图像超分辨率重建相关概念、评价指标、数据集、模型
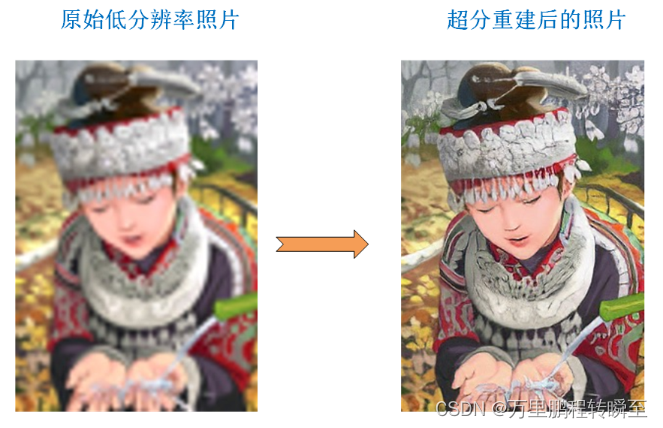
超分辨率(Super-Resolution),简称超分(SR)。是指利用光学及其相关光学知识,根据已知图像信息恢复图像细节和其他数据信息的过程,简单来说就是增大图像的分辨率,使图像更加“清晰”,尽可能保证图像质量不下降。超分辨率的方法包括传统方法和深度学习的方法,有关超分辨率方法分类如下图所示。深度学习方法在性能上远远领先于传统方法,有着更好的图像超分辨率表现。知乎用户 阿布的足迹https:/
1、图像超分辨率概念
1.1 基本定义
超分辨率(Super-Resolution),简称超分(SR)。是指利用光学及其相关光学知识,根据已知图像信息恢复图像细节和其他数据信息的过程,简单来说就是增大图像的分辨率,使图像更加“清晰”,尽可能保证图像质量不下降。


超分辨率的方法包括传统方法和深度学习的方法,有关超分辨率方法分类如下图所示。深度学习方法在性能上远远领先于传统方法,有着更好的图像超分辨率表现。

上述内容参考:知乎用户 阿布的足迹 https://zhuanlan.zhihu.com/p/558813267
从单一低分辨率图像中恢复高分辨率图像。这个问题本质上是不确定的,因为对于任何给定的低分辨率像素都存在多重解。换句话说,它是做一个信息恢复,属于一个欠确定的逆问题,其解决方案不是唯一的。这类问题通常通过使用强先验信息来约束解空间来缓解。如上图所示的传统方法,则是利用强先验信息进行问题求解(空间相邻的像素,值是相近的)。深度学习方法,也就是学习映射函数基于外部实例的方法可以用于通用的图像超分辨率,也可以根据所提供的训练样本,设计成适合特定领域的任务。
1.2 应用场景
图像超分辨率重建技术在多个领域都有着广泛的应用范围和研究意义。主要包括:
(1) 图像压缩领域
在视频会议等实时性要求较高的场合,可以在传输前预先对图片进行压缩,等待传输完毕,再由接收端解码后通过超分辨率重建技术复原出原始图像序列,极大减少存储所需的空间及传输所需的带宽。
(2) 医学成像领域
对医学图像进行超分辨率重建,可以在不增加高分辨率成像技术成本的基础上,降低对成像环境的要求,通过复原出的清晰医学影像,实现对病变细胞的精准探测,有助于医生对患者病情做出更好的诊断。
(3) 遥感成像领域
高分辨率遥感卫星的研制具有耗时长、价格高、流程复杂等特点,由此研究者将图像超分辨率重建技术引入了该领域,试图解决高分辨率的遥感成像难以获取这一挑战,使得能够在不改变探测系统本身的前提下提高观测图像的分辨率。
(4) 公共安防领域
公共场合的监控设备采集到的视频往往受到天气、距离等因素的影响,存在图像模糊、分辨率低等问题。通过对采集到的视频进行超分辨率重建,可以为办案人员恢复出车牌号码、清晰人脸等重要信息,为案件侦破提供必要线索。
(5) 视频感知领域
通过图像超分辨率重建技术,可以起到增强视频画质、改善视频的质量,提升用户的视觉体验的作用。
上述内容参考:csdn用户 钱彬 (Qian Bin) https://blog.csdn.net/qianbin3200896/article/details/104181552
2、相关指标
图像超分的相关评价指标可以分为有参考的评价指标和无参考都评价指标。有参考的评价有:PSNR、SSIM、LQNE等,这里仅结束torch支持的指标(基于np数组计算的指标耗时过长,一张图1s简直是煎熬),需要安装torchmetrics。
pip install torchmetrics
torchmetrics官网:
https://lightning.ai/docs/torchmetrics/stable/pages/quickstart.html
2.1 PSNR
PSNR是信号的最大功率和信号噪声功率之比,来测量已经被压缩的重构图像的质量,通常以分贝(dB)来表示。PSNR指标越高,说明图像质量越好。 在通常的RGB图像中,PSNR的最大值(MSE最小,为0时)为20*lg(255)≈48左右。
(1)高于40dB:说明图像质量极好(即非常接近原始图像)
(2)30—40dB:通常表示图像质量是好的(即失真可以察觉但可以接受)
(3)20—30dB:说明图像质量差
(4)低于20dB:图像质量不可接受
在应用到特定行业时,计算PSNR采用的MAX值可能不是255,也可能不是max值,而是统计意义上的最大值(避免异常最大值的干扰),否则会存在肉眼效果差,而PSNR效果好的情况

