
2.4 多卡部署
如果您有多张GPU,但是每张GPU的显存都不够加载完整的模型,您可以使用模型并行的方式,将模型分配到多张GPU上。您需要先安装accelerate: pip install accelerate。这样,您就可以在两张GPU上运行模型了。您可以根据您的需要,修改num_gpus参数来指定使用的GPU数量。默认情况下,模型会平均分配到各个GPU上,您也可以通过device_map参数来自定义分配方式。
from utils import load_model_on_gpus
model = load_model_on_gpus("THUDM/chatglm3-6b", num_gpus=2)
三、构建自己的大模型
在了解了如何部署模型的方法后,接下来使用自己的数据,对大模型进行微调,赋予它新的能力。
以广告词生成为例,下面介绍如何对大模型进行微调,让它生成更符合要求的广告词。由于ChatGLM3-6B的微调代码尚未开源,因此无法直接使用它,但是可以参考ChatGLM2-6B和ChatGLM-6B的微调代码,只需修改相应的模型路径和参数即可。
在微调之前,先来看看ChatGLM3-6B在没有微调的情况下,生成广告词的效果,如图3-1所示。从图中可以看出,生成的广告词过长,不够简洁,而且结尾都是“快来抢购这款…,让您的时尚之路更加精彩!”,格式单一,缺乏创意。为了改善这一问题,接下来选择ADGEN数据集,对模型进行微调。
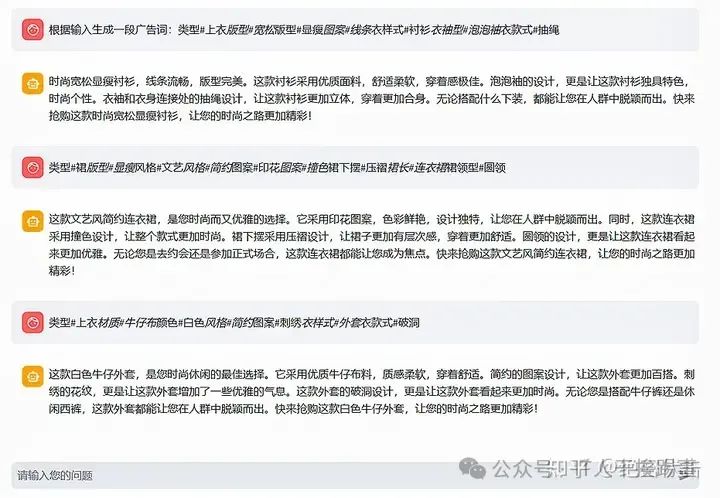
图3-1 ChatGLM3-6B根据输入生成广告词
3.1 数据准备
首先下载ADGEN数据集,这是一个用于生成广告文案的数据集。它的任务是根据输入的商品信息(content)生成一段吸引人的广告词(summary)。您可以从Google Drive或者Tsinghua Cloud下载预处理好的ADGEN数据集,并将解压后的AdvertiseGen文件夹放到当前目录下。把AdvertiseGen文件夹里的数据分成训练集和验证集,分别保存为train.json和dev.json文件,数据的格式如图3-2所示。

