【人工智能】习题——启发式搜索
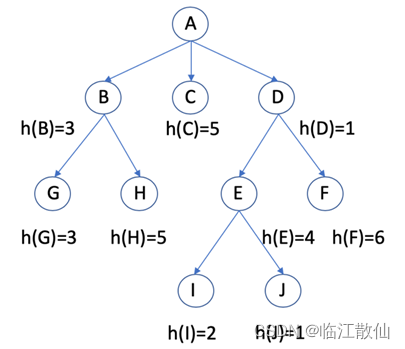
又因为open表上任一具有f(n)<f*(S)的节点n,最终都会被A*选做扩展的节点,放入close表中,所以在open表中剩下的节点都有f(n)>f*(S)。引理1:对无限图,若有初始节点S到目标节点T的路径,则A*不结束时,在open表中即使最小的一个值也将增到无限大,或有f(n)>f*(S)试给出爬山法和分支界限搜索算法搜索图1所示的从A到J的搜索路径,其中g(n)用节点深度表示,h(n)的
-
什么是图搜索过程?其中,重排Open表意味着什么?重排的原则是什么?
图搜索策略是一种在图中寻找解路径的方法。
重排open表指的是当open表不为空时,新插入结点后需重新调整open表的顺序,以确保open表中的结点按一定的优先级进行排序。
重排的原则取决于所用的搜索算法和数据结构。如深度优先搜索中,open表通常是栈,新节点被加到栈顶;广度优先搜索中,open表通常是队列,新节点被加到队尾;A*算法中,open表通常是优先队列,结点的优先级取决于它的估价函数,新节点需要通过排序放到合适的位置。
-
试给出爬山法和分支界限搜索算法搜索图1所示的从A到J的搜索路径,其中g(n)用节点深度表示,h(n)的值在图中显示。

