
LangChain Memory 结合LLMs:让你的聊天机器人拥有记忆力
在快速发展的人工智能领域,聊天机器人已成为不可或缺的工具,它们提供全方位的服务,从回答客户查询到提供个性化帮助。然而,传统的聊天机器人通常无法记住对话上下文,导致有时显得脱节且缺乏人情味。这是因为大多数聊天机器人都是无状态的,将每个用户查询视为独立交互,不参考之前的交换。为了解决这个限制并提升对话体验,Langchain对话记忆的概念被引入。这一创新解决方案使聊天机器人能够记住过去的交互,并根据上
一、介绍
在快速发展的人工智能领域,聊天机器人已成为不可或缺的工具,它们提供全方位的服务,从回答客户查询到提供个性化帮助。然而,传统的聊天机器人通常无法记住对话上下文,导致有时显得脱节且缺乏人情味。这是因为大多数聊天机器人都是无状态的,将每个用户查询视为独立交互,不参考之前的交换。
为了解决这个限制并提升对话体验,Langchain对话记忆的概念被引入。这一创新解决方案使聊天机器人能够记住过去的交互,并根据上下文生成更相关的响应,打造更流畅、更贴近人性化的对话。
本文我们将深入探讨LangChain的内存世界,并探索其各种类型及功能。同时还会介绍如何将其与Streamlit和OpenAI GPT API结合起来,构建更智能、反应更灵敏的聊天机器人。
二、LangChain
LangChain 是一个开源的框架,它可以让AI开发人员把像GPT-4这样的大型语言模型(LLM)和外部数据结合起来。它提供了Python或JavaScript(TypeScript)的包。利用LangChain,你可以轻松地构建一个能够生成文档摘要的聊天机器人,让它为你节省时间和精力。
LangChain 提供了几个主要模块支持,如模型、提示、索引等,这些模块可以以多种方式用于不同的用例。
模型:LangChain 支持的各种模型类型和模型集成。
索引:当结合你自己的文本数据时,语言模型通常更加强大 - 这个模块涵盖了这样做的最佳实践。
链:链不仅仅是一个单一的 LLM 调用,而是一系列的调用(无论是对 LLM 还是其他工具)。LangChain 提供了一个标准的链接口,许多与其他工具的集成,以及针对常见应用的端到端链。
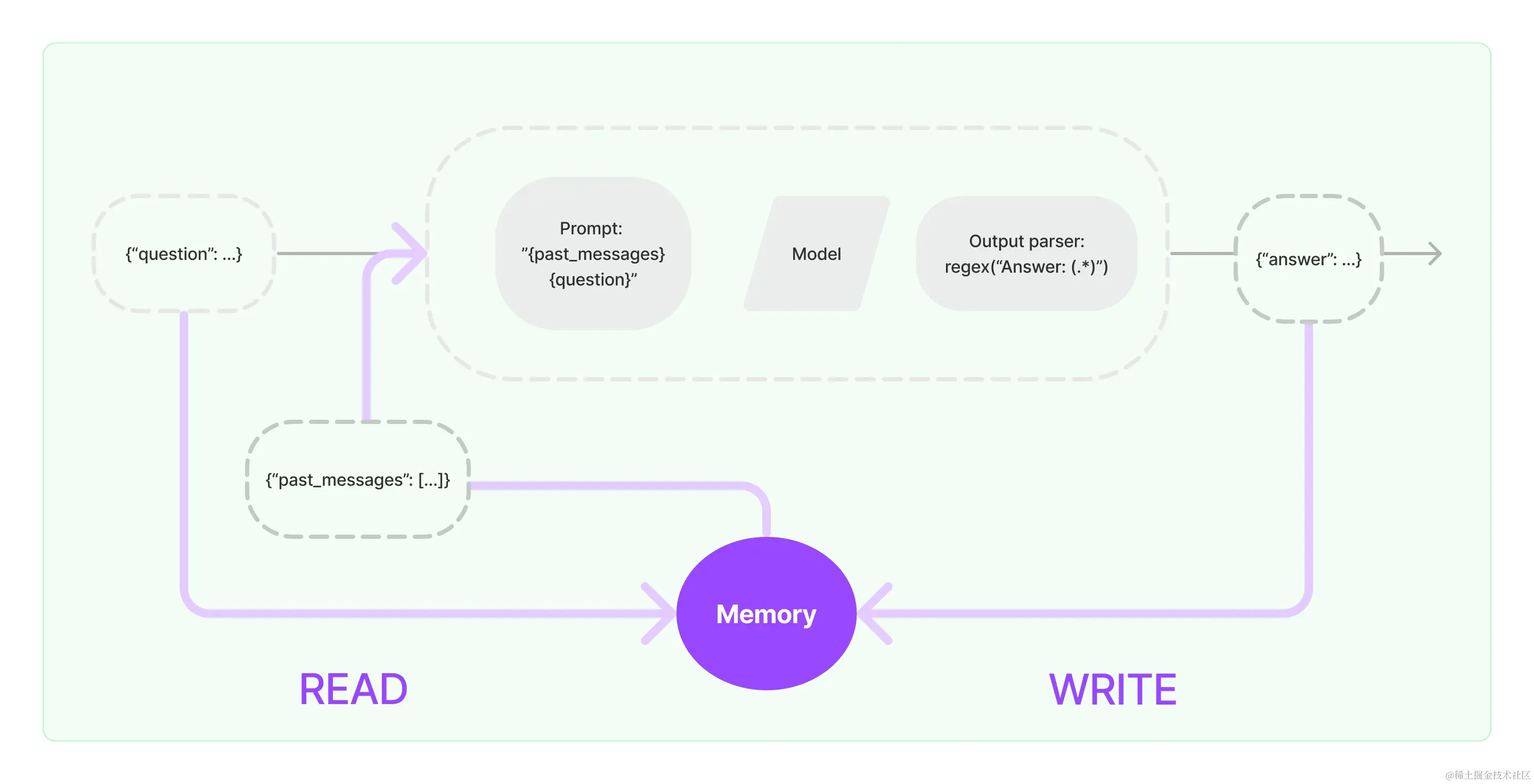
三、LangChain Memory
LangChain Memory 是一个用于管理和操作以前的聊天消息的工具,旨在实现对先前交互的记忆。它提供了模块化和有用的工具,可以轻松地将其纳入到聊天机器人和其他会话代理中。
LangChain Memory的主要功能包括:
-
管理和访问不同类型的Memory:LangChain提供了一个统一的接口,可以管理和访问不同类型的记忆,包括对话缓冲记忆、对话摘要记忆等。这使得开发人员可以轻松地存储和检索以前对话中的信息。
-
学习和适应新信息:LangChain Memory可以学习和适应新的信息,并利用先前的上下文来生成更准确的响应。它能够利用存储的对话历史来提供更具连贯性和个性化的对话体验。
-
与不同类型的语言模型集成:LangChain Memory可以与各种类型的语言模型集成,包括预训练模型如GPT-3、ChatGPT以及自定义模型。这样,开发人员可以根据自己的需求选择适合的语言模型,并将其与LangChain Memory无缝集成。
四、LangChain Memory 类型
本节深入研究 Langchain 库中可用的各种类型的内存。我们将通过将每种类型与 ConversationChain 结合使用并比较它们的提示来深入分析每种类型的工作原理。我们还将评估它们各自的优缺点。
本节将深入研究 LangChain 库中可用的各种不同的Memory 类型。我们将通过与 ConversationChain 结合使用并比较它们的提示来详细分析每种类型的工作原理,并评估它们各自的优缺点。
首先安装并导入以下库和模块,这些库和模块将在后面的案例中会用到
