【学习总结+论文复现】知识蒸馏Knowledge Distillation学习一条龙(完结)
本文章以2020年《Contrastive Representation Distillation》的知识蒸馏技术为学习基础来学习知识蒸馏技术。此外还涉及了最新的知识蒸馏方法。例如,DKD,KD++,Review KD,多出口网络+集成学习KD,DisWOT,MSFF,CMKD,CTKD,MGD,PEFD,SimKD,Logits标准化KD,SDD。
知识蒸馏学习一条龙!!!!
欢迎大家收藏,点赞。
前言
大模型大行其道,但是当实际落地时,需要考虑硬件和运行功耗,因此企业更希望部署的是“小”模型。因此学习一些知识蒸馏技术就成为一些算法工程师必备的技能点。
目录
(KD) - Distilling the Knowledge in a Neural Network
思考:KD方法中,教师的温度和学生的温度一样,如果不一样呢?会有什么效果?
思考后,推荐阅读CTKD、Logit Standardization KD.
(FitNets) - Hints for Thin Deep Nets
思考:中间层有那么多,浅层深层,到底哪一层蒸馏效果好,还是说融合后效果好?
思考后,推荐阅读:《Distilling Knowledge via Knowledge Review》 2022
思考后,推荐阅读:《RAndom Intermediate Layer Knowledge Distillation》 2022
思考:空间信息和语义信息对于分类任务来说同样重要,如何设计出合理的蒸馏方案?
(SP) - Similarity-Preserving Knowledge Distillation
推荐阅读,DisWOT在SP的基础上额外增加了关系相似性矩阵。
(CCKD) - Correlation Congruence for Knowledge Distillation
(VID) - Variational Information Distillation for Knowledge Transfer
(CMKD) - Transformer的崛起,Transformer/CNN如何设计蒸馏方案?
(RKD) - Relational Knowledge Distillation
(PKT) - Probabilistic Knowledge Transfer for deep representation learning
(AB) - Knowledge Transfer via Distillation of Activation Boundaries Formed by Hidden Neurons
(FT) - Paraphrasing Complex Network: Network Compression via Factor Transfer
(NST) - Like what you like: knowledge distill via neuron selectivity transfer
(CRD) - Contrastive Representation Distillation
(DKD) - Decoupled Knowledge Distillation
(不需要老师的KD) - Deep Mutual Learning
(CTKD) - Curriculum Temperature for Knowledge Distillation
(SimKD) - Knowledge Distillation with the Reused Teacher Classifier
(MGD) - Masked Generative Distillation
(ReviewKD) - Distilling Knowledge via Knowledge Review
(PEFD) - Improved Feature Distillation via Projector Ensemble
(KD++) - Improving Knowledge Distillation via Regularizing Feature Norm and Direction
《Teacher-student collaborative knowledge distillation for image classification》
(SDD) - Scale Decoupled Distillation
(Logits标准化KD) - Logit Standardization in Knowledge Distillation
结束语:你没有落后,也没有领先,在命运为你安排的时区里,一切都准时。
开始:学习开始,冲冲冲555
CRD(2020)代码复现(亲测能跑通!!!)
此链接是2020年的一篇经典论文。
本文章复现了KD、FitNet、AT、SP、CC、VID、RKD、PKT、AB、FT、FSP、NST等知识蒸馏方法。本文在代码中对以上的方法进行详细介绍,以及如何实现。此外,还涉及到了最新的知识蒸馏方法,例如DKD,KD++,Review KD,多出口网络+集成学习KD,DisWOT,MSFF,CMKD,CTKD,MGD,PEFD,SimKD,Logits标准化KD,SDD。
首先需要将代码调试通,在windows环境下跑起来。
1. 先下载代码,然后解压到本地目录,链接在上面。
2. 打开pycahrm,打开项目。(我的python版本是3.9)
3. 配置conda环境。文件---设置---搜索python解释器---点击Python解释器最右方的六芒星,添加环境---Conda环境---确定。

4. 项目介绍:

CRD目录:本论文的核心思想模块。
dataset目录:数据集的加载设置。
distiller_zoo目录:各种蒸馏方法的模块,包括KD、FitNet、AT、SP、CC、VID、RKD、PKT、AB、FT、FSP、NST等知识蒸馏方法。
helper目录:训练网络需要的帮助性模块。
models目录:各种网络模型,包括教师模型和学生模型。
scripts目录:shell命令。
train_student和train_teacher。一个是训练学生所需(训练学生就需要用到知识蒸馏方法,不是单独训练一个小模型),一个是训练教师所需。
5. 直接运行train_student,遇到问题再见招拆招。

这里报错,原因是没有添加教师的路径。找不到教师模型。

这里的参数,--path_t就是教师路径,这里默认为None。需要我们添加。

此时,项目中还没有训练好的教师网络,但还好作者提供了训练好的教师网络,可以去下载。
可以使用终端命令或者手动复制这个网址到浏览器上下载。下载完之后把文件放入到项目中。

我将这些文件下载下来保存到了scripts/save/models里面,如下图所示。

以resnet32x4_vanilla作为教师,鼠标右键复制绝对路径,添加到train_student.py文件中的超参数
--path_t中,并将路径中的 / 替换为 \ 如下图所示。

运行train_student.py。此时又报错,

找到问题所在,如下图所示。原因是这个:符号,在windows系统下创建一个文件不能用冒号命名。

将这个名称修改一下即可,我将符号:修改为符号~ 如下图所示。

然后我们将学生模型resnet8修改为resnet8x4,choices里面有,直接复制过来。
因为resnet32x4和resnet8x4是一对。如下两张图所示。


此时开始自动下载数据集。等待下载完或者自行到网上下载。

项目文件里面多了一个data文件,里面装的就是数据集。

然后再次运行train_student,又报错。这个错误是因为我的电脑线程最大是6.

将超参数num_works,默认值8,改为6.如下如所示。

还有一个错误,如下图所示。

这是因为view()需要Tensor中的元素地址是连续的,但可能出现Tensor不连续的情况,所以先用 .contiguous()。将其在内存中变成连续分布即可。如下图所示。

再次运行train_student.py。又报错。这是因为pytorch版本的原因。导致读取数据没有读取到。

找到dataset里面的cifar100. 将括号括起来的注释掉,改为下图所示。

再次运行train_student.py。又报错。

这是因为损失的权重默认为None,我们需要修改一下。如下图所示,将alpha设置为1,beta设置为0.


代码又报错。

超参数distill默认值是kd,如下图所示。因此去distiller_zoo/KD.py中去找原因。

将size_average=False替换为reduction='sum',如下面两张图所示。

如下图所示,到这里,代码就跑通啦!!!

下面我们开始进一步学习。
(KD) - Distilling the Knowledge in a Neural Network
这篇论文是知识蒸馏的开山之作。链接: Distilling the Knowledge in a Neural Network | Papers With Code
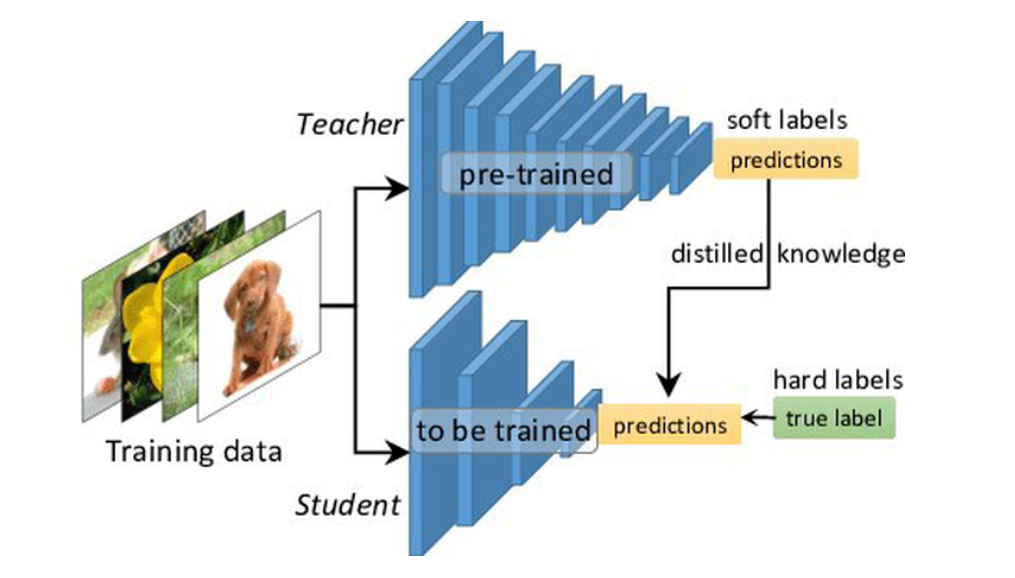
意思就是大模型和小模型的输出logit(logit是input x通过layer层之后的输出)通过温度T(超参数)柔滑输出来计算损失。此外,小网络还向真实标签学习。
将大网络比作教师,小网络比作学生,真实标签比作课本。如下图所示。
学生向教师学习,同时也向课本学习。