pytorch 计算PSNR代码 https://lightning.ai/docs/torchmetrics/stable/image/peak_signal_noise_ratio.html
接口说明:torchmetrics.image.PeakSignalNoiseRatio(data_range=None, base=10.0, reduction=‘elementwise_mean’, dim=None, **kwargs)
from torchmetrics.image import PeakSignalNoiseRatio
psnr = PeakSignalNoiseRatio()
preds = torch.tensor([[0.0, 1.0], [2.0, 3.0]])
target = torch.tensor([[3.0, 2.0], [1.0, 0.0]])
psnr(preds, target)
#tensor(2.5527)
2.2 SSIM
结构相似性的基本思路是,通过(亮度、对比度、结构)三个方面来对两幅图像的相似性进行评估,基本流程为:
(1)对于输入的x和y,首先计算出(亮度测量)luminance measurement,进行比对,得到第一个相似性有关的评价;
(2)再减去luminance的影响,计算(对比度测量)contrast measurement,比对,得到第二个评价;
(3)再用上一步的结果除掉对比度的影响,再进行structure的比对。最后将结果combine,得到最终的评价结果。
其计算过程比较复杂,不进行摘抄,各位可以阅读原文链接:https://blog.csdn.net/qq_27825451/article/details/104016874
SSIM的取值范围为[-1,1],约接近1表示效果越好,大部分sota模型都是在0.8~0.9左右【具体与数据集相关】
结构相似度指数从图像组成的角度将结构信息定义为独立于亮度、对比度的反映场景中物体结构的属性,并将失真建模为亮度、对比度和结构三个不同因素的组合。用均值作为亮度的估计,标准差作为对比度的估计,协方差作为结构相似程度的度量。
pytorch 计算MULTI-SCALE SSIM代码 (基于多尺度计算ssim)
torchmetrics.image.MultiScaleStructuralSimilarityIndexMeasure(gaussian_kernel=True, kernel_size=11, sigma=1.5, reduction=‘elementwise_mean’, data_range=None, k1=0.01, k2=0.03, betas=(0.0448, 0.2856, 0.3001, 0.2363, 0.1333), normalize=‘relu’, **kwargs)
from torchmetrics.image import MultiScaleStructuralSimilarityIndexMeasure
import torch
gen = torch.manual_seed(42)
preds = torch.rand([3, 3, 256, 256], generator=torch.manual_seed(42))
target = preds * 0.75
ms_ssim = MultiScaleStructuralSimilarityIndexMeasure(data_range=1.0)
ms_ssim(preds, target)
2.3 LPIPS
LPIPS 度量指标是建立在一个 484K 的人类判别的感知数据集(Berkeley-Adobe Perceptual Patch Similarity(BAPPS) Dataset,在构建 BAPPS 数据集时,对参考图进行失真操作,然后人类根据参考图和失真图进行评分)基础上构建 CNN 网络(相关模型有:VGG,AlexNet,SqueezeNet )来构建度量学习。这主要指出,PSNR与SSIM指标效果与人类肉眼效果存在差异 SSIM的取值范围为[0,1],约接近0表示效果越好,先行sota模型指标通常在0.2左左右

