论文解读:ia-yolo | Image-Adaptive YOLO for Object Detection in Adverse Weather Conditions
任务背景1、在恶劣天气条件下捕获的低质量图像中定位目标仍然具有挑战性2、在恶劣天气下拍摄的图像可以分解为干净的图像 及其 相应的特定天气的信息3、在恶劣天气下的图像质量下降,主要是由于特定天气信息与物体之间的相互作用,导致检测性能较差相关研究1、Huang、Le和Jaw(2020)采用了两个子网联合学习可见性增强和目标检测,通过共享特征提取层,降低了图像退化的影响。然而,在训练过程中,很难调整参数
发布时间:2022.4.4 (2021发布,进过多次修订)
论文地址:https://arxiv.org/pdf/2112.08088.pdf
项目地址:https://github.com/wenyyu/Image-Adaptive-YOLO
虽然基于深度学习的目标检测方法在传统数据集上取得了很好的结果,但从在恶劣天气条件下捕获的低质量图像中定位目标仍然具有挑战性。现有的方法要么在平衡图像增强和目标检测任务方面存在困难,要么往往忽略了有利于检测的潜在信息。为了缓解这一问题,我们提出了一种新的图像自适应YOLO(IA-YOLO)框架,在该框架中,每个图像都可以自适应地增强,以获得更好的检测性能。具体来说,提出了一个可微图像处理(DIP)模块,以考虑YOLO探测器的恶劣天气条件,其参数由一个小卷积神经网络(CNN-PP)预测。。我们以端到端方式联合学习CNN-PP和YOLOv3,这确保了CNN-PP可以学习适当的DIP,以弱监督的方式增强图像检测。我们提出的IA-YOLO方法可以自适应地处理正常和不利天气条件下的图像。实验结果非常令人鼓舞,证明了我们提出的IAYOLO方法在雾光和弱光情况下的有效性。
有意使用或者复现IA-YOLO的朋友可以先阅读一下: IA-YOLO项目中DIP模块的初级解读
基本解读
任务背景
1、在恶劣天气条件下捕获的低质量图像中定位目标仍然具有挑战性
2、在恶劣天气下拍摄的图像可以分解为干净的图像 及其 相应的特定天气的信息
3、在恶劣天气下的图像质量下降,主要是由于特定天气信息与物体之间的相互作用,导致检测性能较差
相关研究
1、Huang、Le和Jaw(2020)采用了两个子网联合学习可见性增强和目标检测,通过共享特征提取层,降低了图像退化的影响。然而,在训练过程中,很难调整参数来平衡检测和恢复之间的权重;
2、通过现有方法对图像进行预处理,如图像去雾(Hang等2020;Liu等2019)和图像增强(Guo等2020),来稀释特定天气信息的影响。这需要复杂的图像生成网络
3、该类任务可以视为无监督的领域适应任务,假定恶劣天气下的图像与正常图像存在域偏移,但仅解决域偏移可能会使潜在的目标检测特征被忽视。
论文核心
1、提出了一种端到端的图像自适应YOLO(IA-YOLO)框架,在该框架中,每个图像都可以CNN-PP模块预测出DIP的调节参数进行自适应地增强,以获得更好的检测性能

2、其所提出的图像自适应增强DIP是一个白盒处理模块,由CNN-PP模块预测出调节参数(也仅是多了CNN-PP模块的参数,整体推理时间多了13ms)
3、在训练时使用正常图片和加噪图片(离线数据增强)
3、作者消融实验中固定参数的DIP在各种场景下均有效,表明通用的图像增强能提升模型的泛化能力。
虽然论文实验基于yolov3展开,其核心思想在其他目标检测框架中也可以采用,尤其是其DIP数据处理模块,在极端缓解下,即使未经过训练,任然能取得良好效果,但其在正常情况下导致了性能下降。 下图中yolov3 I为正常训练模型, yolov3 II为混合数据训练模型,yolov3_deep II 为多了8个卷积层的模型。

IA-YOLO所展示的实验结果表明,在混合数据的训练条件下,各种针对极端天气的域适应算法效果都不行这里值得反思与注意,极端天气的域适应算法都不如正常训练的yolov3模型