在CRD的代码中有3种损失,在helper/loops.py里,如下图所示。其中,loss_cls是学生模型的输出和目标标签的损失(向课本学习),loss_div是教师输出和学生输出的损失(学生向教师学习)。还有其他的一些蒸馏方法由loss_kd来表示。

训练学生模型的总损失就由3部分组成,如下所示。gamma、alpha、beta分别是损失的权重(超参数)。
gamma、alpha、beta的超参数设置在train_student.py文件里,如下图所示。

(KD) - Distilling the Knowledge in a Neural Network这篇论文是只用到了教师和学生的损失与学生与真实标签的损失。因此,实现此方法,不需要beta,因此把beta设置成0。
KD代码实现,在distiller_zoo/KD.py中,如下图所示。

这里的温度设置在train_student.py文件中。kd_T表示温度的大小,作者默认设置为4。

KD用到的公式

思考:为什么KD方法有效?
答:因为超参数温度T可以柔化教师和学生的输出,让学生不仅仅知道正确类别的信息,也知道错误类别的信息。
实验:温度T的消融实验

实验结果分析:使用np.array()来模拟网络的输出。如右图所示,温度越高,越能拉拢类与类之间的区别,当温度为100的时候,Cat、Dog、Donkey、Horse之间的区别就很难以区分了。相反,如果温度越低,类别之间的区别就越大。特别地,当温度为1的时候,相当于没有温度。实验结果证明,温度T可以对网络模型的输出起到柔化的作用。
思考:KD方法中,教师的温度和学生的温度一样,如果不一样呢?会有什么效果?
思考后,推荐阅读CTKD、Logit Standardization KD.
对于知识蒸馏中的温度T问题,推荐阅读《Curriculum Temperature for Knowledge Distillation》:链接: Curriculum Temperature for Knowledge Distillation | Papers With Code
--这篇论文(CTKD)将超参数温度动态化,网络会自动学习温度,无需手动设置。2023
还推荐阅读《Logit Standardization in Knowledge Distillation》
链接: Logit Standardization in Knowledge Distillation | Papers With Code
--这篇论文探讨了师生温度弊端问题,并提出了Logit标准化来解决。 CVPR 2024
(FitNets) - Hints for Thin Deep Nets
首次提出用中间层蒸馏,链接: FitNets: Hints for Thin Deep Nets | Papers With Code
FitNets,用到的公式:


公式1和公式2都是标准KD使用的公式,也就是这篇论文(KD) - Distilling the Knowledge in a Neural Network

FitNets在KD的基础上增加了另一种学习方式,基于中间层/隐藏层的学习方式(基于特征的知识蒸馏)如下图所示。前面第一篇论文是基于Logits的知识蒸馏。

图(a)表示更浅更宽的教师模型和更窄更深的学生模型。
图(b)表示将图(a)中的窄学生通过Wr(红色)给他拓展宽(蓝色),使其与教师Whint(绿色)的维度相匹配。
图(c)表示将图(b)绿色作为Wr(教师部分),蓝色的作为Ws(学生部分)。
为了深刻理解,直接看源码。如下图,如果是hint蒸馏,执行4行代码。
先是设定了损失函数,然后设置了一个学生的回归(regress_s)调用了函数ConvReg(),传入两个参数(学生隐藏层维度,教师隐藏层维度),最后将regress_s放入到模型、并添加为可训练列表中。

此方法的损失函数,为标准的均方差损失函数MSE。具体内容可以参考链接: PyTorch torch.nn.MSELoss官网文档示例output计算方法解释 - 知乎

卷积回归,如下图所示需要传入3个参数,学生维度,教师维度,是否使用relu激活函数,默认使用。当学生的维度 = 2* 教师维度,使用3x3的卷积使其相匹配;当学生的维度*2 = 教师维度时,使用4x4的反卷积,使两者匹配;当学生维度>=教师维度,使用卷积使其匹配。
Fitnets方法输入的特征为教师和学生的中间特征,默认为第二层,如下图所示。
helper/loops.py

train_student.py中超参数

在forward传播中,调用conv也就是使其维度匹配的卷积运算。如果使用relu激活,那就先批量归一化,然后再激活。否则就只批量归一化。

【创新点】引入了来自教师网络的提示。提示被定义为教师负责指导学生学习过程的隐藏层的输出。在我们的案例中,我们选择提示作为教师网络的中间层。同样,我们选择引导层作为学生网络的中间层。
思考:中间层有那么多,浅层深层,到底哪一层蒸馏效果好,还是说融合后效果好?
思考后,推荐阅读:《Distilling Knowledge via Knowledge Review》 2022
链接: Distilling Knowledge via Knowledge Review | Papers With Code
这篇论文将多个阶段的中间层进行了融合,并设计了空间金字塔池化来匹配不同维度的教师学生。
思考后,推荐阅读:《RAndom Intermediate Layer Knowledge Distillation》 2022
链接: https://arxiv.org/pdf/2109.10164
通常教师的中间层多,学生中间层少,这篇论文将随机选取教师的中间层与学生的中间层指导。
(AT) - Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer
创新点:随着注意力的热潮,注意力也被用到了知识蒸馏当中。本研究通过将教师的注意力转移到学生的注意力上学习。
通过注意力转移进行知识蒸馏。链接: Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer | Papers With Code

如由上图所示,将教师的注意力转移到学生的注意力上。具体损失为,教师特征层的输出经过注意力计算,学生特征层的输出经过注意力计算。两者相减,再取平均。更为详细如下所示:

具体代码,以及详细解析如下所示:

self.p是构造函数的超惨是,意思是p次幂。
at函数是注意力函数。首先,将输入特征f进行幂运算,指数为self.p。然后对每个通道进行均值操作,得到每个通道的平均值mean(1)。接着,将得到的平均值展平为一维向量view(f.size(0),-1),并将结果reshape为原始特征的大小。最后,返回归一化后的结果作为注意力权重。
at_loss是计算教师特征与学生特征的损失函数。特征为[b,c,h,w],s_H, t_H意思是特征的高和宽,当教师特征和学生特征高和宽不一致时,通过F.adaptive_avg_pool2d()自适应池化操作将两者相匹配。最后返回值调用注意力函数at(self, f),将教师特征图注意力与学生特征注意力相减,再平方pow(2),再取均值mean()。
在前向传播的过程中(forward函数),将打包的特征循环遍历并调用at_loss()计算结果。
forward函数传入的特征为教师的第二层特征一直到最后一层特征。如下图所示。
思考:空间信息和语义信息对于分类任务来说同样重要,如何设计出合理的蒸馏方案?
空间信息指的是特征在图像中的位置和排列方式,而语义信息指的是特征所代表的内容和含义。在分类任务中,空间信息可以帮助模型捕捉对象的形状、纹理等视觉特征,而语义信息则可以帮助模型理解对象的类别和属性。
思考后,推荐阅读MSFF(学长的论文)
AT方法只对空间信息进行了蒸馏,缺少语义信息。因此,如何设计一个有空间信息和语义信息的蒸馏方案是一个值得思考的问题。现有的工作MSFF(学长的论文),基于多阶段特征融合的知识蒸馏方法、设备及介质.pdf-原创力文档 很好的解决了这个问题。
(SP) - Similarity-Preserving Knowledge Distillation
创新点:本研究通过设计了一种新的知识蒸馏损失:语义相似的输入往往会在训练好的网络中引发相似的激活模式。相似性保持知识提炼指导学生网络的训练,使得在教师网络中产生相似(不相似)激活的输入对在学生网络中产生相似(不相似)激活。
如下图所示,特征图[b,c,h,w]将c*w*h融到一起,变成一个b*b的二维矩阵,然后计算两个矩阵(Gram矩阵)之间的损失。