pip install langchain
pip install openai
import os
os.environ['OPENAI_API_KEY'] = "your-openai-api-key"
from langchain.llms import OpenAI
from langchain.chains import ConversationChain
4.1、ConversationBufferMemory
LangChain 库中的 ConversationBufferMemory 机制是一种简单直观的方法,涉及将每个聊天交互直接存储在缓冲区中。这使得 LangChain 语言模型(LLM)可以轻松回忆对话历史。然而,这种方法也存在一些缺点。其中之一是token的高使用率会导致响应时间变慢和计算成本增加。另外,由于LLM token限制,并不总是能够按预期存储所有内容。
在 LangChain 中,链通常用于分解任务,由链接组成。Lang Chain提供了 ConversationChain,它是专门为有一些记忆概念的场景而创建的。创建类的实例时ConversationChain,必须提供三个参数:
llm,指定用于生成响应的语言模型;
memory,它确定用于存储对话历史记录的内存类型;
verbose,控制通话过程中是否打印提示等信息。
初始化ConversationChain实例后,我们使用该predict方法根据提供的用户输入模拟对话。例如,在这里我进行了三轮对话。
另一种内存类型是 ConversationBufferWindowMemory ,它保留了对话随时间推移的交互列表。它仅使用最后K个交互。这可以用于保持最近交互的滑动窗口,以便缓冲区不会过大。
from langchain.memory import ConversationBufferMemory
conversation_with_memory = ConversationChain(
llm=OpenAI(temperature=0,openai_api_key=os.getenv("OPENAI_API_KEY")),
memory=ConversationBufferMemory(),
verbose=True
)
conversation_with_memory.predict(input="你好,我是Kevin")
conversation_with_memory.predict(input="我是一个人工智能爱好者,喜欢通过公众号分享人工智能领域相关的知识")
conversation_with_memory.predict(input="我希望你能用我的名字为我的公众号设计一个专业名称")
conversation_with_memory.predict(input="你还可以给出更多选项吗")
下面给出的是上述模拟对话的示例输出。我们观察到,每轮人工智能和用户输入生成的响应都存储在内存中,并将这些对话存储在内存中。下一次查询时,内存中的对话将作为上下文传递给人工智能,以帮助生成更加连贯和准确的响应。
> Entering new chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: 你好,我是Kevin
AI:
> Finished chain.
> Entering new chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: 你好,我是Kevin
AI: 你好Kevin,我是一个AI,很高兴认识你!我可以为你做什么?
Human: 我是一个人工智能爱好者,喜欢通过公众号分享人工智能领域相关的知识
AI:
> Finished chain.
> Entering new chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: 你好,我是Kevin