Introduction
基于cnn的方法在目标检测中占了上风(Ren et al. 2015;Redmon和Farhadi 2018)。他们不仅在基准数据集上取得了良好的性能(Deng等,2009;埃弗林汉姆等,2010;Lin等,2014年),而且已经部署在现实应用中,如自动驾驶(Wang等,2019年)。由于输入图像的域移(Sindagi et al. 2020),在恶劣天气条件下(如雾、暗光)训练的一般目标检测模型往往无法获得满意的结果。Narasimhan和Nayar(2002)和You等人(2015)认为,在恶劣天气下拍摄的图像可以分解为干净的图像 及其 相应的特定天气的信息,并指出在恶劣天气下的图像质量下降,主要是由于特定天气信息与物体之间的相互作用,导致检测性能较差。图1为雾条件下目标检测的例子。我们可以看到,如果图像能够根据天气条件进行适当的增强,就可以恢复更多关于原始模糊物体和错误识别物体的潜在信息。

为了解决这一具有挑战性的问题,Huang、Le和Jaw(2020)采用了两个子网联合学习可见性增强和目标检测,通过共享特征提取层,降低了图像退化的影响。然而,在训练过程中,很难调整参数来平衡检测和恢复之间的权重。另一种方法是通过现有方法对图像进行预处理,如图像去雾(Hang等2020;Liu等2019)和图像增强(Guo等2020),来稀释特定天气信息的影响。然而,这些方法中必须包含复杂的图像恢复网络,需要单独进行像素级监督训练。这需要手动标记图像以进行恢复。
该问题也可以被视为一个无监督的领域适应任务(Chen et al. 2018;Hnewa和Radha 2021)。与具有清晰图像(源图像)的训练检测器相比,假设在恶劣天气下捕获的图像(目标图像)存在分布偏移。这些方法大多采用领域自适应原则,侧重于对齐两个分布的特征,在基于天气的图像恢复过程中可以获得的潜在信息通常被忽略。
为了解决上述限制,我们提出了一种巧妙的图像自适应目标检测方法,称为IA-YOLO。具体来说,我们提出了一个完全可微的图像处理模块(DIP),它的超参数可以由一个基于cnn的小参数预测器(CNNPP)自适应地学习。CNN-PP根据输入图像的亮度、颜色、色调和特定于天气变化的信息,自适应地预测DIP的超参数。经过DIP模块处理后,可以抑制图像中特定天气信息的干扰,而潜在信息可以恢复。我们提出了一种联合优化方案,以端到端的方式学习DIP、CNN-PP和YOLOv3骨干检测网络(Redmon和Farhadi 2018)。为了增强图像的检测,CNN-PP进行弱监督,通过边界框学习适当的DIP。此外,我们利用在正常和不利天气条件下的图像来训练模型。通过利用CNN-PP网络,我们提出的IA-YOLO方法能够自适应地处理受不同程度天气条件影响的图像。图1显示了我们所提出的方法的检测结果的一个例子。
本工作的重点是:
- 1)提出了一种图像自适应检测框架,在正常和恶劣天气条件下都取得了良好的性能;
- 2)提出了白盒可微图像处理模块,其超参数由弱监督参数预测网络预测;
- 3)在合成测试台(VOC_Foggy和VOC_Dark)和真实数据集(RTTS和ExDark)上,与ExDark相比,取得了令人鼓舞的实验结果。
Related Work
Object Detection
目标检测作为计算机视觉的一项基本任务,受到广泛关注。目标检测方法大致可分为两类(Zhao et al. 2019)。其中一类是基于区域提案的方法,该方法首先从图像中生成感兴趣的区域(RoIs),然后通过训练神经网络对其进行分类。 另一类是基于单阶段回归的方法,如YOLO系列和SSD,其中对象标签和边界框坐标由单个CNN预测。在本文中,我们采用经典的单级探测器YOLOv3(Redmon和Farhadi 2018)作为基线探测器,并提高其在不利条件下的性能。
Image Adaptation