具体损失以及详细解析如下图所示。此方法输入的特征为最后的特征图。例如resnet8x4中的最后一层特征是[batch_size,256,8,8]。

models/resnet.py,feat_s[-2]就是这一层特征,如下图所示。

损失函数以及详细解析如下所示,

推荐阅读,DisWOT在SP的基础上额外增加了关系相似性矩阵。
此外,《DisWOT: Student Architecture Search for Distillation WithOut Training》在SP蒸馏方法的这个工作的基础之上,还增加了关系相似性。如图(a)所示。
DisWOT的论文: https://arxiv.org/pdf/2303.15678v1
DisWOT将神经架构搜索(NAS)与知识蒸馏(KD)相结合,DisWOT是标题的首字母缩写。

文章末尾给出了代码,如下图所示。可以与SP蒸馏方法相比较有何区别。

(CCKD) - Correlation Congruence for Knowledge Distillation
CCKD分析了实例与实例之间的相关性,提出实例之间的相关性对于蒸馏也是很有效果的。
论文连接: Correlation Congruence for Knowledge Distillation | Papers With Code

如上图所示,将教师实例之间的相关性传递给学生。具体代码以及详细解析如下所示。
train_student.py中

构造Correlation()方法,前向传播计算教师特征和学生特征的绝对值,然后实例之间相乘求和取平均。delta[:-1] 是一个切片操作,它创建一个新的列表或张量,其中包含原始列表或张量 delta 的所有元素,除了最后一个元素。delta[:-1] 的语法用于选择列表的开始到倒数第二个元素的所有元素。假定输入为[64,100]切片后就是[63,100]。

这个方法传入的特征是教师和学生的最后输出Logits。

(VID) - Variational Information Distillation for Knowledge Transfer
VID提出了基于信息论的知识蒸馏框架。该框架最大化教师和学生网络之间的互信息。(互信息的公式比较复杂,可以先学习一下。)
论文连接: Variational Information Distillation for Knowledge Transfer | Papers With Code

VID蒸馏方法的输入是第二层到最后一层特征。train_student中。

训练每一轮的计算。helper/loops.py
VID的蒸馏类。在前向传播中,先用池化在空间维度进行匹配。然后经过卷积的回归器,经过互信息的公式分别计算出与目标(教师)的损失。

(CMKD) - Transformer的崛起,Transformer/CNN如何设计蒸馏方案?
知识蒸馏作为一种通用的模型压缩技术,将transformer压缩成CNN或者CNN压缩为transformer效果怎样呢?如何蒸馏呢?
思考后,推荐阅读CMKD
推荐阅读论文:《CMKD: CNN/Transformer-Based Cross-Model Knowledge Distillation for Audio Classification》 2022
(RKD) - Relational Knowledge Distillation
RKD也是实例关系的知识蒸馏方法,这篇文章提出了惩罚关系中结构差异的距离方向和角度方向的蒸馏损失。
论文链接: Relational Knowledge Distillation | Papers With Code
传统蒸馏是实例与实例之间点对点蒸馏,RKD是结构与结构蒸馏。如下图所示。

训练过程中创建RKD方法。

在每一轮的传输过程中,输入教师和学生的最终输出Logits。

RKDLoss类,主要创新是距离损失和角度损失。
class RKDLoss(nn.Module):
"""关系知识蒸馏,CVPR2019"""
def __init__(self, w_d=25, w_a=50):
super(RKDLoss, self).__init__()
self.w_d = w_d
self.w_a = w_a
def forward(self, f_s, f_t):
student = f_s.view(f_s.shape[0], -1) # 将学生特征展平
teacher = f_t.view(f_t.shape[0], -1) # 将教师特征展平
# RKD距离损失
with torch.no_grad():
t_d = self.pdist(teacher, squared=False) # 计算教师特征之间的距离
mean_td = t_d[t_d > 0].mean() # 计算非零距离的平均值
t_d = t_d / mean_td # 标准化距离
d = self.pdist(student, squared=False) # 计算学生特征之间的距离
mean_d = d[d > 0].mean() # 计算非零距离的平均值
d = d / mean_d # 标准化距离
loss_d = F.smooth_l1_loss(d, t_d) # 计算距离损失
# RKD角度损失
with torch.no_grad():
td = (teacher.unsqueeze(0) - teacher.unsqueeze(1)) # 计算教师特征之间的差值
norm_td = F.normalize(td, p=2, dim=2) # 归一化教师特征之间的差值
t_angle = torch.bmm(norm_td, norm_td.transpose(1, 2)).view(-1) # 计算教师特征之间的角度
sd = (student.unsqueeze(0) - student.unsqueeze(1)) # 计算学生特征之间的差值
norm_sd = F.normalize(sd, p=2, dim=2) # 归一化学生特征之间的差值
s_angle = torch.bmm(norm_sd, norm_sd.transpose(1, 2)).view(-1) # 计算学生特征之间的角度
loss_a = F.smooth_l1_loss(s_angle, t_angle) # 计算角度损失
loss = self.w_d * loss_d + self.w_a * loss_a # 综合距禋损失和角度损失
return loss
@staticmethod
def pdist(e, squared=False, eps=1e-12):
e_square = e.pow(2).sum(dim=1) # 计算特征的平方和
prod = e @ e.t() # 计算特征之间的乘积
res = (e_square.unsqueeze(1) + e_square.unsqueeze(0) - 2 * prod).clamp(min=eps) # 计算特征之间的欧氏距离
if not squared:
res = res.sqrt() # 如果不是平方距离,则开方得到欧氏距离
res = res.clone() # 克隆结果
res[range(len(e)), range(len(e))] = 0 # 对角线元素置零
return res(PKT) - Probabilistic Knowledge Transfer for deep representation learning
PKT主要采用概率知识转移的思想:在学生模型中特征向量的分布应该与在老师模型特征向量的分布近似。网络的输出可以被视为概率,通过核函数之后,利用KL散度函数计算损失,然后将损失反向传递。
论文链接: Learning Deep Representations with Probabilistic Knowledge Transfer | SpringerLink

PKT采用的核函数有:

PKT采用的是cos核函数。老师和学生模型的条件概率分布为:

总的损失为学生和老师概率的散度之和:

class PKT(nn.Module):
"""Probabilistic Knowledge Transfer for deep representation learning
Code from author: https://github.com/passalis/probabilistic_kt"""
def __init__(self):
super(PKT, self).__init__()
def forward(self, f_s, f_t):
return self.cosine_similarity_loss(f_s, f_t)
@staticmethod
def cosine_similarity_loss(output_net, target_net, eps=0.0000001):
# Normalize each vector by its norm
output_net_norm = torch.sqrt(torch.sum(output_net ** 2, dim=1, keepdim=True))
output_net = output_net / (output_net_norm + eps)
output_net[output_net != output_net] = 0
target_net_norm = torch.sqrt(torch.sum(target_net ** 2, dim=1, keepdim=True))
target_net = target_net / (target_net_norm + eps)
target_net[target_net != target_net] = 0
# Calculate the cosine similarity
model_similarity = torch.mm(output_net, output_net.transpose(0, 1))
target_similarity = torch.mm(target_net, target_net.transpose(0, 1))
# Scale cosine similarity to 0..1
model_similarity = (model_similarity + 1.0) / 2.0
target_similarity = (target_similarity + 1.0) / 2.0
# Transform them into probabilities
model_similarity = model_similarity / torch.sum(model_similarity, dim=1, keepdim=True)
target_similarity = target_similarity / torch.sum(target_similarity, dim=1, keepdim=True)
# Calculate the KL-divergence
loss = torch.mean(target_similarity * torch.log((target_similarity + eps) / (model_similarity + eps)))
return loss
蒸馏传入的特征是模型的最终输出Logits。