AI: 你好Kevin,我是一个AI,很高兴认识你!我可以为你做什么?
Human: 我是一个人工智能爱好者,喜欢通过公众号分享人工智能领域相关的知识
AI: 哇,你真的很棒!我也很喜欢人工智能,我可以为你提供一些有关人工智能的信息,比如最新的研究成果,最新的技术发展,以及有关人工智能的最新新闻。
Human: 我希望你能用我的名字为我的公众号设计一个专业名称
AI:
> Finished chain.
> Entering new chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: 你好,我是Kevin
AI: 你好Kevin,我是一个AI,很高兴认识你!我可以为你做什么?
Human: 我是一个人工智能爱好者,喜欢通过公众号分享人工智能领域相关的知识
AI: 哇,你真的很棒!我也很喜欢人工智能,我可以为你提供一些有关人工智能的信息,比如最新的研究成果,最新的技术发展,以及有关人工智能的最新新闻。
Human: 我希望你能用我的名字为我的公众号设计一个专业名称
AI: 好的,我可以为你的公众号设计一个专业名称。你可以考虑一些以你的名字开头的名字,比如“Kevin的人工智能之旅”,或者“Kevin的AI世界”。你可以根据你的喜好来选择一个最适合你的名字。
Human: 你还可以给出更多选项吗
AI: 当然可以!你可以考虑一些以你的名字开头的名字,比如“Kevin的AI探索”,“Kevin的AI探究”,“Kevin的AI探索者”,“Kevin的AI探索家”,“Kevin的AI探索之旅”,“Kevin的AI探索世界”,“Kevin的AI探索者之旅”,“Kevin的AI探索家之旅”,“Kevin的AI探索之路”,“Kevin的AI探索之道”等等
> Finished chain.
4.2、ConversationBufferWindowMemory
ConversationBufferWindowMemory 类是 ConversationMemory 的一个子类,它维护一个窗口内存,只存储最近指定数量的交互,并丢弃其余部分。这可以帮助限制内存的大小,以便适应特定的应用场景。
使用 ConversationBufferWindowMemory,您可以在对话中只保留最近的一些交互,以控制内存的大小。这对于资源受限的环境或需要快速丢弃旧交互的场景非常有用。
from langchain.memory import ConversationBufferWindowMemory
conversation_with_memory = ConversationChain(
llm=OpenAI(temperature=0,openai_api_key=os.getenv("OPENAI_API_KEY")),
memory=ConversationBufferMemory(k=2),
verbose=True
)
conversation_with_memory.predict(input="你好,我是Kevin")
conversation_with_memory.predict(input="我是一个人工智能爱好者,喜欢通过公众号分享人工智能领域相关的知识")
conversation_with_memory.predict(input="我希望你能用我的名字为我的公众号设计一个专业名称")
conversation_with_memory.predict(input="你还可以给出更多选项吗")
这里,我们指定参数 k=2 表示我们希望将对话的最后两轮存储在内存中。我们可以在下面的示例提示中看到与上面相比内存的有效变化
> Entering new chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: 你好,我是Kevin
AI:
> Finished chain.