图像自适应技术被广泛地应用于图像增强技术中。为了适当地增强图像,一些传统的方法根据相应的图像特征自适应地计算图像变换参数。例如,Wang等人(2021)提出了一种亮度调整函数,它根据输入图像的光照分布特征自适应地调整增强参数。
为了实现自适应图像增强,采用小型CNN灵活学习图像变换的超参数。Hu等人(2018)提出了一套带有可微滤波器的后处理框架,利用深度强化学习(DRL)根据当前修饰图像的质量生成图像操作和滤波参数。Zeng等人(2020)利用一个小型CNN,根据亮度、颜色和色调等全球背景,学习图像自适应的3Dlut。
Object Detection in Adverse Conditions
与一般的目标检测相比,在恶劣天气条件下进行目标检测的研究很少。一种简单的方法是使用经典的去雾或图像增强方法对图像进行预处理,最初的设计目的是去除雾,提高图像质量。然而,对图像质量的提高可能并不肯定有利于检测性能。一些基于原始的方法联合进行图像增强和检测,以减弱不利天气特定信息的干扰。Sindagi等人(2020)提出了一种基于无监督先验的域对抗性对象检测框架,用于在朦胧和多雨条件下进行检测。一些方法(Chen等人2018;Zhang等人2021;Hnewa和Radha 2021)利用领域自适应来解决这个问题。Hnewa和Radha(2021)假设在正常和不利天气条件下捕获的图像之间存在域偏移。他们设计了一个多尺度的领域自适应YOLO,在特征提取阶段支持不同层的领域自适应。
Proposed Method
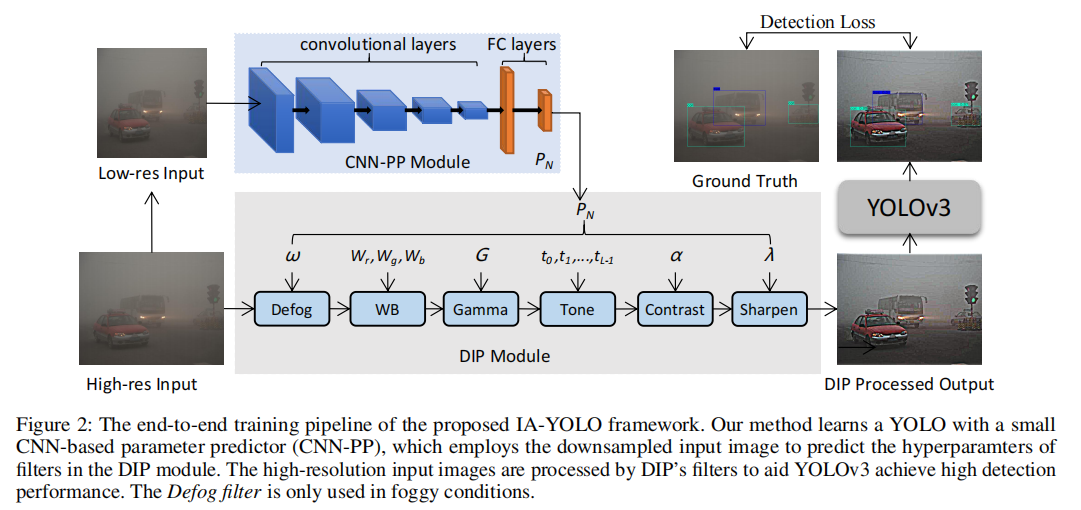
在恶劣天气条件下拍摄的图像,由于特定天气信息的干扰,能见度较差,导致目标检测困难。为了解决这一挑战,我们提出了一个图像自适应检测框架,通过去除特定天气的信息和揭示更多的潜在信息。如图2所示,整个pipeline由一个基于cnn的参数预测器(CNNPP)、一个可微图像处理模块(DIP)和一个检测网络组成。我们首先将输入图像的大小调整为256×256的大小,并将其输入CNN-PP,以预测DIP的参数。然后,将经DIP模块滤波后的图像作为YOLOv3检测器的输入。我们提出了一种具有检测损失的端到端混合数据训练方案,使CNN-PP能够学习一个适当的DIP,以弱监督的方式增强图像的目标检测。
DIP Module
如(Hu et al. 2018)所述,图像滤波器的设计应符合可微性和分辨率无关性。对于基于梯度的CNNPP优化,滤波器应该是可微的,以允许通过反向传播来训练网络。由于CNN将消耗大量的计算资源来处理高分辨率图像(例如,4000×3000),在本文中,我们从256×256的低分辨率图像中学习滤波器参数,然后将相同的滤波器参数应用于原始分辨率的图像。因此,这些滤波器需要独立于图像分辨率。
这里的图像域适流程应用于forward流程
DIP模块由6个具有可调超参数的可微滤波器组成,包括Defog、白平衡(WB)、伽玛、对比度、Tone 和Sharpen。如(Hu et al. 2018)所述,标准的颜色和Tone操作符,如WB、伽玛、对比度和Tone,可以表示为像素级滤波器。因此,我们设计的滤波器可以分为Defog、像素级滤波器和锐化。在这些滤波器中,Defog滤波器是专门为有雾的场景而设计的。详情如下。
Pixel-wise Filters. 像素级滤波器将输入像素值
P
i
=
(
r
i
、
g
i
、
b
i
)
P_i =(r_i、g_i、b_i)
Pi=(ri、gi、bi)映射到输出像素值
P
o
=
(
r
o
、
g
o
、
b
o
)
P_o =(r_o、g_o、b_o)
Po=(ro、go、bo),其中(r、g、b)分别表示红色、绿色和蓝色三个颜色通道的值。表1列出了四个像素级过滤器的映射函数,其中第二列列出了在我们的方法中需要优化的参数。WB和伽玛是简单的乘法和幂变换。显然,它们的映射函数对于输入图像和参数都是可微的。