LPIPS的取值范围为[0,1],约接近0表示效果越好,大部分sota模型都是在0.2~0.26左右
pytorch 计算LPIPS 代码 (基于多尺度计算ssim)
torchmetrics.image.lpip.LearnedPerceptualImagePatchSimilarity(net_type=‘alex’, reduction=‘mean’, normalize=False, **kwargs)
import torch
_ = torch.manual_seed(123)
from torchmetrics.image.lpip import LearnedPerceptualImagePatchSimilarity
lpips = LearnedPerceptualImagePatchSimilarity(net_type='squeeze')
# LPIPS needs the images to be in the [-1, 1] range.
img1 = (torch.rand(10, 3, 100, 100) * 2) - 1
img2 = (torch.rand(10, 3, 100, 100) * 2) - 1
lpips(img1, img2)
3、相关的数据集
3.1 常用训练集
ImageNet (选部分数据使用)
OutdoorSceneTraining 数据集,包含建筑、动物、水体、天空、山体等常见户外目标,基于该数据训练的模型在盲超分中效果会更佳。分辨率不是2k,但图像细节与2k图像相同。

3.2 常用测试集
SRCNN 论文数据,进行2-3-4倍上采样,个人决定泛化参考价值不大
Set5 (5 images), Set14 (14 images),BSD200 (200 images)
4、典型的图像超分模型
这里统计了SRCNN 、ESPCN、SRGAN、ESRGAN、EBRN、PISR、real-ESRGAN模型的结构信息与精度信息。
4.1 2015 SRCNN
最早的图像超分重建算法,为SRCNN ,论文地址:http://xxx.itp.ac.cn/pdf/1501.00092 发表于 2015 年 7 月 31 日
是一个普通的基于cnn的图像超分网络,其网络结构如下所示,特点在于先将原图resize到目标尺寸后在利用cnn模型进行降噪。

该论文,选用ILSVRC 2013 ImageNet中随机的395,909个图像所训练集,set5,set14,bsd2做测试集。精度信息如下所示,在BSD200中精度最低,可见测试数据约丰富,才越能真正反映模型性能。

4.2 2016 CVPR ESPCN
论文地址:http://xxx.itp.ac.cn//pdf/1609.05158 发表时间 2016 年 9 月 23 日 CVPR
主要特点如下图所示,实现了所谓的亚像素卷积(图中的最后一个步骤),将wh的空间压力,转化为filer上的压力,而wh在空间上的显存压力时针对整个特征流的,但filer的显存压力却仅是针对于最后几层的filter。 基于亚像素卷积的思路,作者首次在1080p视频上实现了实时处理能力。重点在于速度提升,减少了中间特征图的空间分辨率,代价仅是在最后异常将filter翻了4倍

该论文,选用ImageNet中随机的50000个图像所训练集,set5,set14,bsd300,bsd500做测试集。精度信息如下所示,在这里可以看到ESPCN在多个数据集上不如上一节SRCNN中的结果,而本文中的SRCNN则远差于原文效果,或许是因为训练数据的天量差异。SRCNN用了仅40w训练图片

在同样的训练情况下,ESPCN也只是比SRCNN好一点点,基本上是肉眼不可察的优势

4.3 2017 CVPR SRGAN
论文地址: https://openaccess.thecvf.com/content_cvpr_2017/papers/Ledig_Photo-Realistic_Single_Image_CVPR_2017_paper.pdf 发表时间 2017 年 CVPR
将GAN引入了超分领域,SRGAN 的一大创新点就是提出了内容损失,SRGAN 希望整个网络在学习的过程中更加关注重建图像和原始图像的语义特征差异,而非逐个像素之间的颜色和亮度差异。SRGAN 采用改进的 VGG 网络作为特征映射,并设计了与判别器匹配的新的感知损失,克服了重构图像感 知质量低的缺点,使生成的图像更加真实。但该方法缺点在于网络结构复杂,需要训练两个网络,训练过程较长。
1、通过为MSE优化的16块深ResNet(SRResNet),通过PSNR和结构相似度(SSIM)测量具有高(4×)的标比例因子的图像SR设置了新的技术。
2、提出一个基于gan的网络优化的一个新的感知损失,用在VGG网络[48]的特征映射上计算的损失来替换基于MSE的内容损失,该损失对像素空间的变化更为不变

loss结果如下图所示,content loss为预训练的鉴别器vgg网络中的19层的输出值的MSE loss(
I
s
r
I^{sr}
Isr,
I
h
r
I^{hr}
Ihr)+ MAE loss ,adversarial loss则为vgg19的分类交叉熵

该论文,选用ImageNet中随机的35万个图像所训练集,.对于每个batch,随机裁剪96×96 HR子图像。set5,set14,bsd100,bsd300做测试集。精度信息如下所示,论证了GAN方式在HR任务中的效果,通过MOS指标证明,同时说明PSNR与SSIM结果的不合理。

