深度学习 | 神经网络
如果是在测试(预测)阶段,输出中数值最大的就代表了当前的分类。但是对于用于训练的网络,还远远不够,因为当前的输出y还不够漂亮,他的取值范围是随意的,算出来是什么就是什么,我们想让最终输出是一个概率的形式 —— softmax层 进行归一化。也就是说随着网络层数的增加,进行分类的准确率没有发生明显的变化,甚至可能下降。输入层是特征向量,如果输入的是一张32x32的灰度图像,那么输入层的维度就是32x
一、神经网络原理
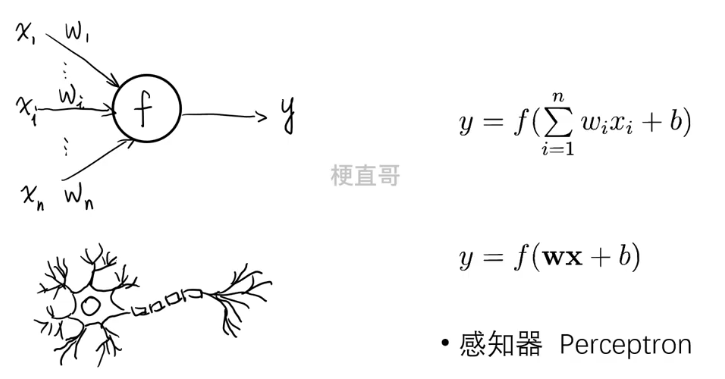
1、神经元模型
虽然叫个神经元,但骨子里还是线性模型。

2、神经网络结构
顾名思义就是由很多个神经元结点前后相连组成的一个网络。虽然长相上是个网络,但是本质上是多个线性模型的模块化组合。
在早期也被称为 多层感知机 Multi-Layer Perceptron(MLP)。

输入层是特征向量,如果输入的是一张32x32的灰度图像,那么输入层的维度就是32x32,为了处理方便,我们通常会将其reshape成列向量表示。

一系列线性方程的运算最后都可以用一个线性方程来表示。如此一来,神经网络就失去了意义,发生了“退化”。也就是说随着网络层数的增加,进行分类的准确率没有发生明显的变化,甚至可能下降。因此注入灵魂——激活层,用来进行非线性变换。

需要注意的是,每个隐藏层的计算之后都需要加一层激活层。

为什么线性计算和激活函数是分离的,不能用一个函数来替代呢?
—— 这样可以极大地简化学习的步骤,后续反向传播中就可以看到。
那么现在的神经网络就变成下图这样的形式:

我们都知道整个神经网络都是分为两个步骤的,训练和测试。
如果是在测试(预测)阶段,输出中数值最大的就代表了当前的分类。但是对于用于训练的网络,还远远不够,因为当前的输出y还不够漂亮,他的取值范围是随意的,算出来是什么就是什么,我们想让最终输出是一个概率的形式 —— softmax层 进行归一化。

神经网络输出的结果并不一定是真实的情况。

最后反向传播,优化参数 w1 w2 b等。
不同神经网络算法之间的差异主要体现在:
1、网络模型的结构
2、损失函数
3、动态求解损失函数的过程
4、过程中出现问题(如过拟合)的解决方式
二、多层感知机
1、线性网络的局限

2、怎么引入非线性

3、多层感知机 MLP

多隐藏层

4、激活函数

Sigmoid函数
在输出值不是0或1的情况下,具有非常好的非线性。
适用于二元分类问题。逻辑回归中常用。
光滑投影到(0,1)。
容易导致梯度消失。输出以0.5为中心。


Tanh函数
Sigmoid改进版,输出值压缩到(-1,1)。
输出以0为中心。
更快的收敛速度。


ReLU函数
多数情况下第一选择。
解决梯度消失问题。
计算上比Sigmoid和tanh函数快。
Dying ReLU问题,输入为负数时函数值为0,导致网络某些权重不能更新,难以训练。