图3-2 广告词数据集数据格式
例如,输入“类型#上衣版型#宽松版型#显瘦图案#线条衣样式#衬衫衣袖型#泡泡袖衣款式#抽绳”,输出为“这件衬衫的款式非常的宽松,利落的线条可以很好的隐藏身材上的小缺点,穿在身上有着很好的显瘦效果。领口装饰了一个可爱的抽绳,漂亮的绳结展现出了十足的个性,配合时尚的泡泡袖型,尽显女性甜美可爱的气息。”
3.2 有监督微调
如果想有监督微调ChatGLM3-6B,您需要自己写一套代码,因为它的微调代码还没有公开。不过,我们也可以借鉴ChatGLM2-6B的微调代码,它已经开源了,只需要调整一些细节就行。您可以先从网上下载ChatGLM2-6B的代码。
下载好ChatGLM2-6B的代码后,需要把有监督微调的代码文件复制到ChatGLM3-6B的文件夹里。然后,把前面准备好的数据集也复制到ChatGLM3-6B的有监督微调文件夹里。
cp -r ChatGLM2-6B/ptuning ChatGLM3-6B/
cp –r AdvertiseGen ChatGLM3-6B/ptuning/
要进行全参数微调,您需要先安装deepspeed,还需要安装一些有监督微调需要的包。
pip install deepspeed
cd ptuning
pip install rouge_chinese nltk jieba datasets
准备好微调代码的环境后,还要修改一些微调代码的参数。
vim ds_train_finetune.sh
LR=1e-5
MASTER_PORT=$(shuf -n 1 -i 10000-65535)
deepspeed --num_gpus=8 --master_port $MASTER_PORT main.py \
--deepspeed deepspeed.json \
--do_train \
--preprocessing_num_workers 32 \
--train_file AdvertiseGen/train.json \
--test_file AdvertiseGen/dev.json \
--prompt_column content \
--response_column summary \
--model_name_or_path ../models/chatglm3-6b \
--output_dir output/adgen-chatglm3-6b-ft \
--overwrite_output_dir \
--max_source_length 512 \
--max_target_length 512 \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 1 \
--predict_with_generate \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate $LR \
--fp16
上面代码中的参数含义在表3-1中给出,您可以根据具体的任务和硬件环境进行调整。
| 参数 | 参数含义 |
|---|---|
| num_gpus | 使用的GPU数量 |
| deepspeed | deepspeed的配置文件 |
| preprocessing_num_workers | 数据预处理的线程数量 |
| train_file | 训练数据文件的路径 |
| test_file | 测试数据文件的路径 |
| prompt_column | 输入列的名称 |
| response_column | 输出列的名称 |
| model_name_or_path | 模型名称或路径 |
| output_dir | 输出模型参数的文件路径 |
| max_source_length | 最大输入长度 |
| max_target_length | 最大输出长度 |
| per_device_train_batch_size | 每个设备的训练批次大小 |
| per_device_eval_batch_size | 每个设备的评估批次大小 |
| gradient_accumulation_steps | 梯度累计 步数 |
| predict_with_generate | 是否使用生成模式进行预测 |
| logging_steps | 记录日志的步数 |
| save_steps | 保存模型的步数 |
| learning_rate | 学习率 |
| fp16 | 是否使用半精度浮点数进行训练 |
接下来需要调整main.py文件中的num_train_epoch参数(默认为3),该参数表示训练的轮数。
vim main.py
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
# datasets.utils.logging.set_verbosity(log_level)
transformers.utils.logging.set_verbosity(log_level)
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
# Log on each process the small summary:
training_args.num_train_epochs = 1
logger.info(f"Training/evaluation parameters {training_args}")
目前已经完成了训练数据的准备和代码的修改,接下来运行代码来开始微调模型。
bash ds_train_finetune.sh