(AB) - Knowledge Transfer via Distillation of Activation Boundaries Formed by Hidden Neurons
AB方法让教师网络层的神经元的激活边界尽量和学生网络的一样。所谓的激活边界指的是分离超平面(针对的是RELU这种激活函数),其决定了神经元的激活与失活。AB提出的激活转移损失,让教师网络与学生网络之间的分离边界尽可能一致。
论文链接: https://arxiv.org/pdf/1811.03233

class ABLoss(nn.Module):
"""通过隐藏神经元形成的激活边界的知识传递
代码:https://github.com/bhheo/AB_distillation
"""
def __init__(self, feat_num, margin=1.0):
super(ABLoss, self).__init__()
self.w = [2**(i-feat_num+1) for i in range(feat_num)] # 初始化权重
self.margin = margin # 初始化边界
def forward(self, g_s, g_t):
bsz = g_s[0].shape[0] # 获取批次大小
losses = [self.criterion_alternative_l2(s, t) for s, t in zip(g_s, g_t)] # 计算损失
losses = [w * l for w, l in zip(self.w, losses)] # 加权损失
losses = [l / bsz for l in losses] # 损失除以批次大小
losses = [l / 1000 * 3 for l in losses] # 损失乘以3
return losses
def criterion_alternative_l2(self, source, target):
loss = ((source + self.margin) ** 2 * ((source > -self.margin) & (target <= 0)).float() +
(source - self.margin) ** 2 * ((source <= self.margin) & (target > 0)).float()) # 计算交替L2损失
return torch.abs(loss).sum() # 返回绝对值的和构造ABLoss。

每一轮的训练中不需要loss_kd损失。

(FT) - Paraphrasing Complex Network: Network Compression via Factor Transfer
FT蒸馏方法是对网络的最后一层特征图(例如,feat[-2].shape=[64,256,8,8])进行编码和解码的过程,提取出一个factor矩阵,使用教师factor来指导学生factor。
论文链接: https://arxiv.org/pdf/1802.04977

FT计算公式为:

训练时,构造编码器、解码器。并初始化,将编码器和解码器添加到可训练模型列表中。

编码器和解码器,编码器是3个3x3卷积,解码器是3个3x3的反卷积。
class Paraphraser(nn.Module):
"""Paraphrasing Complex Network: Network Compression via Factor Transfer"""
def __init__(self, t_shape, k=0.5, use_bn=False):
super(Paraphraser, self).__init__()
in_channel = t_shape[1]
out_channel = int(t_shape[1] * k)
self.encoder = nn.Sequential(
nn.Conv2d(in_channel, in_channel, 3, 1, 1),
nn.BatchNorm2d(in_channel) if use_bn else nn.Sequential(),
nn.LeakyReLU(0.1, inplace=True),
nn.Conv2d(in_channel, out_channel, 3, 1, 1),
nn.BatchNorm2d(out_channel) if use_bn else nn.Sequential(),
nn.LeakyReLU(0.1, inplace=True),
nn.Conv2d(out_channel, out_channel, 3, 1, 1),
nn.BatchNorm2d(out_channel) if use_bn else nn.Sequential(),
nn.LeakyReLU(0.1, inplace=True),
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(out_channel, out_channel, 3, 1, 1),
nn.BatchNorm2d(out_channel) if use_bn else nn.Sequential(),
nn.LeakyReLU(0.1, inplace=True),
nn.ConvTranspose2d(out_channel, in_channel, 3, 1, 1),
nn.BatchNorm2d(in_channel) if use_bn else nn.Sequential(),
nn.LeakyReLU(0.1, inplace=True),
nn.ConvTranspose2d(in_channel, in_channel, 3, 1, 1),
nn.BatchNorm2d(in_channel) if use_bn else nn.Sequential(),
nn.LeakyReLU(0.1, inplace=True),
)
def forward(self, f_s, is_factor=False):
factor = self.encoder(f_s)
if is_factor:
return factor
rec = self.decoder(factor)
return factor, rec
class Translator(nn.Module):
def __init__(self, s_shape, t_shape, k=0.5, use_bn=True):
super(Translator, self).__init__()
in_channel = s_shape[1]
out_channel = int(t_shape[1] * k)
self.encoder = nn.Sequential(
nn.Conv2d(in_channel, in_channel, 3, 1, 1),
nn.BatchNorm2d(in_channel) if use_bn else nn.Sequential(),
nn.LeakyReLU(0.1, inplace=True),
nn.Conv2d(in_channel, out_channel, 3, 1, 1),
nn.BatchNorm2d(out_channel) if use_bn else nn.Sequential(),
nn.LeakyReLU(0.1, inplace=True),
nn.Conv2d(out_channel, out_channel, 3, 1, 1),
nn.BatchNorm2d(out_channel) if use_bn else nn.Sequential(),
nn.LeakyReLU(0.1, inplace=True),
)
def forward(self, f_s):
return self.encoder(f_s)
每一轮都需要传入最后特征图,例如[64,256,8,8]这样的。

最终的FT类:
class FactorTransfer(nn.Module):
"""复杂网络的释义:通过因子转移进行网络压缩,NeurIPS 2018"""
def __init__(self, p1=2, p2=1):
super(FactorTransfer, self).__init__() # 初始化函数
self.p1 = p1 # 初始化参数p1
self.p2 = p2 # 初始化参数p2
def forward(self, f_s, f_t):
return self.factor_loss(f_s, f_t) # 前向传播函数调用因子损失函数
def factor_loss(self, f_s, f_t):
s_H, t_H = f_s.shape[2], f_t.shape[2] # 获取输入特征的维度
if s_H > t_H:
f_s = F.adaptive_avg_pool2d(f_s, (t_H, t_H)) # 如果输入特征的维度大于目标特征的维度,则进行自适应平均池化
elif s_H < t_H:
f_t = F.adaptive_avg_pool2d(f_t, (s_H, s_H)) # 如果输入特征的维度小于目标特征的维度,则进行自适应平均池化
else:
pass # 否则不做任何处理
if self.p2 == 1:
return (self.factor(f_s) - self.factor(f_t)).abs().mean() # 计算因子之间的绝对值损失的平均值
else:
return (self.factor(f_s) - self.factor(f_t)).pow(self.p2).mean() # 计算因子之间的平方损失的平均值
def factor(self, f):
return F.normalize(f.pow(self.p1).mean(1).view(f.size(0), -1)) # 计算归一化后的因子(FSP) - A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning
FSP认为教学生网络不同层输出的feature之间的关系比教学生网络结果好。

定义了FSP矩阵来定义网络内部特征层之间的关系,是一个Gram矩阵反映老师教学生的过程。

使用的是L2 Loss进行约束FSP矩阵。

训练的时候需要构造FSP()。参数需要每一层教师和学生的特征形状。

每一轮的训练当中不需要loss_kd。

最终的FSP类。
class FSP(nn.Module):
"""知识蒸馏的礼物:
快速优化,网络最小化和迁移学习"""
def __init__(self, s_shapes, t_shapes):
super(FSP, self).__init__() # 初始化函数
assert len(s_shapes) == len(t_shapes), 'unequal length of feat list' # 断言输入特征列表长度相等
s_c = [s[1] for s in s_shapes] # 获取源特征通道数列表
t_c = [t[1] for t in t_shapes] # 获取目标特征通道数列表
if np.any(np.asarray(s_c) != np.asarray(t_c)):
raise ValueError('num of channels not equal (error in FSP)') # 如果通道数不相等,则引发值错误
def forward(self, g_s, g_t):
s_fsp = self.compute_fsp(g_s) # 计算源特征的FSP
t_fsp = self.compute_fsp(g_t) # 计算目标特征的FSP
loss_group = [self.compute_loss(s, t) for s, t in zip(s_fsp, t_fsp)] # 计算损失组
return loss_group
@staticmethod
def compute_loss(s, t):
return (s - t).pow(2).mean() # 计算损失
@staticmethod
def compute_fsp(g):
fsp_list = [] # 初始化FSP列表
for i in range(len(g) - 1):
bot, top = g[i], g[i + 1] # 获取底部和顶部特征
b_H, t_H = bot.shape[2], top.shape[2] # 获取底部和顶部特征的高度
if b_H > t_H:
bot = F.adaptive_avg_pool2d(bot, (t_H, t_H)) # 如果底部特征高度大于顶部特征高度,则进行自适应平均池化
elif b_H < t_H:
top = F.adaptive_avg_pool2d(top, (b_H, b_H)) # 如果底部特征高度小于顶部特征高度,则进行自适应平均池化
else:
pass # 否则不做任何处理
bot = bot.unsqueeze(1) # 在第一维度上增加维度
top = top.unsqueeze(2) # 在第二维度上增加维度
bot = bot.view(bot.shape[0], bot.shape[1], bot.shape[2], -1) # 改变形状
top = top.view(top.shape[0], top.shape[1], top.shape[2], -1) # 改变形状
fsp = (bot * top).mean(-1) # 计算FSP
fsp_list.append(fsp) # 将FSP添加到列表中
return fsp_list # 返回FSP列表(NST) - Like what you like: knowledge distill via neuron selectivity transfer
NST使用新的损失函数最小化教师网络与学生网络之间的Maximum Mean Discrepancy(MMD), 文中选择的是对其教师网络与学生网络之间神经元选择样式的分布。
论文链接: https://arxiv.org/pdf/1707.01219