设计可微对比度滤波器,设置原始图像和完全增强图像之间的线性插值。如表1所示,其中映射函数中En(Pi)的定义如下:


如(Hu et al. 2018)所述,我们将Tone滤波器设计为一个单调的分段线性函数。我们学习具有L个参数的Tone滤波器,表示为
{
t
0
,
t
1
,
…
…
,
t
L
−
1
}
\{t_0,t_1,……,t_{L−1}\}
{t0,t1,……,tL−1}。Tone曲线的点记为${(k/L,T_k/T_L)}
,其中
,其中
,其中T k=\sum{k-1}^{i=0}t_l
。此外,映射函数由可微参数表示,使该函数对输入图像和参数
。此外,映射函数由可微参数表示,使该函数对输入图像和参数
。此外,映射函数由可微参数表示,使该函数对输入图像和参数{t_0,t_1,……,t_{L−1}}$都具有可微性,如下所示
P
o
=
1
T
L
∑
j
=
0
L
−
1
clip
(
L
⋅
P
i
−
j
,
0
,
1
)
t
k
(4)
P_{o}=\frac{1}{T_{L}} \sum_{j=0}^{L-1} \operatorname{clip}\left(L \cdot P_{i}-j, 0,1\right) t_{k} \tag{4}
Po=TL1j=0∑L−1clip(L⋅Pi−j,0,1)tk(4)
Sharpen Filter. 图像锐化可以突出显示图像的细节。像非锐化掩模技术,锐化过程可以描述如下,其中I (x)是输入图像,Gau(I(x))表示高斯滤波器,λ是一个正的比例因子。这个锐化操作对于x和λ都是可区分的。请注意,可以通过优化λ来调整锐化程度,以获得更好的目标检测性能。
F
(
x
,
λ
)
=
I
(
x
)
+
λ
(
I
(
x
)
−
G
a
u
(
I
(
x
)
)
)
(5)
F(x, λ) = I(x) + λ(I(x) − Gau(I(x))) \tag{5}
F(x,λ)=I(x)+λ(I(x)−Gau(I(x)))(5)
Defog Filter. 受暗通道先验方法(He,Sun,Tang2009)启发,我们设计了一个具有可学习参数的defog滤波器。根据大气散射模型(麦卡特尼,1976年;纳拉辛汉和纳亚尔,2002年),模糊图像的形成可以表述如下:
I
(
x
)
=
J
(
x
)
t
(
x
)
+
A
(
1
−
t
(
x
)
)
(6)
I(x) = J(x)t(x) + A(1 − t(x)) \tag{6}
I(x)=J(x)t(x)+A(1−t(x))(6)
其中I (x)为有雾的图像,J (x)表示场景亮度(干净图像)。A为全球大气光.t (x)为介质透射图,定义如下。其中,β表示大气的散射系数,d(x)为场景深度。
t
(
x
)
=
e
−
β
d
(
x
)
(7)
t(x) = e^{−β}d(x) \tag{7}
t(x)=e−βd(x)(7)
为了恢复干净的图像J (x),关键是获取大气光A和透射图t (x)。为此,我们首先计算雾霾图像I (x)的暗通道图,并选择前1000个最亮的像素。然后,通过将雾霾图像I (x)对应位置的1000个像素平均来估计A。
根据公式(6),我们可以推导出t (x)的一个近似解如下:
t
(
x
)
=
1
−
min
C
(
min
y
∈
Ω
(
x
)
I
C
(
y
)
A
C
)
(8)
t(x)=1-\min _{C}\left(\min _{y \in \Omega(x)} \frac{I^{C}(y)}{A^{C}}\right) \tag{8}
t(x)=1−Cmin(y∈Ω(x)minACIC(y))(8)
我们进一步引入了一个参数ω来控制脱雾的程度,如下所示:
t
(
x
)
=
1
−
ω
min
C
(
min
y
∈
Ω
(
x
)
I
C
(
y
)
A
C
)
(8)
t(x)=1-ω\min _{C}\left(\min _{y \in \Omega(x)} \frac{I^{C}(y)}{A^{C}}\right) \tag{8}
t(x)=1−ωCmin(y∈Ω(x)minACIC(y))(8)
由于上述操作是可微的,我们可以通过反向传播对ω进行优化,使消雾滤波器更有利于雾图像检测。
实际forward流程中的数据变化示意如下所示