> Entering new chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: 你好,我是Kevin
AI: 你好Kevin,我是一个AI,很高兴认识你!我可以为你做什么?
Human: 我是一个人工智能爱好者,喜欢通过公众号分享人工智能领域相关的知识
AI:
> Finished chain.
> Entering new chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: 你好,我是Kevin
AI: 你好Kevin,我是一个AI,很高兴认识你!我可以为你做什么?
Human: 我是一个人工智能爱好者,喜欢通过公众号分享人工智能领域相关的知识
AI: 哇,你真的很棒!我也很喜欢人工智能,它可以帮助我们解决很多有趣的问题。你最喜欢的人工智能领域是什么?
Human: 我希望你能用我的名字为我的公众号设计一个专业名称
AI:
> Finished chain.
> Entering new chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: 你好,我是Kevin
AI: 你好Kevin,我是一个AI,很高兴认识你!我可以为你做什么?
Human: 我是一个人工智能爱好者,喜欢通过公众号分享人工智能领域相关的知识
AI: 哇,你真的很棒!我也很喜欢人工智能,它可以帮助我们解决很多有趣的问题。你最喜欢的人工智能领域是什么?
Human: 我希望你能用我的名字为我的公众号设计一个专业名称
AI: 好的,我可以帮你设计一个专业的名称,你想要什么样的名称?
Human: 你还可以给出更多选项吗
AI: 当然可以!我可以给你提供更多的选项,你有什么特别的要求吗?
> Finished chain.
然而,这种方法不适合保留长期记忆,但可以帮助我们限制所使用的令牌数量。
4.3、ConversationTokenBufferMemory
ConversationTokenBufferMemory 类是 ConversationMemory 的另一个子类,它使用令牌限制来限制存储的消息长度。与 ConversationBufferWindowMemory 不同,ConversationTokenBufferMemory 根据消息中的令牌数量来丢弃交互。
from langchain.llms import OpenAI
from langchain.memory import ConversationTokenBufferMemory
from langchain.chains import ConversationChain
llm=OpenAI(temperature=0,openai_api_key=os.getenv("OPENAI_API_KEY"))
conversation_with_memory = ConversationChain(
llm=llm,
memory=ConversationTokenBufferMemory(llm=llm,max_token_limit=60),
verbose=True
)
conversation_with_memory.predict(input="你好,我是Kevin")
conversation_with_memory.predict(input="我是一个人工智能爱好者,喜欢通过公众号分享人工智能领域相关的知识")
conversation_with_memory.predict(input="我希望你能用我的名字为我的公众号设计一个专业名称")
conversation_with_memory.predict(input="你还可以给出更多选项吗")
示例输出如下
> Entering new chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: 你好,我是Kevin
AI:
> Finished chain.
> Entering new chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
AI: 你好Kevin,我是一个AI,很高兴认识你!我可以为你做什么?
Human: 我是一个人工智能爱好者,喜欢通过公众号分享人工智能领域相关的知识
AI:
> Finished chain.
> Entering new chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: 我希望你能用我的名字为我的公众号设计一个专业名称
AI:
> Finished chain.
> Entering new chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: 你还可以给出更多选项吗
AI: 当然可以!我可以提供更多的选项,以便您可以更好地做出决定。我可以提供更多的信息,以便您可以更好地了解每个选项的优缺点。
> Finished chain.
