3090单卡+yoloV8+训练手势识别(手把手教学)
超详细记录3090单卡利用yolov8训练手势识别
利用yoloV8训练自己的数据集(手势识别数据):
github:官方项目链接
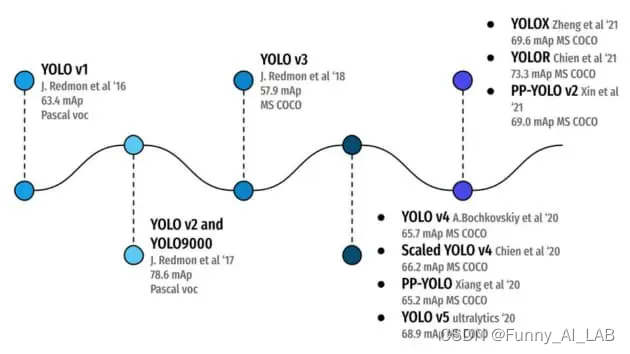
yolo相关发展史介绍:

YOLO(You Only Look Once)是一种流行的对象检测和图像分割模型,由华盛顿大学的 Joseph Redmon 和 Ali Farhadi 开发。
- YOLO 于2015 年推出,以其高速度和准确性迅速受到欢迎。
- YOLOv2于 2016 年发布,通过结合批量归一化、锚框和维度集群改进了原始模型。
- YOLOv3于 2018 年推出,使用更高效的主干网络、多个锚点和空间金字塔池进一步增强了模型的性能。
- YOLOv4于 2020年发布,引入了马赛克数据增强、新的无锚检测头和新的损失函数等创新。
- YOLOv5进一步提升了模型的性能,并增加了超参数优化、集成实验跟踪和自动导出为流行的导出格式等新功能。
- YOLOv6于 2022年由美团开源,并在该公司的许多自主送货机器人中使用。
- YOLOv7添加了额外的任务,例如对 COCO 关键点数据集的姿势估计。
- YOLOv8是Ultralytics 最新版本的 YOLO。作为尖端的、最先进的 (SOTA) 模型,YOLOv8 建立在先前版本成功的基础上,引入了新功能和改进以增强性能、灵活性和效率。YOLOv8 支持全方位的视觉 AI 任务,包括检测、分割、姿态估计、跟踪和分类。这种多功能性允许用户在不同的应用程序和领域中利用 YOLOv8 的功能。
yolov8的详细介绍:YOLOv8 深度详解!一文看懂
--------------------------------分界线----------------------------------
下面是具体实验记录:
1.数据集准备
手势识别数据集:具体介绍
该数据集包含用于对象检测的 5 个手势类的 839 张图像:1,2,3,4,5. 在五个手指的帮助下,形成一个到五个数字的组合,并在这些带有相应标签的手势上训练对象检测模型,如图 5所示。数据集分为训练集、验证集和测试集。该数据集包含 587 个训练图像、167 个验证图像和 85 个测试图像。每个图像都有一个416× 416只有一个对象(或实例)的分辨率。

各个类别数据分布如下: 数据文件夹结构:
数据文件夹结构:

数据集格式为yolo_txt格式,即将每个xml标注提取bbox信息为txt格式,每个图像对应一个txt文件,文件每一行为一个目标的信息,包括class, x_center, y_center, width, height格式。格式如下:

2.环境准备
基础环境rtx3090显卡,yolov8要求的基本环境如下:

创建虚拟环境并激活:
conda create -n xx python=3.8
conda activate xx
拉取yolo的git项目
git clone https://github.com/autogyro/yolo-V8.git
cd yolo-V8
pip install -r requirements.txt
pip install ultralytics
3.测试环境
官网下载相应的权重

利用下面的测试指令进行测试:
yolo task=detect mode=predict model=yolov8n.pt conf=0.25 source='https://media.roboflow.com/notebooks/examples/dog.jpeg'


4.训练自己的数据
创建自己数据集的yaml文件
 在yolo-V8目录下运行以下代码(单卡训练)
在yolo-V8目录下运行以下代码(单卡训练)
yolo task=detect mode=train model=yolov8n.pt data=ultral
ytics/yolo/data/datasets/hand.yaml batch=32 epochs=100 imgsz=640 lr0=0.01

训练过程可视化:
在训练过程的可视化tensorboard tensorboard --logdir ./ 然后打开localhost:6006即可,效果如下:

训练完可以去result文件夹查看相应的结果:

如何多卡训练,只需添加gpu(device=0,1)即可:
yolo task=detect mode=train model=yolov8n.pt data=ultral
ytics/yolo/data/datasets/hand.yaml batch=32 epochs=100 imgsz=640 lr0=0.01 device=0,1
5.模型测试

训练完会在train2的目录下生成相应的.pt文件:

测试图片指令:
yolo task=detect mode=val split=test model=runs/detect/train2/weights/best.pt data=hand.yaml

ceshi
测试视频指令:
自己录制一个video进行测试
yolo task=detect mode=predict source=video.mp4 model=runs/detect/train2/weights/best.pt
测试效果还是不错的!

参考:
1.使用YOLOv8训练自己的目标检测数据集
2.YOLOV8进行疲劳驾驶检测
3.在自定义数据上训练 YOLOv8?
4.YOLOv8训练自定义数据集(超详细)

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐


 0
0 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)