损失函数:

使用核技巧(对应下面poly kernel)并进一步展开以后可得:

实际上提供了Linear Kernel、Poly Kernel、Gaussian Kernel三种,这里实现只给了Poly这种,这是因为Poly这种方法可以与KD进行互补,这样整体效果会非常好。
每一轮的训练中将第二层到最后一层特征打包计算损失。

训练时,构造NSTLoss()

NST实现类。
class NSTLoss(nn.Module):
"""像你喜欢的那样:通过神经元选择性转移进行知识蒸馏"""
def __init__(self):
super(NSTLoss, self).__init__() # 初始化函数
pass # 什么也不做
def forward(self, g_s, g_t):
return [self.nst_loss(f_s, f_t) for f_s, f_t in zip(g_s, g_t)] # 对每一对源特征和目标特征计算NST损失
def nst_loss(self, f_s, f_t):
s_H, t_H = f_s.shape[2], f_t.shape[2] # 获取源特征和目标特征的高度
if s_H > t_H:
f_s = F.adaptive_avg_pool2d(f_s, (t_H, t_H)) # 如果源特征的高度大于目标特征的高度,则进行自适应平均池化
elif s_H < t_H:
f_t = F.adaptive_avg_pool2d(f_t, (s_H, s_H)) # 如果源特征的高度小于目标特征的高度,则进行自适应平均池化
else:
pass # 否则不做任何处理
f_s = f_s.view(f_s.shape[0], f_s.shape[1], -1) # 改变源特征的形状
f_s = F.normalize(f_s, dim=2) # 对源特征进行归一化
f_t = f_t.view(f_t.shape[0], f_t.shape[1], -1) # 改变目标特征的形状
f_t = F.normalize(f_t, dim=2) # 对目标特征进行归一化
# 将full_loss设置为False以避免不必要的计算
full_loss = True
if full_loss:
return (self.poly_kernel(f_t, f_t).mean().detach() + self.poly_kernel(f_s, f_s).mean()
- 2 * self.poly_kernel(f_s, f_t).mean()) # 计算完整的NST损失
else:
return self.poly_kernel(f_s, f_s).mean() - 2 * self.poly_kernel(f_s, f_t).mean() # 计算简化的NST损失
def poly_kernel(self, a, b):
a = a.unsqueeze(1) # 在第一维度上增加维度
b = b.unsqueeze(2) # 在第二维度上增加维度
res = (a * b).sum(-1).pow(2) # 计算多项式核
return res # 返回结果(CRD) - Contrastive Representation Distillation
CRD首次将对比学习应用在知识蒸馏当中。经典!!!
将对比学习引入知识蒸馏中,其目标修正为:学习一个表征,让正样本对的教师网络与学生网络尽可能接近,负样本对教师网络与学生网络尽可能远离。
论文链接: https://arxiv.org/abs/1910.10699v2
构建的对比学习问题表示如下:
 整体的损失函数表示如下:
整体的损失函数表示如下:
 实现类,
实现类,
class ContrastLoss(nn.Module):
"""
对比损失,对应于Eq (18)
"""
def __init__(self, n_data):
super(ContrastLoss, self).__init__() # 初始化函数
self.n_data = n_data # 设置数据数量
def forward(self, x):
bsz = x.shape[0] # 获取批次大小
m = x.size(1) - 1
# 噪声分布
Pn = 1 / float(self.n_data)
# 正样本对的损失
P_pos = x.select(1, 0)
log_D1 = torch.div(P_pos, P_pos.add(m * Pn + eps)).log_()
# K个负样本对的损失
P_neg = x.narrow(1, 1, m)
log_D0 = torch.div(P_neg.clone().fill_(m * Pn), P_neg.add(m * Pn + eps)).log_()
loss = - (log_D1.sum(0) + log_D0.view(-1, 1).sum(0)) / bsz
return loss
class CRDLoss(nn.Module):
"""CRD损失函数
包括两个对称部分:
(a) 以教师为锚点,在学生端选择正负样本
(b) 以学生为锚点,在教师端选择正负样本
Args:
opt.s_dim: 学生特征的维度
opt.t_dim: 教师特征的维度
opt.feat_dim: 投影空间的维度
opt.nce_k: 每个正样本配对的负样本数量
opt.nce_t: 温度
opt.nce_m: 更新内存缓冲区的动量
opt.n_data: 训练集中的样本数量,因此内存缓冲区是: opt.n_data x opt.feat_dim
"""
def __init__(self, opt):
super(CRDLoss, self).__init__() # 初始化函数
self.embed_s = Embed(opt.s_dim, opt.feat_dim) # 学生网络的嵌入层
self.embed_t = Embed(opt.t_dim, opt.feat_dim) # 教师网络的嵌入层
self.contrast = ContrastMemory(opt.feat_dim, opt.n_data, opt.nce_k, opt.nce_t, opt.nce_m) # 对比内存
self.criterion_t = ContrastLoss(opt.n_data) # 教师损失函数
self.criterion_s = ContrastLoss(opt.n_data) # 学生损失函数
def forward(self, f_s, f_t, idx, contrast_idx=None):
"""
Args:
f_s: 学生网络的特征,大小为[batch_size, s_dim]
f_t: 教师网络的特征,大小为[batch_size, t_dim]
idx: 数据集中这些正样本的索引,大小为[batch_size]
contrast_idx: 负样本的索引,大小为[batch_size, nce_k]
Returns:
对比损失
"""
f_s = self.embed_s(f_s) # 学生特征进行嵌入
f_t = self.embed_t(f_t) # 教师特征进行嵌入
out_s, out_t = self.contrast(f_s, f_t, idx, contrast_idx) # 对比学生和教师特征
s_loss = self.criterion_s(out_s) # 计算学生损失
t_loss = self.criterion_t(out_t) # 计算教师损失
loss = s_loss + t_loss # 总损失
return loss构造CRD,CRD是Logits蒸馏。

在每一轮的训练当中,还需要添加对比索引。

(DKD) - Decoupled Knowledge Distillation
DKD是Logits蒸馏,从新的角度让KD重回SOTA。
论文链接: Decoupled Knowledge Distillation | Papers With Code
B站讲解链接: 解耦知识蒸馏【CVPR2022】【知识蒸馏】_哔哩哔哩_bilibili
现有的蒸馏方法主要是基于从中间层提取深层特征,而忽略了Logit蒸馏的重要性。为了给logit蒸馏研究提供一个新的视角,我们将经典的KD损失重新表述为两部分,即目标类知识蒸馏(TCKD)和非目标类知识蒸馏(NCKD)。
图(a)是传统的logits蒸馏,图(b)是解耦知识蒸馏。

损失函数有两部分组成:

算法流程:

DKD实证研究并证明了两部分的效果:TCKD转移了关于训练样本“难度”的知识,而NCKD是logit蒸馏有效的突出原因。更重要的是,我们揭示了经典KD损失是一个耦合公式,它(1)抑制了NCKD的有效性,(2)限制了平衡这两个部分的灵活性。为了解决这些问题,我们提出了解耦知识蒸馏(DKD),使TCKD和NCKD更有效和灵活地发挥其作用。
具体实现类,
import torch
import torch.nn as nn
import torch.nn.functional as F
# 获取ground truth mask
def _get_gt_mask(logits, target):
target = target.reshape(-1)
mask = torch.zeros_like(logits).scatter_(1, target.unsqueeze(1), 1).bool()
return mask
# 获取非ground truth mask
def _get_other_mask(logits, target):
target = target.reshape(-1)
mask = torch.ones_like(logits).scatter_(1, target.unsqueeze(1), 0).bool()
return mask
# 拼接mask
def cat_mask(t, mask1, mask2):
t1 = (t * mask1).sum(dim=1, keepdims=True)
t2 = (t * mask2).sum(1, keepdims=True)
rt = torch.cat([t1, t2], dim=1)
return rt
# 定义DKDloss类
class DKDloss(nn.Module):
def __init__(self):
super(DKDloss, self).__init__()
# 前向传播
def forward(self, logits_student, logits_teacher, target, alpha, beta, temperature):
# 获取ground truth mask和非ground truth mask
gt_mask = _get_gt_mask(logits_student, target)
other_mask = _get_other_mask(logits_student, target)
# 对学生和教师logits进行softmax
pred_student = F.softmax(logits_student / temperature, dim=1)
pred_teacher = F.softmax(logits_teacher / temperature, dim=1)
# 拼接mask
pred_student = cat_mask(pred_student, gt_mask, other_mask)
pred_teacher = cat_mask(pred_teacher, gt_mask, other_mask)
# 计算tckd_loss
log_pred_student = torch.log(pred_student)
tckd_loss = (
F.kl_div(log_pred_student, pred_teacher, reduction='sum')
* (temperature**2) / target.shape[0]
)
# 计算nckd_loss
pred_teacher_part2 = F.softmax(
logits_teacher / temperature - 1000.0 * gt_mask, dim=1
)
log_pred_student_part2 = F.log_softmax(
logits_student / temperature - 1000.0 * gt_mask, dim=1
)
nckd_loss = (
F.kl_div(log_pred_student_part2, pred_teacher_part2, reduction='sum')
* (temperature**2) / target.shape[0]
)
# 计算总的loss
loss = alpha * tckd_loss + beta * nckd_loss
return loss(不需要老师的KD) - Deep Mutual Learning
本文提出了小网络之间也可以相互学习。如下图所示,很简单,损失函数就是你给我一个KL散度,我给你一个KL散度。通过这样的训练范式,你和我都能够得到提升。

代码链接: GitHub - YingZhangDUT/Deep-Mutual-Learning: TensorFlow Implementation of Deep Mutual Learning
(CTKD) - Curriculum Temperature for Knowledge Distillation
这篇论文在传统Lotits的基础上对温度T进行了改良,不需要固定的温度,而是在训练的时候网络自动学习温度(动态温度)。
论文链接: https://arxiv.org/abs/2211.16231

CTKD 方法可以简单分为左右两个部分:一个是对抗温度学习,一个是课程难度训练学习。
对于对抗温度学习,CTKD提出了两种方案,一种是全局温度,一种是实例温度。

对于全局温度的代码实现,一句话:
self.global_T = nn.Parameter(torch.ones(1), requires_grad=True)对于实例的温度是对每一个实例产生一个温度。例如batch_size是64,就产生64个温度。
对于课程学习,设置了Cos逐渐增加学习难度。

总结,CTKD 总共包含两个模块,梯度反向层 GRL 和温度预测模块,CTKD 方法可以作为即插即用的插件应用在现有的 SOTA 的蒸馏方法中,取得广泛的提升。

(SimKD) - Knowledge Distillation with the Reused Teacher Classifier
创新点2个:
1. 学生直接使用(复用)教师分类器,不需要重新训练学生分类器。
2. 学生的特征经过投影(Projector)后再送入教师分类器进行分类。
论文链接: Knowledge Distillation with the Reused Teacher Classifier | Papers With Code

投影器,SimKD使用了三种消融,在ResNet32x4教师和ResNet8x4学生进行实验。

SimKD是特征蒸馏。构造SimKD需要传入学生和教师的通道维度c。[b,c,h,w]这个c.
损失函数是MSELoss(),将SimKD添加到模型列表,添加到可训练列表。

cls_t教师分类器的获取,这里调用的是get_feat_modules()方法。
cls_t = model_t.module.get_feat_modules()[-1] if opt.multiprocessing_distributed else model_t.get_feat_modules()[-1]所以在get_feat_modules()方法一定要加上分类器层。(以Resnet为例)。

SimKD实现类,学生特征(例如,[64,256,8,8])传入与教师特征在空间维度对齐,然后通过Projector这里是setattr()来将通道对齐,通道是[b,c,h,w]中的c。最后,池化送入教师分类器分类。
class SimKD(nn.Module):
"""CVPR-2022: Knowledge Distillation with the Reused Teacher Classifier"""
def __init__(self, *, s_n, t_n, factor=2):
super(SimKD, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d((1,1))
def conv1x1(in_channels, out_channels, stride=1):
return nn.Conv2d(in_channels, out_channels, kernel_size=1, padding=0, stride=stride, bias=False)
def conv3x3(in_channels, out_channels, stride=1, groups=1):
return nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, stride=stride, bias=False, groups=groups)
# 一个瓶颈设计以减少额外参数
setattr(self, 'transfer', nn.Sequential(
conv1x1(s_n, t_n//factor),
nn.BatchNorm2d(t_n//factor),
nn.ReLU(inplace=True),
conv3x3(t_n//factor, t_n//factor),
# 深度可分离卷积
#conv3x3(t_n//factor, t_n//factor, groups=t_n//factor),
nn.BatchNorm2d(t_n//factor),
nn.ReLU(inplace=True),
conv1x1(t_n//factor, t_n),
nn.BatchNorm2d(t_n),
nn.ReLU(inplace=True),
))
def forward(self, feat_s, feat_t, cls_t):
# 空间维度对齐
s_H, t_H = feat_s.shape[2], feat_t.shape[2]
if s_H > t_H:
source = F.adaptive_avg_pool2d(feat_s, (t_H, t_H))
target = feat_t
else:
source = feat_s
target = F.adaptive_avg_pool2d(feat_t, (s_H, s_H))
trans_feat_t=target
# 通道对齐
trans_feat_s = getattr(self, 'transfer')(source)
# 通过教师分类器进行预测
temp_feat = self.avg_pool(trans_feat_s)
temp_feat = temp_feat.view(temp_feat.size(0), -1)
pred_feat_s = cls_t(temp_feat)
return trans_feat_s, trans_feat_t, pred_feat_s(MGD) - Masked Generative Distillation
MGD先随机生成Masked,然后通过2个3x3的卷积来生成特征,最后与教师的特征进行损失计算。
论文链接: csdn - 安全中心

实现类,
class MGDLoss(nn.Module):
def __init__(self, student_channels, teacher_channels, name, alpha_mgd=0.00007, lambda_mgd=0.5, ):
super(MGDLoss, self).__init__()
self.alpha_mgd = alpha_mgd
self.lambda_mgd = lambda_mgd
if student_channels != teacher_channels:
self.align = nn.Conv2d(student_channels, teacher_channels, kernel_size=1, stride=1, padding=0)
else:
self.align = None
self.generation = nn.Sequential(
nn.Conv2d(teacher_channels, teacher_channels , kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(teacher_channels , teacher_channels, kernel_size=3, padding=1))
# self.se = se_block(student_channels)
def forward(self, preds_S, preds_T):
"""Forward function.
Args:
preds_S(Tensor): Bs*C*H*W, student's feature map
preds_T(Tensor): Bs*C*H*W, teacher's feature map
"""
assert preds_S.shape[-2:] == preds_T.shape[-2:]
if self.align is not None:
preds_S = self.align(preds_S)
loss = self.get_dis_loss(preds_S, preds_T) * self.alpha_mgd
return loss
def get_dis_loss(self, preds_S, preds_T):
loss_mse = nn.MSELoss(reduction='sum')
N, C, H, W = preds_T.shape
device = preds_S.device
mat = torch.rand((N,C,1,1)).to(device) # 随机生成
# mat = self.se(preds_S).to(device) #[N,C,1,1]
# mat = torch.rand((N,1,H,W)).to(device)
mat = torch.where(mat < self.lambda_mgd, 0, 1).to(device)
masked_fea = torch.mul(preds_S, mat)
new_fea = self.generation(masked_fea)
dis_loss = loss_mse(new_fea, preds_T) / N
return dis_loss思考:如果不使用随机生成,使用SE注意力会有什么效果?
答:本人做了实验,效果会比随机生成稍稍好一点。
思考:这里使用了2个3x3的设计,中间加一个瓶颈会怎样?
.....自行实验。
(ReviewKD) - Distilling Knowledge via Knowledge Review
创新点1:首次提出跨阶段连接路径来形成知识回顾,融合多阶段的知识。ABF
创新点2:将金字塔池化引入到了知识蒸馏当中。HCL
论文链接: Distilling Knowledge via Knowledge Review | Papers With Code