当运行代码时,会遇到一个错误,提示:ChatGLMTokenizer类没有build_prompt方法。这是因为ChatGLM3-6B的ChatGLMTokenizer类没有实现这个方法。要解决这个问题,您可以参考ChatGLM2-6B中ChatGLMTokenizer类的build_prompt方法,按照相同的逻辑编写代码。
vim ../models/chatglm3-6b/tokenization_chatglm.py
# 在ChatGLMTokenizer类中实现build_prompt方法
def build_prompt(self, query, history=None):
if history is None:
history = []
prompt = ""
for i, (old_query, response) in enumerate(history):
prompt += "[Round {}]\n\n问:{}\n\n答:{}\n\n".format(
i + 1, old_query, response)
prompt += "[Round {}]\n\n问:{}\n\n答:".format(len(history) + 1, query)
return prompt
在Tokenizer类中添加了build_prompt方法的代码后,程序就可以正常运行了。
我们可以使用命令watch -n 1 nvidia-smi来监控GPU的使用情况。这个命令会每分钟刷新一次程序界面,显示GPU的使用率、显存的占用率和功耗等信息。图3-3展示了一个程序界面的截图。从图中可以看出,GPU使用率已经接近100%,显存占用约为57409MiB。这说明还有一些空间可以增加训练的批量大小或者输入输出的长度,以提高训练效率。
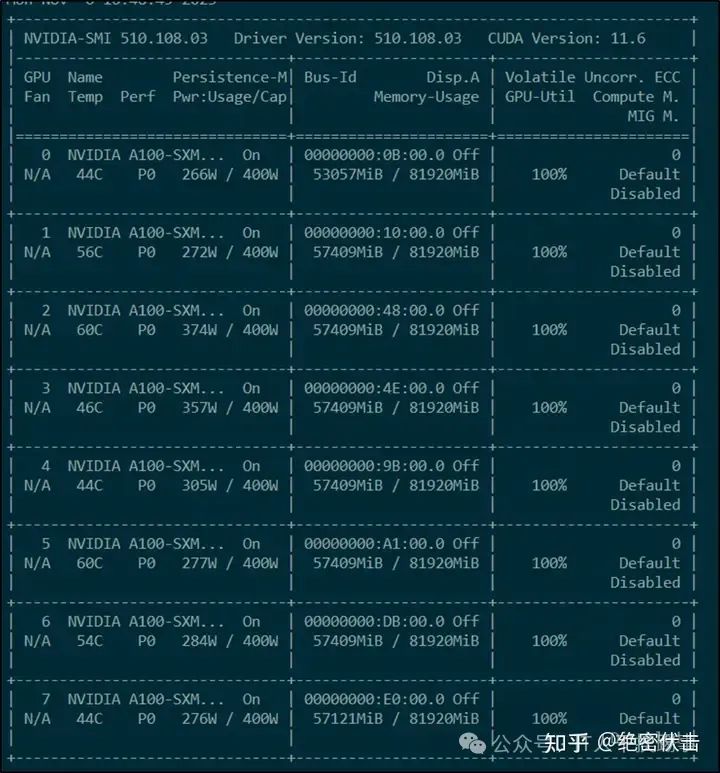
图3-3 微调过程中GPU使用情况
模型微调完成后,./output/adgen-chatglm3-6b-ft目录下会生成相应的文件,包含了模型的参数文件和各种配置文件,具体内容如下所示。以pytorch_model开头的文件是模型的参数文件。
tree ./output/adgen-chatglm3-6b-ft
├── all_results.json
├── checkpoint-1000
│ ├── config.json
│ ├── configuration_chatglm.py
│ ├── generation_config.json
│ ├── global_step1000
│ │ ├── mp_rank_00_model_states.pt
│ │ ├── zero_pp_rank_0_mp_rank_00_optim_states.pt
│ │ ├── zero_pp_rank_1_mp_rank_00_optim_states.pt
│ │ ├── zero_pp_rank_2_mp_rank_00_optim_states.pt
│ │ ├── zero_pp_rank_3_mp_rank_00_optim_states.pt
│ │ ├── zero_pp_rank_4_mp_rank_00_optim_states.pt
│ │ ├── zero_pp_rank_5_mp_rank_00_optim_states.pt
│ │ ├── zero_pp_rank_6_mp_rank_00_optim_states.pt
│ │ └── zero_pp_rank_7_mp_rank_00_optim_states.pt
│ ├── ice_text.model
│ ├── latest
│ ├── modeling_chatglm.py
│ ├── pytorch_model-00001-of-00002.bin
│ ├── pytorch_model-00002-of-00002.bin
│ ├── pytorch_model.bin.index.json
│ ├── quantization.py
│ ├── rng_state_0.pth
│ ├── rng_state_1.pth
│ ├── rng_state_2.pth
│ ├── rng_state_3.pth
│ ├── rng_state_4.pth
│ ├── rng_state_5.pth
│ ├── rng_state_6.pth
│ ├── rng_state_7.pth
│ ├── special_tokens_map.json
│ ├── tokenization_chatglm.py
│ ├── tokenizer_config.json
│ ├── trainer_state.json
│ ├── training_args.bin
│ └── zero_to_fp32.py
├── trainer_state.json
└── train_results.json
训练过程中,可以观察到每次迭代的时间,例如:[4:28:37<4:40:51, 6.39s/it],表示每次迭代需要6.39秒。因此,对于12万的数据,我们可以估算出微调所需的总时间为120000/16/8*6.39/3600 ≈ 1.66小时,其中16是批量大小,8是GPU的数量。大约1.66小时后,12万的数据就可以微调完成。
3.3 部署自己的大模型
新模型微调好后,就可以部署起来了。使用Streamlit启动微调后的模型。启动后,您可以看看模型生成的广告词效果,如图3-4所示。可以看出,模型的回答风格比微调前更加丰富多样。