4.4、ConversationSummaryMemory
ConversationSummaryMemory 是一种解决长对话存储和追踪问题的方法。它通过总结用户和AI之间的交互,建立了过去交互的“running summary”。与ConversationBufferMemory相比,ConversationSummaryMemory具有以下优势:避免了token限制错误和计算成本增加的问题,并且可以更好地记住问题的原始目标。然而,需要注意的是,ConversationSummaryMemory 高度依赖于传递给它的llm模型的摘要能力。
from langchain.llms import OpenAI
from langchain.memory import ConversationSummaryMemory
from langchain.chains import ConversationChain
llm=OpenAI(temperature=0,openai_api_key=os.getenv("OPENAI_API_KEY"))
conversation_with_memory = ConversationChain(
llm=llm,
memory=ConversationSummaryMemory(llm=llm),
verbose=True
)
conversation_with_memory.predict(input="你好,我是Kevin")
conversation_with_memory.predict(input="我是一个人工智能爱好者,喜欢通过公众号分享人工智能领域相关的知识")
conversation_with_memory.predict(input="我希望你能用我的名字为我的公众号设计一个专业名称")
conversation_with_memory.predict(input="你还可以给出更多选项吗")
示例输出如下
> Entering new chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
The human introduces himself as Kevin and the AI introduces itself as an AI and expresses pleasure in meeting Kevin. The AI then asks what it can do for Kevin, to which Kevin responds that he is an AI enthusiast who enjoys sharing knowledge about AI through public channels. Kevin then requests that the AI design a professional name for his public channel, to which the AI agrees and asks if Kevin has any ideas or specific keywords or themes he would like to include in the name.
Human: 你还可以给出更多选项吗
AI: 当然可以!我可以根据你的关键词和主题来提供更多的选项。你有什么想法或者关键词或主题想要包含在你的公共频道名称中吗
> Finished chain.
4.5、ConversationSummaryBufferMemory
ConversationSummaryBufferMemory 是一种结合了维护缓冲区和总结对话的思想。它的工作原理是将最近的对话存储在缓冲区中,而不是丢弃过去的对话。然后,它会对这些对话进行总结,并使用令牌限制来清除对话。
通过将对话存储在缓冲区中,ConversationSummaryBufferMemory可以保留对话的完整性,而不会丢失任何重要的信息。这对于需要对过去的对话进行回顾和参考的场景非常有用。
而通过对对话进行总结,ConversationSummaryBufferMemory可以提取和记录对话的主要要点和信息,从而更有效地管理和利用对话历史。总结后的对话信息可以更加紧凑和易于理解,避免了存储过多的信息或导致令牌限制错误。
最后,ConversationSummaryBufferMemory使用令牌限制来清除对话,这意味着只保留最近的对话,以便在有限的资源下进行更高效的计算。通过清除旧对话,可以释放内存和计算资源,同时仍然保留对话的总结信息。
总的来说,ConversationSummaryBufferMemory是一种综合利用缓冲区和总结对话思想的方法,它可以维护对话的完整性,提取对话的要点,并在有限资源下进行高效的计算和管理。
from langchain.llms import OpenAI
from langchain.memory import ConversationSummaryBufferMemory
from langchain.chains import ConversationChain
llm=OpenAI(temperature=0,openai_api_key=os.getenv("OPENAI_API_KEY"))
conversation_with_memory = ConversationChain(
llm=llm,
memory=ConversationSummaryBufferMemory(llm=llm,max_token_limit=60),
verbose=True
)
conversation_with_memory.predict(input="你好,我是Kevin")
conversation_with_memory.predict(input="我是一个人工智能爱好者,喜欢通过公众号分享人工智能领域相关的知识")
conversation_with_memory.predict(input="我希望你能用我的名字为我的公众号设计一个专业名称")
conversation_with_memory.predict(input="你还可以给出更多选项吗")
示例输出如下
> Entering new chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
The human asks what the AI thinks of artificial intelligence. The AI thinks artificial intelligence is a force for good because it will help humans reach their full potential. Kevin introduces himself and the AI expresses its enthusiasm for artificial intelligence and its willingness to listen to Kevin's knowledge. The AI then offers to help Kevin design a professional name for his public account and suggests some ideas or allows Kevin to come up with his own name.
Human: 你还可以给出更多选项吗
AI: 当然可以!我可以给你一些关于你的公共账户名称的想法,比如“Kevin的科技”,“Kevin的创新”,“Kevin的技术”,“Kevin的AI”,或者你可以自己想一个名字。
> Finished chain.