CNN-PP Module
在摄像机图像信号处理(ISP)管道中,通常采用一些可调滤波器进行图像增强,其超参数由经验丰富的工程师通过视觉检查手动调整(Mosleh et al. 2020)。一般来说,这种调优过程对于为各种场景找到合适的参数是非常尴尬和昂贵的。为了解决这一限制,我们建议使用一个小的CNN作为参数预测器来估计超参数,这是非常有效的。
以有雾的场景为例,CNN-PP的目的是通过了解图像的全局内容,如亮度、颜色、色调,以及雾的程度,来预测DIP的参数。因此,降采样图像足以估计这些信息,从而大大节省了计算成本。给定任何分辨率的输入图像,我们简单地使用双线性插值将其降采样到256×256分辨率。如图2所示,CNN-PP网络由5个卷积块和2个全连通层组成。每个卷积块包括一个3×3的卷积层,步幅为2和一个Leaky Relu。最终的全连接层输出DIP模块的超参数。这五个卷积层的输出通道分别为16、32、32、32和32。当参数总数为15个时,CNN-PP模型只包含165K个参数。
CNN-PP Module用于生成DIP模块的调节参数【嵌入到yolov3模型中】
Detection Network Module
在本文中,我们选择了单级检测器YOLOv3作为检测网络,它被广泛应用于实际应用中,包括图像编辑、安全监控、人群检测和自动驾驶(Zhang et al. 2021)。与之前的版本相比,YOLOv3基于Resnet的想法设计了连续的3×3和1×1的卷积层(He et al. 2016)。通过对多尺度特征图进行预测,实现了多尺度训练,从而进一步提高了检测精度,特别是对小目标。我们采用与原始YOLOv3相同的网络架构和损失函数(Redman和Farhadi 2018)。
Hybrid Data Training
为了在正常和恶劣天气条件下实现理想的检测性能,IA-YOLO采用了混合数据训练方案。算法1总结了我们所提方法的训练过程。每幅图像在输入网络进行训练之前,随机添加某种雾或转换为弱光图像的概率为2/3。对于正常和合成的低质量训练数据,整个管道都采用YOLOv3检测损失进行端到端训练,确保了IA-YOLO中的所有模块都能够相互适应。因此,CNN-PP模块受到检测损失的弱监督,而没有手动标记的GT。混合数据训练模式保证了IA-YOLO能够根据每幅图像的内容对图像进行自适应处理,从而获得了较高的检测性能。

Experiments
我们评估了我们的方法在雾和弱光场景下的有效性。滤波器组合为[Defog, White Balance(WB), Gamma, Contrast, Tone, Shapen],而Defog滤波器仅在雾霾条件下使用
Implementation Details
我们在IA-YOLO方法中采用了(Redmon和Farhadi 2018)的训练方法。所有实验的主干网络都是darknet-53。在训练过程中,随机调整图像的大小到(32N×32N),其中N∈[9,19]。此外,还采用了图像翻转、裁剪、变换等数据增强方法对训练数据集进行了扩展。我们的IA-YOLO模型由Adam优化器(Kingma和Ba 2014)进行训练,共80个epoch。开始学习速率为10−4,批量大小为6。IAYOLO预测了三个不同尺度上的边界框,以及每个尺度上的三个锚点。我们使用TensorFlow进行实验,并在特斯拉V100 GPU上运行它。
Experiments on Foggy Images
Datasets 在不利的天气条件下,用于目标检测的公开数据集很少,远不足训练一个稳定的基于cnn的检测器。为了便于公平比较,我们基于经典的VOC数据集,根据大气散射模型建立了一个VOC_Foggy数据集。此外,RTTS(Li et al. 2018)是一个相对全面的真实世界数据集,它有4322张自然模糊图像,有5个标注的对象类,即人、自行车、汽车、公交车和摩托车。为了形成我们的训练数据集,我们选择了包含这五个类别的数据来添加雾霾。
对于VOC2007_trainval和VOC2012_trainval,我们过滤包含上述五类对象的图像来构建VOC_norm_trainval。VOC_norm_test从VOC2007_test中选择。我们也在RTTS上评估了我们的方法。数据集的统计数据汇总为表2。