图3-4 微调之后的模型
3.4 灾难遗忘问题
大模型的灾难遗忘是指在连续学习多个任务的过程中,学习新知识会导致模型忘记或破坏之前学习到的旧知识,从而使模型在旧任务上的性能急剧下降。这是一个机器学习领域的重要挑战,尤其是对于大规模语言模型和多模态大语言模型,它们需要在不同的数据集和领域上进行微调或适应。
使用广告数据集ADGEN对模型进行了微调,结果发现模型不仅忘记了之前学会的正常回答,甚至还出现了输出错误的情况。这是因为广告数据集和模型原来的训练数据分布相差太大,引起了模型的“灾难遗忘”现象。图3-5展示了微调后的模型,连简单的问答都无法回答了。

图3-5 微调之后出现了灾难遗忘现象
为了缓解灾难遗忘问题,我们可以使用其他数据来增强模型的泛化能力。例如,可以使用一个包含逻辑推理和问答类的数据集,用于和广告数据集一起进行微调。
比如我们构建的新数据集,它包含了一些逻辑推理和问答类的数据。您需要将这个文件转换成模型可以接受的输入格式。
新的数据集涵盖了数学应用题、选择题、填空题等多种不同类型的数据,比之前的广告数据集ADGEN更加丰富和多样。我们可以将这两个数据集合并在一起,对模型进行重新微调,以提高模型的泛化能力和稳定性。
将新的数据集和广告数据集ADGEN合并后,对模型进行重新训练。训练过程中,程序会定期输出验证集的损失值,反映模型的学习效果。将这些损失值绘制成曲线图,如图3-6所示。从图中可以看出,模型的验证集损失值呈现下降的趋势。在训练了一个完整的轮次后,停止训练,保存模型。
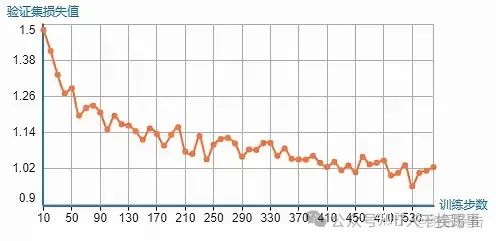
图3-6 训练过程中的验证集损失值
使用Streamlit来启动新训练的模型。模型启动后,下面检验一下新模型是否存在灾难遗忘的问题。如图3-7所示,新模型不仅能够回答正常的问题,还能够生成新的广告词,有效地缓解了灾难遗忘的现象。

图3-7 新训练的模型
新模型不仅能缓解灾难遗忘问题,还能回答更多的问题。例如,对于“亚历克鲍德温的孩子比克林特伊斯特伍德多吗?”这样的问题,旧模型无法给出答案,而新模型则能轻松回答。另外,新模型在其他问题上也有更好的表现,如图3-8所示。

图3-8 新旧模型对比
新模型在数学推理上有显著的优势,它能够正确地列出并解决一些经典的数学问题。例如,鸡兔同笼这个问题,如图3-9所示,旧模型只能得到一个方程,而忽略了另一个方程,导致计算结果出现错误。而新模型则能够得到两个方程,并用消元法求出正确的答案。旧模型不仅在列方程时遗漏了一个条件,而且在推理过程中还存在数值计算的失误,例如,当_x_ = 1, y = 7时,它给出的结果是_x_ + 2_y_ = 14,这显然是不正确的。

图3-9 旧模型回答鸡兔同笼问题
如图3-10所示,新模型的回答非常准确和完整。它不但能够根据题目条件列出两个方程,还能够正确地运用消元法求解方程,并得出正确的答案。新模型在数学应用题上的优异表现,主要得益于我们使用了一个包含大量数学推理题的新数据集进行有监督的微调,这使得模型在这类任务上具有更强的泛化能力。

图3-10 新模型回答鸡兔同笼问题
3.5 程序思维提示——解决复杂数值推理
大模型虽然在语言理解和数学推理等方面有着优异的性能,但是在数值计算方面却显得力不从心。例如,当要计算123*145时,模型往往无法给出正确答案,这是因为四则运算的可能性太多,模型不可能覆盖所有的情况。同样,对于复杂方程的求解,大模型也束手无策,比如四元方程。图3-11展示了大模型在这两个问题上的错误答案。