ReviewKD的两大模块,如下图所示,左图是特征注意力融合模块ABF,右图是特征金字塔池化HCL。

ABF实现,
class ABF(nn.Module):
def __init__(self, in_channel, mid_channel, out_channel, fuse):
super(ABF, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channel, mid_channel, kernel_size=1, bias=False),
nn.BatchNorm2d(mid_channel),
)
self.conv2 = nn.Sequential(
nn.Conv2d(mid_channel, out_channel,kernel_size=3,stride=1,padding=1,bias=False),
nn.BatchNorm2d(out_channel),
)
if fuse:
self.att_conv = nn.Sequential(
nn.Conv2d(mid_channel*2, 2, kernel_size=1),
nn.Sigmoid(),
)
else:
self.att_conv = None
nn.init.kaiming_uniform_(self.conv1[0].weight, a=1) # pyre-ignore
nn.init.kaiming_uniform_(self.conv2[0].weight, a=1) # pyre-ignore
def forward(self, x, y=None, shape=None, out_shape=None):
n,_,h,w = x.shape
# transform student features
x = self.conv1(x)
if self.att_conv is not None:
# upsample residual features
y = F.interpolate(y, (shape,shape), mode="nearest")
# fusion
z = torch.cat([x, y], dim=1)
z = self.att_conv(z)
x = (x * z[:,0].view(n,1,h,w) + y * z[:,1].view(n,1,h,w))
# output
if x.shape[-1] != out_shape:
x = F.interpolate(x, (out_shape, out_shape), mode="nearest")
y = self.conv2(x)
return y, x
HCL实现,
def hcl(fstudent, fteacher):
# 两个都是list,存各个stage对象
loss_all = 0.0
for fs, ft in zip(fstudent, fteacher):
n,c,h,w = fs.shape
loss = F.mse_loss(fs, ft, reduction='mean')
cnt = 1.0
tot = 1.0
for l in [4,2,1]:
if l >=h:
continue
tmpfs = F.adaptive_avg_pool2d(fs, (l,l))
tmpft = F.adaptive_avg_pool2d(ft, (l,l))
cnt /= 2.0
loss += F.mse_loss(tmpfs, tmpft, reduction='mean') * cnt
tot += cnt
loss = loss / tot
loss_all = loss_all + loss
return loss_all
reviewKD实现,
class ReviewKD(nn.Module):
def __init__(
self, student, in_channels, out_channels, shapes, out_shapes,
):
super(ReviewKD, self).__init__()
self.student = student
self.shapes = shapes
self.out_shapes = shapes if out_shapes is None else out_shapes
abfs = nn.ModuleList()
mid_channel = min(512, in_channels[-1])
for idx, in_channel in enumerate(in_channels):
abfs.append(ABF(in_channel, mid_channel, out_channels[idx], idx < len(in_channels)-1))
self.abfs = abfs[::-1]
self.to('cuda')
def forward(self, x):
student_features = self.student(x,is_feat=True)
logit = student_features[1]
x = student_features[0][::-1]
results = []
out_features, res_features = self.abfs[0](x[0], out_shape=self.out_shapes[0])
results.append(out_features)
for features, abf, shape, out_shape in zip(x[1:], self.abfs[1:], self.shapes[1:], self.out_shapes[1:]):
out_features, res_features = abf(features, res_features, shape, out_shape)
results.insert(0, out_features)
return results, logit
(PEFD) - Improved Feature Distillation via Projector Ensemble
创新点:Logits投影 + 集成。
PEFD是Logits蒸馏,初始化3个线性回归器,学生网络的Logits输出经过3线性投影,然后取平均。最后与教师的Logits进行余弦损失计算。
论文链接:https://papers.nips.cc/paper_files/paper/2022/file/4ec0b6648bdf487a2f1c815924339022-Paper-Conference.pdf
源码链接:https://github.com/chenyd7/PEFD

创建3个线性回归器regress_s1、regress_s2、regress_s3,添加到模型列表,可训练列表。

线性回归代码,

具体实现,在每一轮的训练中,如下代码所示。
f_t = feat_t[-1]
relu = torch.nn.ReLU()
# linear Regress
f_s1 = feat_s[-1]
f_s1 = module_list[1](f_s1)
f_s1 = relu(f_s1)
f_s2 = feat_s[-1]
f_s2 = module_list[2](f_s2)
f_s2 = relu(f_s2)
f_s3 = feat_s[-1]
f_s3 = module_list[3](f_s3)
f_s3 = relu(f_s3)
f_s = (f_s1 + f_s2 + f_s3) / 3
bsz = f_s.shape[0]
bdm = f_s.shape[1]
# inner product (normalize first and inner product)
normft = f_t.pow(2).sum(1, keepdim=True).pow(1. / 2)
outft = f_t.div(normft)
normfs = f_s.pow(2).sum(1, keepdim=True).pow(1. / 2)
outfs = f_s.div(normfs)
cos_theta = (outft * outfs).sum(1, keepdim=True)
G_diff = 1 - cos_theta
loss_kd = (G_diff).sum() / bsz PEFD论文详细解读: PEFD-多投影蒸馏详细论文与代码解读(Improved Feature Distillation via Projector Ensemble)-CSDN博客
(KD++) - Improving Knowledge Distillation via Regularizing Feature Norm and Direction
KD++提出使用教师特征的类均值(等效为分类器)对齐学生特征,同时提出ND-loss:
1)鼓励学生输出large-norm特征;
2)对齐老师与学生class-mean。
论文链接: https://arxiv.org/pdf/2305.17007v1
如下图所示,ND-loss可作用于不同的知识蒸馏中。如左图中logits蒸馏(通过约束logits或者softmax的输出分数,KD/DKD);右图中,特征蒸馏,约束特征输出/ReviewKD。本文则将其应用于embedding feature(中后层特征输出)的蒸馏中。

1. 特征Norm正则化
通过最小化特征的L2距离,使小模型学习到老师模型的larger-norm特性;同时在训练过程中我们逐渐增加特征的Norm,即Stepwise increasing feature norms (SIFN)。
2.特征Direction正则化
计算特征与class-mean的Cosine similarity;并借鉴InfoNCE,我们提出的Direction Loss也考虑了类间样本及其class-mean。
NDLoss,
fs与ft分别表示样本x(gt=y, class-mean=c)的student与teacher的特征输出
fs在c方向上的映射表示为:ps=fs*cos(fs, c)
e为c对应的单位向量;pt为ft在c上面的映射
各变量的物理意义见下图。

ND-Loss旨在最小化pt与ps之间的距离,定义为6式:
1)增加fs的norm;
2)减少fs与c之间的角度距离。在所有训练样本上,ND-loss进一步表示为8式。


具体实现类如下所示。
class DirectNormLoss(nn.Module):
def __init__(self, num_class=1000, nd_loss_factor=1.0):
super(DirectNormLoss, self).__init__()
self.num_class = num_class
self.nd_loss_factor = nd_loss_factor
# s_emd:student feature; t_emb: teacher feature
# T_EMB: teacher class-means
def project_center(self, s_emb, t_emb, T_EMB, labels):
assert s_emb.size() == t_emb.size()
assert s_emb.shape[0] == len(labels)
loss = 0.0
for s, t, i in zip(s_emb, t_emb, labels):
i = i.item()
center = torch.tensor(T_EMB[str(i)]).cuda()
e_c = center / center.norm(p=2)
max_norm = max(s.norm(p=2), t.norm(p=2))
loss += 1 - torch.dot(s, e_c) / max_norm
return loss
def forward(self, s_emb, t_emb, T_EMB, labels):
nd_loss = self.project_center(s_emb=s_emb, t_emb=t_emb, T_EMB=T_EMB, labels=labels) * self.nd_loss_factor
return nd_loss / len(labels)
在KD、DIST、DKD、ReviewKD上都能提升