Softmax函数

三、多层感知机代码实现
PyTorch搭建神经网络步骤:
![]()
# 导包
import torch
from torchvision import datasets
from torchvision import transforms
import torch.nn as nn
import torch.optim as optimdata
train_data = datasets.MNIST(root="data/mnist",train=True,transform=transforms.ToTensor(),download=True)
test_data = datasets.MNIST(root="data/mnist",train=False,transform=transforms.ToTensor(),download=True)Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to data/mnist/MNIST/raw/train-images-idx3-ubyte.gz
0%| | 0/9912422 [00:00<?, ?it/s]
Extracting data/mnist/MNIST/raw/train-images-idx3-ubyte.gz to data/mnist/MNIST/raw Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz to data/mnist/MNIST/raw/train-labels-idx1-ubyte.gz
0%| | 0/28881 [00:00<?, ?it/s]
Extracting data/mnist/MNIST/raw/train-labels-idx1-ubyte.gz to data/mnist/MNIST/raw Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz to data/mnist/MNIST/raw/t10k-images-idx3-ubyte.gz
0%| | 0/1648877 [00:00<?, ?it/s]
Extracting data/mnist/MNIST/raw/t10k-images-idx3-ubyte.gz to data/mnist/MNIST/raw Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz to data/mnist/MNIST/raw/t10k-labels-idx1-ubyte.gz
0%| | 0/4542 [00:00<?, ?it/s]
Extracting data/mnist/MNIST/raw/t10k-labels-idx1-ubyte.gz to data/mnist/MNIST/raw
batch_size = 100
train_loader = torch.utils.data.DataLoader(dataset=train_data,batch_size=batch_size,shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_data,batch_size=batch_size,shuffle=False)net
# 定义 MLP 网络 继承nn.Module
class MLP(nn.Module):
# 初始化方法
# input_size输入数据的维度
# hidden_size 隐藏层的大小
# num_classes 输出分类的数量
def __init__(self, input_size, hidden_size, num_classes):
# 调用父类的初始化方法
super(MLP, self).__init__()
# 定义第1个全连接层
self.fc1 = nn.Linear(input_size, hidden_size)
# 定义激活函数
self.relu = nn.ReLU()
# 定义第2个全连接层
self.fc2 = nn.Linear(hidden_size, hidden_size)
# 定义第3个全连接层
self.fc3 = nn.Linear(hidden_size, num_classes)
# 定义forward函数
# x 输入的数据
def forward(self, x):
# 第一层运算
out = self.fc1(x)
# 将上一步结果送给激活函数
out = self.relu(out)
# 将上一步结果送给fc2
out = self.fc2(out)
# 同样将结果送给激活函数
out = self.relu(out)
# 将上一步结果传递给fc3
out = self.fc3(out)
# 返回结果
return out
# 定义参数
input_size = 28 * 28 # 输入大小
hidden_size = 512 # 隐藏层大小
num_classes = 10 # 输出大小(类别数)
# 初始化MLP
model = MLP(input_size, hidden_size, num_classes)loss
criterion = nn.CrossEntropyLoss()optim
learning_rate = 0.001 # 学习率
optimizer = optim.Adam(model.parameters(),lr=learning_rate)training
# 训练网络
num_epochs = 10 # 训练轮数
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
# 将iamges转成向量
images = images.reshape(-1, 28 * 28)
# 将数据送到网络中
outputs = model(images)
# 计算损失
loss = criterion(outputs, labels)
# 首先将梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
if (i + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{len(train_loader)}], Loss: {loss.item():.4f}')Epoch [1/10], Step [100/600], Loss: 0.3697 Epoch [1/10], Step [200/600], Loss: 0.1534 Epoch [1/10], Step [300/600], Loss: 0.1699 Epoch [1/10], Step [400/600], Loss: 0.0657 Epoch [1/10], Step [500/600], Loss: 0.1864 Epoch [1/10], Step [600/600], Loss: 0.0878 Epoch [2/10], Step [100/600], Loss: 0.0853 Epoch [2/10], Step [200/600], Loss: 0.0340 Epoch [2/10], Step [300/600], Loss: 0.1702 Epoch [2/10], Step [400/600], Loss: 0.0413 Epoch [2/10], Step [500/600], Loss: 0.0730 Epoch [2/10], Step [600/600], Loss: 0.0986 Epoch [3/10], Step [100/600], Loss: 0.0139 Epoch [3/10], Step [200/600], Loss: 0.0562 Epoch [3/10], Step [300/600], Loss: 0.0235 Epoch [3/10], Step [400/600], Loss: 0.0731 Epoch [3/10], Step [500/600], Loss: 0.0398 Epoch [3/10], Step [600/600], Loss: 0.1915 Epoch [4/10], Step [100/600], Loss: 0.0118 Epoch [4/10], Step [200/600], Loss: 0.0911 Epoch [4/10], Step [300/600], Loss: 0.0256 Epoch [4/10], Step [400/600], Loss: 0.0879 Epoch [4/10], Step [500/600], Loss: 0.0045 Epoch [4/10], Step [600/600], Loss: 0.0191 Epoch [5/10], Step [100/600], Loss: 0.0073 Epoch [5/10], Step [200/600], Loss: 0.0125 Epoch [5/10], Step [300/600], Loss: 0.0421 Epoch [5/10], Step [400/600], Loss: 0.0424 Epoch [5/10], Step [500/600], Loss: 0.0099 Epoch [5/10], Step [600/600], Loss: 0.0043 Epoch [6/10], Step [100/600], Loss: 0.0086 Epoch [6/10], Step [200/600], Loss: 0.0070 Epoch [6/10], Step [300/600], Loss: 0.0092 Epoch [6/10], Step [400/600], Loss: 0.0152 Epoch [6/10], Step [500/600], Loss: 0.0071 Epoch [6/10], Step [600/600], Loss: 0.0038 Epoch [7/10], Step [100/600], Loss: 0.0414 Epoch [7/10], Step [200/600], Loss: 0.0159 Epoch [7/10], Step [300/600], Loss: 0.0332 Epoch [7/10], Step [400/600], Loss: 0.0054 Epoch [7/10], Step [500/600], Loss: 0.0067 Epoch [7/10], Step [600/600], Loss: 0.0072 Epoch [8/10], Step [100/600], Loss: 0.0030 Epoch [8/10], Step [200/600], Loss: 0.0046 Epoch [8/10], Step [300/600], Loss: 0.0492 Epoch [8/10], Step [400/600], Loss: 0.0126 Epoch [8/10], Step [500/600], Loss: 0.0592 Epoch [8/10], Step [600/600], Loss: 0.0073 Epoch [9/10], Step [100/600], Loss: 0.0520 Epoch [9/10], Step [200/600], Loss: 0.0031 Epoch [9/10], Step [300/600], Loss: 0.0036 Epoch [9/10], Step [400/600], Loss: 0.0077 Epoch [9/10], Step [500/600], Loss: 0.0097 Epoch [9/10], Step [600/600], Loss: 0.0029 Epoch [10/10], Step [100/600], Loss: 0.0002 Epoch [10/10], Step [200/600], Loss: 0.0021 Epoch [10/10], Step [300/600], Loss: 0.0235 Epoch [10/10], Step [400/600], Loss: 0.0004 Epoch [10/10], Step [500/600], Loss: 0.0343 Epoch [10/10], Step [600/600], Loss: 0.0249
test
# 测试网络
with torch.no_grad():
correct = 0
total = 0
# 从 test_loader中循环读取测试数据
for images, labels in test_loader:
# 将images转成向量
images = images.reshape(-1, 28 * 28)
# 将数据送给网络
outputs = model(images)
# 取出最大值对应的索引 即预测值
_, predicted = torch.max(outputs.data, 1)
# 累加label数
total += labels.size(0)
# 预测值与labels值比对 获取预测正确的数量
correct += (predicted == labels).sum().item()
# 打印最终的准确率
print(f'Accuracy of the network on the 10000 test images: {100 * correct / total} %')Accuracy of the network on the 10000 test images: 98.01 %
save
torch.save(model,"mnist_mlp_model.pkl")
四、回归问题
Chapter-04/4-6 线性回归代码实现.ipynb · 梗直哥/Deep-Learning-Code - Gitee.com
五、多分类问题
Chapter-04/4-8 多分类问题代码实现.ipynb · 梗直哥/Deep-Learning-Code - Gitee.com

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐


 13
13 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)