图3-11 模型无法正确处理数值计算
论文Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks针对数值计算的难题,提出了一种创新的方法,即思维程序提示(Program of Thoughts Prompting, PoT)。思维程序提示的核心思想是,通过语言模型生成一个能够反映推理逻辑的程序,然后将程序中的计算部分交由外部的计算机执行,实现计算和推理的分离。思维程序提示的优势在于,它既能利用语言模型的强大能力,生成正确和完备的程序来描述复杂的推理,又能将计算交给专业的程序解释器来完成,避免了语言模型在计算上的误差。
接下来参考思维程序提示的方法,来解决四则运算和解方程的问题。使用程序代码来代替数据中的四则运算部分,用python的sympy库来处理解方程的部分。我们制定了一些指令的格式,然后用GPT-4来生成符合这些格式的回答。图3-12展示了设计的几种思维程序提示指令,涵盖了纯四则运算、数学应用题中的四则运算和解方程。
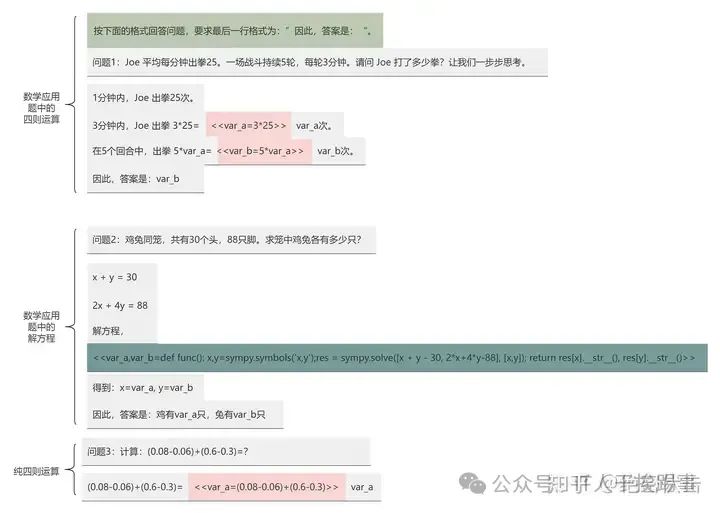
图3-12 构建思维程序提示
根据图3-12的思维程序提示,用GPT-4(确保答案的正确性)来生成相应格式的答案。图3-13展示了新构建的语料格式,可以看出,四则运算部分的结果用中间变量代替,解方程部分用python的sympy函数直接求解。对于没有四则运算和解方程的样本,保持原来的格式不变。为了明确哪些部分需要用程序解释器执行,哪些部分不需要,用"<<“和”>>“来标记,”<<“表示程序的起始,”>>"表示程序的结束。

图3-13 基于思维程序提示构建的新数据
用准备好的新数据对模型进行有监督微调。图3-14展示了训练过程中验证集的损失值变化,验证集损失值呈现下降趋势,最终保存了迭代1000次的模型。
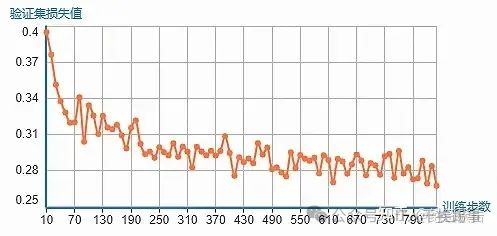
图3-14 模型训练过程验证集的损失值
用Streamlit启动微调后的模型,测试其效果,选取之前的两道数学题作为输入,一道是123*145的计算,一道是四元方程的求解。图3-15显示了模型的输出结果,可以看出,模型的输出格式符合思维程序提示的要求,四则运算部分用中间变量表示,解方程部分用python的sympy函数直接求解。