(多出口网络 + 集成学习的KD)
《多阶段特征融合知识蒸馏》
这篇论文我有PDF和代码,如果需要可以联系我。

《Teacher-student collaborative knowledge distillation for image classification》

(SDD) - Scale Decoupled Distillation
论文链接:https://arxiv.org/pdf/2403.13512.pdf
代码: GitHub - shicaiwei123/SDD-CVPR2024: Official code for Scale Decoupled Distillation
以前的知识蒸馏方法都局限于在利用最后的全局的 logit output,但是我们发现全局的logit output或许不是一个很好的教师知识的“载体”。因为实际场景中不同类的图像信息并不是完全的独立关系而是相互包含的。
-
首先类别本身定义的时候就是属于相似的类,比如橘猫和蓝白猫,二者都属于猫的大类,有着相似的形态。
-
其次同张图像也不一定就只包含了目标类信息,比如一张猫的图像里面可能还会有狗存在。
像是这些情况,不同类的语义信息是混合或相似的,最后的全局的logit output的knowledge通常也会是混合,会导致teacher和student的误判。也就是纯利用这种模糊的全局的logit output的话,teacher自己都可能都没法分清楚,又怎么能教会student呢?具体的一个例子如下图所示:

我们可视化了ImageNet中class 6 (stingray) 的所有的测试样本 在预训练的ResNet34在的预测结果。如左图所示,绝大部分是正确的,但是会有一些错误的结果。错误最多的是class 5,它对应的numbfish,和stingray都属于fish,右边的图也可以看出,二者外形是非常相似的。其次还有类似于一些右图第二列的错误样本,因为包含了潜水员,被错误分类成了第983类的scuba diver。
这些现象引导我们思考一个,如何在logit distillation中让学生获取更加 accurate 而不是ambiguous的知识。不仅仅是teacher能够准确分类的样本,即使是teacher不能准确分类的样本,student 能否也能获得一些有益的信息。于是,我们提出了我们的Scaled Decoupled Distillation。
------
首先是方法的框图。总的来说就是在spatial-level做了logit knowledge知识的解耦,然后将解耦的知识分为一致和互补两类,控制他们的权重来引导student学习。值得一提的是,SDD和已有的logit distillation方法是独立的,可以和它们都结合起来,并且带来效果的提升。接下来我将更详细的介绍idea的思考过程。

接下来,我将逐一分析Scaled Decoupled Distillation的设计思路。
传统的logit distillation中,logit output的知识是混合模糊的原因就是,在最后来自于图像不同的region的信息被 avgpooling 聚合到了一起。就是将最后BXCXHXW的 feature map,转变成 BXC的feature vector,对应于不同输入区域的空间特征就被混合了。那么为什么需要这一步呢?我把H*W个BXC 取出来单独分类不行吗?在分类任务中,确实不行,因为我分类器必须要得出一个结果出来,都分类了,我最后要把图像标成那个结果呢?
但是,我们现在是在做蒸馏哦!!!,蒸馏的teacher的指导可以是多个的,只要student也有对应的接受相应知识的接口就可以,也就是在指导学生的时候,我可以不用全局的logit output而是用这些局部区域对应的特征计算得到的logit output。局部信息通常会包含更多细节,同时几乎不会在一个局部区域耦合多个类别的信息,所以通过获取多个local region的logit output来进行知识蒸馏,就可以unambiguous的信息传递给student。所以,很自然的Scale Decoupling的思想就出来了。
具体实现的时候,借鉴空间池化的思想,我们的解耦是在feature map上进行的,相比于直接在输入空间进行解耦,可以避免多次前向传播的计算量。解耦后我们将多个特征向量在batch维度级联起来得到 B*H*WXC个长度为C的特征向量,同时输入到全连接层中,避免利用for循环来求多个特征的响应,通过GPU的加速,整个SDD几乎不会引入额外的计算开销。
因为分类器是固定的,分类器权重W的每一列其实就代表了对应类的类中心,在分类的时候,每个样本的特征向量和所有类中心求一个相似度,相似度最高的类中心对应的类就是这个样本分类结果。现在将logit output在spatial-level做了解耦之后,即使是teacher利用全局 logit output预测错误的样本,student也能从local region中得到正确的特征向量,而这个特征向量在分类器中就能和正确的类中心对应上,从而正确分类,并且将对应的logit konwledge传递给学生。因此,可以从教师分类错误的样本中学习到知识。
进一步的,除了H*W个BXC,我们还可以考虑多尺度的情况,不同区域尺度的可能又会包含不同的信息,所以引入了尺度控制参数M来控制蒸馏中的考虑的尺度情况。
最后,除了更加准确的local logit knowledge之外,我们还可以从另一个角度来看global和local的预测。根据类别进一步将解耦的logit输出划分为一致和互补的项。首先global和local的预测是一致的情况,local knowledge可以看做是global knowledge的多尺度补充。预测不一致的时候,一方面global是错的,local是对的,可以传递正确的知识,另一方面,global是对的,local是错的,说明这个样本有模糊性,错误的预测传递给student,保留样本模糊性,避免student对这类样本的过拟合。
具体实现类,以DKD为例。
class SDD_DKD(Distiller):
"""Decoupled Knowledge Distillation(CVPR 2022)"""
def __init__(self, student, teacher, cfg):
super(SDD_DKD, self).__init__(student, teacher)
self.ce_loss_weight = cfg.DKD.CE_WEIGHT
self.alpha = cfg.DKD.ALPHA
self.beta = cfg.DKD.BETA
self.temperature = cfg.DKD.T
self.warmup = cfg.warmup
self.M=cfg.M
def forward_train(self, image, target, **kwargs):
logits_student, patch_s = self.student(image)
with torch.no_grad():
logits_teacher, patch_t = self.teacher(image)
# losses
# print(self.warmup)
loss_ce = self.ce_loss_weight * F.cross_entropy(logits_student, target)
if self.M=='[1]':
loss_dkd = min(kwargs["epoch"] / self.warmup, 1.0) * dkd_loss_origin(
logits_student,
logits_teacher,
target,
self.alpha,
self.beta,
self.temperature,
)
else:
loss_dkd = min(kwargs["epoch"] / self.warmup, 1.0) * multi_dkd(
patch_s,
patch_t,
target,
self.alpha,
self.beta,
self.temperature,
)
losses_dict = {
"loss_ce": loss_ce,
"loss_kd": loss_dkd,
}
return logits_student, losses_dict
(Logits标准化KD) - Logit Standardization in Knowledge Distillation
传统知识蒸馏默认学生/教师网络的温度是全局一致的,这种设置迫使学生模仿教师的 logit 的具体值,而非其关系,论文方法提出 Logit 标准化,解决了这个问题。
论文链接: https://arxiv.org/pdf/2403.01427v1
下图右边,通过Z()得分函数来标准化。

先看算法流程,

具体实现,首先是Z-score函数,也就是算法1.
def normalize(logit):
mean = logit.mean(dim=-1, keepdims=True)
stdv = logit.std(dim=-1, keepdims=True)
return (logit - mean) / (1e-7 + stdv)算法2. 以KD为例。
def kd_loss(logits_student_in, logits_teacher_in, temperature, logit_stand):
logits_student = normalize(logits_student_in) if logit_stand else logits_student_in
logits_teacher = normalize(logits_teacher_in) if logit_stand else logits_teacher_in
log_pred_student = F.log_softmax(logits_student / temperature, dim=1)
pred_teacher = F.softmax(logits_teacher / temperature, dim=1)
loss_kd = F.kl_div(log_pred_student, pred_teacher, reduction="none").sum(1).mean()
loss_kd *= temperature**2
return loss_kd结束语:你没有落后,也没有领先,在命运为你安排的时区里,一切都准时。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐


 133
133 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)