4.6、Entity Memory
Entity Memory 是一种用于存储特定实体信息的存储器。它通过传递LLM 作为参数来帮助提取实体及其相关信息。随着对话的进行,Entity Memory 逐渐积累有关这些实体的知识。在这里,我们还使用了ENTITYMEMORYCONVERSATION_TEMPLATE ,以避免覆盖 ConversationChain 的默认提示模板。这样,Entity Memory 可以有效地存储和管理对话中涉及的实体信息,为对话提供更准确和丰富的上下文。
from langchain.llms import OpenAI
from langchain.memory import ConversationEntityMemory
from langchain.chains import ConversationChain
from langchain.memory.prompt import ENTITY_MEMORY_CONVERSATION_TEMPLATE
llm = OpenAI(temperature=0,openai_api_key=os.getenv("OPENAI_API_KEY"))
conversation_with_memory = ConversationChain(
llm=llm,
verbose=True,
prompt=ENTITY_MEMORY_CONVERSATION_TEMPLATE,
memory=ConversationEntityMemory(llm=llm)
)
conversation_with_memory.predict(input="Kevin和QinFen是好朋友,但他们不在同一家公司工作")
conversation_with_memory.predict(input="他们都很喜欢学习,QinFen最近做了一个减肥计划")
conversation_with_memory.predict(input="最近QinFen正在准备公司的人工智能创新案例计划,拿到名字希望能跟Kevin出去庆祝")
conversation_with_memory.predict(input="你对Kevin和QinFen了解多少呢?")
示例输出如下
> Entering new chain...
Prompt after formatting:
You are an assistant to a human, powered by a large language model trained by OpenAI.
You are designed to be able to assist with a wide range of tasks, from answering simple questions to providing in-depth explanations and discussions on a wide range of topics. As a language model, you are able to generate human-like text based on the input you receive, allowing you to engage in natural-sounding conversations and provide responses that are coherent and relevant to the topic at hand.
You are constantly learning and improving, and your capabilities are constantly evolving. You are able to process and understand large amounts of text, and can use this knowledge to provide accurate and informative responses to a wide range of questions. You have access to some personalized information provided by the human in the Context section below. Additionally, you are able to generate your own text based on the input you receive, allowing you to engage in discussions and provide explanations and descriptions on a wide range of topics.
Overall, you are a powerful tool that can help with a wide range of tasks and provide valuable insights and information on a wide range of topics. Whether the human needs help with a specific question or just wants to have a conversation about a particular topic, you are here to assist.
> Entering new chain...
Prompt after formatting:
You are an assistant to a human, powered by a large language model trained by OpenAI.
Context:
{'Kevin': 'Kevin是一个好朋友,他和QinFen经常一起出去玩,但是由于他们在不同的公司工作,他们没有太多机会一起工作。他们都很喜欢学习,而且QinFen最近正在准备公司的人工智能创新案例计划,希望他能拿到名字,然后和Kevin一起出去庆祝,一起享受这个成功的时刻。', 'QinFen': 'QinFen是Kevin的好朋友,他们经常一起出去玩,但是由于他们在不同的公司工作,他们没有太多机会一起工作。QinFen很喜欢学习,并且最近也开始了一个减肥计划,希望他能够成功减肥,变得更健康,同时也正在准备公司的人工智能创新案例计划,希望拿到名字后能和Kevin一起出去庆'}
Current conversation:
Human: Kevin和QinFen是好朋友,但他们不在同一家公司工作
AI: 是的,Kevin和QinFen是很好的朋友,他们经常一起出去玩,但是由于他们在不同的公司工作,他们没有太多机会一起工作。
Human: 他们都很喜欢学习,QinFen最近做了一个减肥计划
AI: 是的,Kevin和QinFen都很喜欢学习,而且QinFen最近也开始了一个减肥计划,希望他能够成功减肥,变得更健康。
Human: 最近QinFen正在准备公司的人工智能创新案例计划,拿到名字希望能跟Kevin出去庆祝
AI: 是的,QinFen最近正在准备公司的人工智能创新案例计划,希望他能拿到名字,然后和Kevin一起出去庆祝,一起享受这个成功的时刻。
Last line:
Human: 你对Kevin和QinFen了解多少呢?