图3-15 新模型的输出格式为思维程序
为了得到图3-15中的程序代码的输出结果,需要用python解释器来运行它们,解析代码的方法如下所示。
import json
import numpy as np
import pandas as pd
from scipy.optimize import minimize
import sympy
import re
from tqdm import tqdm
import math
import inspect
import inspect
# 解析函数
def parse_pot(inputs):
s = re.findall(r'<<(.*?)>>', inputs, re.DOTALL)
index = 0
for k in s:
if "func" in k:
var = k.split("=", 1)
try:
var[1] = var[1].strip(" ")
exec(var[1], globals())
ans = func()
except:
if 'sympy' in var[1]:
var[1] = var[1].replace('res[x]', 'res[0][0]')
var[1] = var[1].replace('res[y]', 'res[0][1]')
exec(var[1], globals())
ans = func()
var_list = [c.strip(" ") for c in var[0].split(",")]
if len(var_list) == 1:
ans = [ans]
for i in range(len(ans)):
try:
ans[i] = float(ans[i])
if abs(ans[i] - int(ans[i])) < 1e-10:
ans[i] = str(int(ans[i]))
except:
pass
inputs = inputs.replace("<<"+k+">>", "")
for i in range(len(var_list)):
inputs = inputs.replace(var_list[i], str(ans[i]))
index += 1
for c in range(index, len(s)):
for i in range(len(var_list)):
s[c] = s[c].replace(var_list[i], str(ans[i]))
else:
var = k.replace(" ", "").split("=")
var[1] = var[1].replace("eval", "")
ans = eval(var[1])
ans = float(ans)
if abs(ans - int(ans)) < 1e-10:
ans = str(int(ans))
inputs = inputs.replace("<<"+k+">>", "").replace(var[0], str(ans))
index += 1
for c in range(index, len(s)):
s[c] = s[c].replace(var[0], str(ans))
return inputs
把上面的代码写入web_demo2.py文件,运行streamlit run web_demo2.py,就可以启动新模型,它会在输出结果之前用解析代码运行程序代码。图3-16展示了解析后的效果,可以看出,无论是简单的数值计算,还是复杂的解方程,模型都能给出正确的答案。而且,即使是涉及复杂运算的数学应用题,模型也能通过解析程序得到正确的答案。
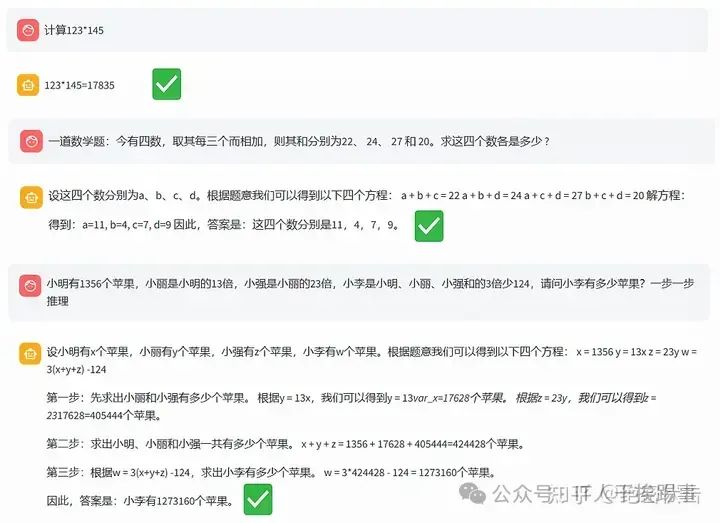
图3-16 新模型答案解析后的输出
除了四则运算和解方程,还可以增加其它程序功能,如计算时间日期、求函数极值等。此外,除了程序代码,还可以使用第三方插件,如发送邮件、绘制图表等功能。大模型作为一个智能体,能够理解人类的意图,选择最有效的解决方案,而我们只需根据需求,对大模型进行有监督微调,就能开发出更符合预期的私有大模型。
总结
如今大模型百花齐放,关于大模型的文章也非常多,但是介绍如何从0开始构建自己的大模型的介绍比较少,本文系统性地介绍了如何选择合适的基座模型,以及如何使用自己的数据微调大模型。
来源:知乎
作者:绝密伏击
链接:https://zhuanlan.zhihu.com/p/673308333
零基础如何学习大模型 AI
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型典型应用场景
①AI+教育:智能教学助手和自动评分系统使个性化教育成为可能。通过AI分析学生的学习数据,提供量身定制的学习方案,提高学习效果。
②AI+医疗:智能诊断系统和个性化医疗方案让医疗服务更加精准高效。AI可以分析医学影像,辅助医生进行早期诊断,同时根据患者数据制定个性化治疗方案。
③AI+金融:智能投顾和风险管理系统帮助投资者做出更明智的决策,并实时监控金融市场,识别潜在风险。
④AI+制造:智能制造和自动化工厂提高了生产效率和质量。通过AI技术,工厂可以实现设备预测性维护,减少停机时间。
⑤AI+零售:智能推荐系统和库存管理优化了用户体验和运营成本。AI可以分析用户行为,提供个性化商品推荐,同时优化库存,减少浪费。
⑥AI+交通:自动驾驶和智能交通管理提升了交通安全和效率。AI技术可以实现车辆自动驾驶,并优化交通信号控制,减少拥堵。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段

二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。

三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。


四、LLM面试题

如果二维码失效,可以点击下方链接,一样的哦
【CSDN大礼包】最新AI大模型资源包,这里全都有!无偿分享!!!
😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~


开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐


 27
27 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)