具体见下图,可以见SRGAN的肉眼效果更好。

与同类方法的对比效果如下所示,可以看出SRResNet在PSNR与SSIM效果好,SRGAN在MOS指标效果好。 本文主要告诉我们,只在PSNR与SSIM论证HR效果的新方法,均可以忽略

4.4 2018 ECCV ESRGAN
论文地址: https://arxiv.org/pdf/1809.00219v2 发表时间 2018 年 ECCV
项目地址: https://github.com/xinntao/ESRGAN
它是基于SRGAN改进而来到,相比于SRGAN它在三个方面进行了改进:
1、改进了网络结构(可以看到有一个大的跳跃连接),对抗损失,感知损失
2、引入了没有批量归一化的残差密集块(RRDB)作为基本的网络构建单元
3、利用激活前的特征来改善感知损失,为亮度一致性和纹理恢复提供更强的监督

同时对于残差单元的调整,移除BN结构,修改res-block为dense-block

鉴别器loss 与原始GAN不一样,非对称loss,让真数据 减 假数据(batch平均值)的结果趋向于1,让让假数据 减 真数据(batch平均值)的结果趋向于0,也就是说使模型分不出假数据与真数据均值,同时使真数据与假数据均值保持一致。

生成器loss 其中感知损失基于vgg中间特征值计算、第二个损失应该使回归损失,第三个损失是MAE损失

在训练过程种,作者为了保持能力,先基于PSNR指标训练出一个良好的生成器,然后再用GAN的方式进行优化,最终再融合原始生成器与 gan优化后的生成器

训练数据:DIV2K+ OutdoorSceneTraining
测试数据:– Set5 [42], Set14 [43], BSD100 [44], Urban100 [45], Manga109
本文结果与SRGAN对比,在SSIM上(Set5、Set14、BSD100)不占据优势,故此没有列出来。这里有训练数据的差异问题,也有可能是因为Set5 [42], Set14 [43], BSD100 三个数据集不是2k数据,与训练数据存在偏差。

虽然ESRGAN在PSNR上优势不明显,但是在肉眼效果(毛发细节)上还是有很大改善。但论文只使用PSNR与SSIM指标,或是是有意挑选的数据(尽管如此,ESRGAN给出了丰富的图表数据,肉眼效果应该是普遍良好,只是没找到合适的评价指标)。

4.5 2019 ICCV EBRN
EBRN是ICCV2019会议上关于单幅图像超分辨率(SISR)的论文,文章认为图像中的低频和高频信息具有不同的复杂性,应该通过不同表征能力的模型进行恢复。受此启发,我们提出了一种新的嵌入式块残差网络(EBRN),它是纹理超分辨率的增量恢复过程。具体来说,模型中的不同模块可以恢复不同频率的信息。对于低频信息,我们使用网络中较浅的模块进行恢复;对于高频信息,我们使用更深的模块进行恢复。
1、不同频率的信息应该由不同复杂性的模型恢复。在不好的情况下,较低频率的信息可以被较深的模型恢复,而较高频率的信息可以被较浅的模型恢复。
2、提出了一个块残差模块(BRM),它试图恢复图像的结构和纹理,同时传递到更深的模块的难以恢复的信息。这使得每个BRM能够专注于适当频率的信息,这对于确保模型复杂度和图像频率的相关性很重要
3、提出了一种新的嵌入多个brm的技术,可以有效地提高基于每个模块输出的最终重构质量。我们还通过经验证明,所提出的模型优于最先进的水平。

模型中关于残差结构、上采样、下采样单元快的设计如下图所示

loss 部分,仅使用L2损失进行训练。 或许可以参考ESRGAN的思路进行gan的训练,可以增强模型对细节的修复能力
训练数据: DIV2K
测试数据如下图所示,与ESRGAN处于相同的效果,但训练数据比ESRGAN少多了。

同时,本文结果没有像ESRGAN一样关注毛发细节。其设计理论适用于不同的退化模型,可能在毛发上修复效果不佳,毕竟DIV2K数据集动物成分不多。

4.6 2020 PISR
论文地址:https://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123690460.pdf
项目地址:https://cvlab.yonsei.ac.kr/projects/PISR.
现在的HR模型通常需要大量的内存和计算单元。FSRCNN,由少量的卷积层组成,在使用了极少的网络参数的同时,也显示出了良好的结果。在本文中,我们实现一种新的蒸馏框架,由教师和学生网络组成,它可以大大提高FSRCNN的性能。为此,我们建议使用地面真实的高分辨率(HR)图像作为特权信息。教师中的编码器学习退化过程,HR图像的子采样,使用模仿损失。学生和教师中的解码器具有与FSRCNN相同的网络结构,试图重建HR图像。解码器中的中间特征,学生负担得起学习,通过特征蒸馏转移给学生。