为了避免在训练过程中生成模糊图像的计算成本,我们离线构建了VOC_Foggy数据集。根据公式。(6、7),雾化图像I (x)生成过程如下。式中,ρ为从当前像素到中心像素的欧氏距离,行和col分别为图像的行数和列数。通过设置A = 0.5和β = 0.01∗i + 0.05,其中i是一个从0到9的整数,可以向每个图像添加10个不同级别的雾。基于VOC_norm_trainval数据集,我们生成了一个10倍大的VOC_Foggy_trainval数据集。为了获得VOC_Foggy_test数据集,对VOC_norm_test中的每幅图像都进行了雾的随机处理。
I
(
x
)
=
J
(
x
)
e
−
β
d
(
x
)
+
A
(
1
−
e
−
β
d
(
x
)
)
d
(
x
)
=
−
0.04
∗
ρ
+
m
a
x
(
r
o
w
,
c
o
l
)
(10-11)
I(x) = J(x)e^{−β}d(x) + A(1 − e^{−β}d(x)) \tag{10-11} \\ d(x) = −0.04 ∗ ρ +\sqrt{max(row, col)}
I(x)=J(x)e−βd(x)+A(1−e−βd(x))d(x)=−0.04∗ρ+max(row,col)(10-11)
Experimental Results 为了证明IA-YOLO的有效性,我们将我们的方法与三个测试数据集上的基线YOLOv3、Defog+Detect、域自适应(Hnewa和Radha 2021)和多任务学习(Huang、Le和Jaw 2020)进行了比较。对于Defog + Detect,我们采用脱雾方法作为预处理步骤,并使用经过VOC_norm训练的YOLOv3进行检测。我们选择MSBDN(Hang等人2020年)和GridDehaze(Liu等人2019年)作为过处理方法,这是流行的基于cnn的脱雾方法。对于域自适应方法,我们采用了单阶段多尺度域自适应检测器的DAYOLO(Hnewa和Radha 2021),以及YOLOv3不同尺度下相应的域分类器。对于多任务学习算法,我们选择DSNet(Huang,Le,和Jaw 2020),在恶劣天气条件下联合学习脱雾和检测。通过共享Yolov3的前5个卷积层,我们再现了其检测子网络和恢复模块,并使用混合数据联合训练两个网络。
表3比较了IA-YOLO和其他竞争算法的平均平均精度(mAP)结果(Everingham et al. 2012)。第二列列出了每种方法的训练数据,其中“混合数据”是指我们提出的IA-YOLO中使用的混合数据训练方案。与基线(YOLO I)相比,所有方法在合成和真实词雾天气测试数据集上都有改进,而在正常情况下,只有IA-YOLO在正常情况下没有恶化。这是因为之前的方法主要是为了处理雾霾天气条件下的目标检测,同时牺牲了它们在正常天气图像上的性能。对于我们提出的IA-YOLO方法,CNN-PP和DIP模块能够自适应处理具有不同程度雾度的图像,使目标检测效果提升。因此,我们提出的IA-YOLO方法在三个测试数据集上的性能大大优于所有竞争方法,证明了其在恶劣天气条件下的目标检测的有效性。

图3显示了我们的IA-YOLO方法和基线YOLOv3 II的几个可视化示例。虽然在某些情况下,我们的自适应DIP模块会对视觉感知产生一些不情愿的噪声,但它极大地提高了基于图像语义的局部图像梯度,从而提高了更好的检测性能。