爬山法:总是考虑与目标之间的差距,即g(n)=0,h(n),open表中的全部节点

搜索路径为ADEJ
分支界限搜索法:总是扩展具有最小耗散值的路径,即g(n),h(n)=0

搜索路径为ABCDGHEFIJ
-
怎么用一架天平3次称出13个硬币中唯一的然而未知轻重的假币(已知有标准的硬币)
将硬币分为4,4,5三组,编号为a1-a4,b1-b4,c1-c5。
第一次称量,a组与b组
-
相等
假币在c组
第二次称量,a1-a3与c1-c3
-
相等
假币在c4,c5中
第三次称量,a1与c4
-
相等
假币为c5
-
不等
假币为c4,且可得知假币的轻重
-
-
不等
假币在c1-c3中,且可得知假币的轻重,假设假币比真币重
第三次称量,c1与c2
-
相等
假币为c3
-
不等
重的那枚为假币
-
-
-
不等
设称量结果为a组比b组重(a1-a4>b1-b4),且a组在天平左边,b组在天平右边
第二次称量,(b1,c1-c3)(左)与(a1,b2-b4)(右)
-
相等
假币在a2-a4中,且假币比真币重
第三次测量,a2与a3
-
相等
假币为a4
-
不等
重的那枚为假币
-
-
不等
-
左>右
如果假币是b1或a1,则与第二次称量(a1-a4>b1-b4)的结果相矛盾
所以假币在b2-b4中,且假币比真币轻
第三次称量,b2与b3
-
相等
假币为b4
-
不等
轻的那枚为假币
-
-
左<右
假币在b1,a1之间
第三次称量,b1与c1
-
相等
假币为a1
-
不等
假币为b1,且可得知假币的轻重
-
-
-
-
-
给定4升和3升的水壶各一个。水壶上没有刻度。可以向水壶中加水。如何在4升的壶中准确的得到2升水?
初始状态为(0,0),目标状态为(2,x)。水壶的容量信息为{4,3,0}。
- 尝试4-2=2:无法用2求得2,此路径无解。
- 尝试3-1=2:
- 求1,4-3=1,从加满水的4升水壶中向空的3升水壶里加满,这样4升水壶里只剩下1升。
- 3-1=2,将3升水壶倒空,把4升水壶中剩的1升水倒入3升水壶中,3升水壶还剩2升空间。
- 目前有2,考虑4-2=2,将4升水壶加满,然后用4升水壶中的水将3升水壶加满,则4升水壶剩下2升水。找到目标状态。
-
对于A* 算法,证明下面的结论:
-
对于有限图,A* 算法一定会在有限步内终止;
- 若有解,即存在从初始节点到目标节点的路径,则在找到目标节点后A*算法终止。
- 若无解,由于有限图的节点数量是有限的,当open表中所有的节点都被扩展后,open表为空,满足终止条件,A*算法终止。
综上,对于有限图,A*算法一定会在有限步内终止。
-
对于无限图,只要从初始节点到目标节点有路径存在,则A* 算法也必然会终止;
引理1:对无限图,若有初始节点S到目标节点T的路径,则A*不结束时,在open表中即使最小的一个值也将增到无限大,或有f(n)>f*(S)
证明:设open表中的任一节点为n,S到n的最短路径为d(n), σ \sigma σ为边耗散值的最小值,则有
g ( n ) ≤ d ( n ) ⋅ σ (1) g(n)\leq d(n)\cdot \sigma \newline \tag{1} g(n)≤d(n)⋅σ(1)f ( n ) ≤ g ( n ) ≤ d ( n ) ⋅ σ (2) f(n)\leq g(n)\leq d(n)\cdot \sigma \tag{2} f(n)≤g(n)≤d(n)⋅σ(2)
对于无限表,当A*不结束时,open表中不断有节点加入,d(n)会趋于无穷大,又因为 σ \sigma σ>0,所以f(n)会趋于无穷大。又因为open表上任一具有f(n)<f*(S)的节点n,最终都会被A*选做扩展的节点,放入close表中,所以在open表中剩下的节点都有f(n)>f*(S)。
引理2:A*结束前,open表中必存在f(n) ≤ \leq ≤f*(S)
证明:A*结束前,open表中存在一个节点n,n在最佳路径上。
f ( n ) = g ( n ) + h ( n ) = g ∗ ( n ) + h ( n ) ≤ g ∗ ( n ) + h ∗ ( n ) = f ∗ ( n ) = f ∗ ( S ) (3) f(n)=g(n)+h(n)=g^*(n)+h(n)\newline \leq g^*(n)+h^*(n)=f^*(n)=f^*(S)\tag{3} f(n)=g(n)+h(n)=g∗(n)+h(n)≤g∗(n)+h∗(n)=f∗(n)=f∗(S)(3)
用反证法证明,假设A*不结束:由引理1,A*如果不结束,则open中所有n有f(n)>f*(S);
由引理2,在A*结束前,必存在节点n,使得f(n) ≤ \leq ≤f*(S)
产生矛盾,所以假设不成立。即对于无限图,只要从初始节点到目标节点有路径存在,则A* 算法也必然会终止。
-
若存在路径,则A* 算法一定会终止在最优路径上。
- 由定理可知,若存在路径,则A*算法一定终止。
- 设找到的路径S->T不是最佳的,则f(T)=g(T)>f*(S),由引理2知结束前open表中存在f(n) ≤ \leq ≤f*(S)的节点n,所以f(n) ≤ \leq ≤f*(S)<f(T),因此A*应该选择n扩展,而不是T。与假设A*选择T结束矛盾。所以找到的路径一定是最佳路径。
综上,若存在路径,则A* 算法一定会终止在最优路径上。
->T不是最佳的,则f(T)=g(T)>f*(S),由引理2知结束前open表中存在f(n) ≤ \leq ≤f*(S)的节点n,所以f(n) ≤ \leq ≤f*(S)<f(T),因此A*应该选择n扩展,而不是T。与假设A*选择T结束矛盾。所以找到的路径一定是最佳路径。综上,若存在路径,则A* 算法一定会终止在最优路径上。
-

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)