其知识蒸馏如下所示,先训练好教师网络(编码器下采样+解码器上采样),然后使用的学生网络只有解码器,知识蒸馏时使用GT作为输入,然后对解码器上采样进行训练,使模型能在低分辨率输入时,输出高分辨结构。

Teacher的训练loss包含两部分,全流程的HR重构MAE loss与中间SR变量的MAE loss
student的训练loss包含重构MAE 损失与蒸馏损失(回归损失)。蒸馏效果如下所示,可以看到与教师模型相比损失很小。

训练数据:DIV2K对应的800对LR和HR图像的训练分割。HR图像中随机裁剪大小为192×192的HR补丁。根据比例因子从相应的LR图像中裁剪出LR补丁。
测试数据:Set5 [42], Set14 [43], BSD100 [44], Urban100 [45]

通过与同级别模型的对比,可以发现PISR方法的精度虽然不高,但是速度快了100倍数以上。
4.7 2021 Real-ESRGAN
论文地址:http://arxiv.org/abs/1609.04802
项目地址:https://github.com/xinntao/Real-ESRGAN
Real-ESRGAN将强大的ESRGAN扩展到一个实际的恢复应用程序,它是用纯合成数据进行训练的。具体地说,引入了一种高阶退化建模过程来更好地模拟复杂的真实世界的退化。还考虑了合成过程中常见的振铃和超调伪影。此外,采用了具有谱归一化的U-Net鉴别器来提高鉴别器能力,稳定训练动力学。广泛的比较表明,它的视觉性能比以前的各种真实数据集的工作。
Real-ESRGAN主要是设计了一种图像退化模型,具体数据处理流程如下所示

同时,与ESRGAN相比,为了适应多分辨率的任务,仅对输入采用Pixel-Unshuffle技术进行调整,使模型适用于多种超分任务

鉴别器调整:带有 spectral normalization功能的U型网络鉴别器(SN)。由于Real-ESRGAN的目标是解决比ESRGAN更大的退化空间,因此ESRGAN中的鉴别器的原始设计已不再合适。具体来说,Real-ESRGAN中的鉴别器对复杂的训练输出需要更大的鉴别能力。它还需要为局部纹理产生精确的梯度反馈,而不是区分全局样式。还将ESRGAN中的VGG型鉴别器改进为具有跳过连接的U-Net设计(图6)。UNet输出每个像素的真实度值,并可以向生成器提供详细的每像素反馈。

训练数据:DIV2K+ OutdoorSceneTraining patch_size 256
测试数据:Set5 [42], Set14 [43], BSD100 [44], Urban100 [45], Manga109
指标信息如下所示,可以看到比ESRGAN使要强很多的。这里的 Real-ESRGAN+是指对ground-truths进行sharpened 操作,使边缘更加明显。

实现效果如下所示

4.8 2022 CVPR NTIRE冠军 BSNR
现在的HR模型在卷积操作中仍然存在冗余性。在本文中,我们提出了包含两种有效设计的蓝图可分离剩余网络(BSRN)。一是使用蓝图可分离卷积(BSConv),它取代了冗余卷积操作。另一种方法是通过引入更有效的注意模块来增强模型的能力。实验结果表明,BSRN在现有的有效SR方法中取得了最先进的性能。此外,我们的模型BSRN-S的一个较小的变体在NTIRE 2022高效SR挑战模型复杂性轨道的第一名。
1、引入了BSConv来构造基本的构建块,并证明了它对SR的有效性。
2、利用两个额外计算量有限的有效注意模块来提高模型的能力。
3、提出的BSRN集成了BSConv和有效注意模块,在有效SR方面表现出了优越的性能。

ESDB模型的结构信息如下图所示,是根据RFDB模块修改而来,使用深度可分卷积进行替换,并添加ESA模块。 ESA,节省计算量的空间注意力机制、CCA节省计算量的通道注意力机制。

训练数据:Flickr2K [36] and 800 images from DIV2K
测试数据: Set5 [3], Set14 [55], B100 [41], Urban100 [20], Manga109
本文方法与PISR方法对比,在PSNR上差不多高2个点,同时在Madd上相比于PISR仅高一倍。



开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐


 24
24 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)