Experiments on Low-light Images
Datasets PSCAL VOC和相对全面的低光检测数据集ExDark都包含10类物体:自行车、船、瓶子、公共汽车、汽车、猫、椅子、狗、摩托车、人。从VOC2007_trainval和VOC2012_trainval中,我们过滤了包含上述十类对象的图像来构建VOC_norm_trainval。VOC_norm_test选自VOC2007_test也以同样的方式进行。VOC_norm_trainval、VOC2007_test和ExDark_test中的图像总数分别为12334、3760和2563张。
我们通过变换 f ( x ) = x γ f(x) = x^γ f(x)=xγ合成基于VOC_norm的弱光VOC_dark数据集,其中γ的值从[1.5,5]范围内的均匀分布中随机采样,x表示输入像素强度。
Experimental Results 我们将我们提出的IAYOLO方法与基线YOLOv3、Enhance+Detect、DAYOLO, DSNet在三个测试数据集上进行了比较。对于Enhance+Detect,我们采用最近的图像增强方法Zero-DCE(Guo et al. 2020)对弱光图像进行预处理,并使用在VOC_norm上训练的YOLOv3进行检测。其余的实验设置与有雾图像相同。表4显示了mAP的结果。可以看出,我们的方法产生了最好的结果。IA-YOLO对VOC_norm_test、VOC_Dark_test和ExDark_test分别将YOLO I基线提高了0.89、13.48和3.95%,对YOLO II基线提高了4.69、7.12和3.34%。这表明,我们提出的IA-YOLO方法在低光条件下也是有效的。
图4显示了IAYOLO与基线YOLOv3 II之间的定性比较。可以看出,我们提出的DIP模块能够自适应地增加输入图像的对比度,揭示图像的细节,这对目标检测至关重要。

Ablation Study
为了检验我们提出的框架中每个模块的有效性,我们在不同的设置下进行了消融实验,包括混合数据训练方案、DIP和图像自适应。我们还评估了在三个测试数据集上所提出的可微滤波器的选择。
实验实验结果如图5所示。除了用VOC_norm训练的YOLO外,其余的实验都采用了相同的混合数据训练和实验设置。可以看出,与YOLO I相比,混合数据训练、DIP滤波器预处理和图像自适应方法都能提高VOC_Foggy_test和RTTS的检测性能。IA-YOLO通过同时使用这三个模块,都取得了最好的效果。具有固定DIP的YOLOv3意味着过滤器的超参数是一组给定的固定值,所有这些值都在一个合理的范围内。YOLOv3_deep II是YOLO II的一个更深层次的版本,它添加了8个卷积层,学习参数超过411K。如图5所示,我们提出的IA-YOLO方法在CNN-PP中只有165K个附加参数的情况下,其性能优于YOLOv3_deep II。值得一提的是,在正常天气条件下,只有自适应学习模块比YOLO I的VOC_norm_test的性能有所提高,而YOLOv3 II和固定DIP的YOLOv3的结果都较差。这说明IA-YOLO可以自适应地处理正常图像和雾化图像,有利于下行检测任务。

如表5所示,我们使用这三个测试数据集对过滤器的选择进行了定量的mAP评估。模型D结合这三组滤波器,得到了最好的结果,证明了这些滤波器的有效性。图6显示了表5中几种模型的可视化比较。与增强图像的模型C和消除图像的模型B相比,模型D处理的图像不仅更亮更清晰,而且使有雾的物体更加可见。此外,我们还提供了一些关于CNN-PP如何预测DIP模块参数的例子。详情请参考补充文件。

Efficiency Analysis
在我们的IA-YOLO框架中,我们在YOLOv3中引入了一个带有165K可训练参数的小型CNNPP学习模块。IA-YOLO需要44 ms才能在单个特斯拉V100 GPU上检测出544×544×3分辨率的图像。它只比YOLOv3基线多花了13个ms,而它分别比GridDehaze-YOLOv3和MSBDNYOLOv3快7个ms和50个ms。总之,IA-YOLO只添加了165K个可训练参数,同时在运行时间相当的所有测试数据集上获得了更好的性能。
Conclusion
我们提出了一种新的IA-YOLO方法来改进恶劣天气条件下的目标检测,并对每个输入图像进行自适应增强,以获得更好的检测性能。开发了一个全可微图像处理模块,通过去除YOLO探测器的特定天气信息来恢复潜在内容,其超参数由一个小的卷积神经网络预测。此外,整个框架以端到端方式进行训练,其中对参数预测网络进行弱监督,通过检测损失学习适当的DIP模块。利用混合训练和参数预测网络的优势,该方法能够自适应地处理正常和不利的天气条件。实验结果表明,我们的方法在雾光和弱光情况下都优于以往的方法。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐


 7
7 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)