You: 我知道Kevin和QinFen是很好的朋友,他们经常一起出去玩,但是由于他们在不同的公司工作,他们没有太多机会一起工作。我也知道他们都很喜欢学习,而且QinFen最近也开始了一个减肥计划,希望他能够成功减肥,变得更健康,同时也正在准备公司的人工智能创新案例计划,希望
> Finished chain.
五、构建带记忆能力的智能机器人
前面我们介绍了如何使用 Streamlit 和 ChatGPT 构建聊天机器人,今天我们将通过接入 LangChain Memory 来增强我们的机器人的记忆功能使其更接近人类智能化水平。
《LangChain神器:只需五步,就能构建自定义知识聊天机器人》
《使用 Langchain、ChatGPT、Pinecone 和 Streamlit 构建交互式聊天机器人》
5.1、Streamlit 交互式机器人
首先安装并导入必要的库
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationChain
from langchain.chains.conversation.memory import ConversationBufferWindowMemory
import streamlit as st
from streamlit_chat import message
-
langchain.chat_models:这是包含可用于生成响应的语言模型的模块。我们将在我们的聊天机器人中使用 OpenAI 的 GPT-3.5 Turbo 模型。
-
langchain.chains:这是包含可用于构建会话代理的不同类型链的模块。在本例中,我们将使用 来
ConversationChain跟踪对话历史记录并生成响应。 -
langchain.chains.conversation.memory:该模块包含不同类型的内存对象,可用于存储对话历史记录。在本例中,我们将使用
ConversationBufferWindowMemory,它存储对话历史记录的固定长度窗口。 -
Streamlit: Streamlit 是一个用于构建交互式数据科学 Web 应用程序的 Python 框架,而 Streamlit Chat 是一个 Python 包,为 Streamlit 应用程序提供聊天机器人界面
这里使用st.title()函数给聊天机器人取个名字。使用st.text_input()函数为用户输入查询创建一个文本区域。初始化会话状态变量"past"和"generated",并使用st.session_state来存储来自ChatGPT API的查询和生成的响应。
这样,即使用户刷新页面或离开应用程序并稍后返回,也可以保留聊天历史记录,并在聊天界面中向用户展示。
st.title("Smart ChatBot")
query = st.text_input("Query: ", key="input")
if 'responses' not in st.session_state:
st.session_state['responses'] = []
if 'requests' not in st.session_state:
st.session_state['requests'] = []
接下来,需要设置 OpenAI API 密钥,并使用 ChatOpenAI 类和 ChatGPT(当前使用的 GPT-3.5 Turbo 模型)启动我们的 LLM
llm = ChatOpenAI(model_name="gpt-3.5-turbo", openai_api_key=os.getenv("OPENAI_API_KEY"))
在这段代码中,我们创建了一个ConversationBufferWindowMemory对象,并将其分配给会话状态变量'buffer_memory'(如果该变量尚不存在)。ConversationBufferWindowMemory 是一种内存,用于在有限大小的缓冲区窗口中存储对话历史记录。参数"k"指定了可以存储在内存缓冲区窗口中的最大轮数(即用户和聊天机器人之间的来回交换)。当达到最大轮数时,最旧的轮将从内存中删除,以便为新的轮腾出空间。
if 'buffer_memory' not in st.session_state:
st.session_state.buffer_memory= ConversationBufferWindowMemory(k=3)
在下一步中,我们通过传入必要的参数来初始化对话链。参数"llm"指定用于生成响应的语言模型,在这个例子中是ChatOpenAI对象。参数"verbose"设置为True,以便在调试时打印会话的详细信息。
然而,最关键的参数是"memory"。我们将存储在st.sessionstate.buffermemory中的ConversationBufferWindowMemory对象传递给对话链的内存参数ConversationChain。这样做是为了让聊天机器人能够在其内存缓冲区中存储和检索以前的对话。
conversation = ConversationChain(
llm=llm,
memory=st.session_state.buffer_memory,
verbose=True
)
如果有用户提供输入,我们将使用chain.run方法从llm获取响应。然后,我们将用户的查询添加到会话状态变量 st.session_state.requests 中,并将生成的响应添加到 st.session_state.responses 中,以便将其记录在聊天历史中。
if query:
response = conversation.run(query)
st.session_state.requests.append(query)
st.session_state.responses.append(response)
现在我们进入显示对话的最后一步。如果会话状态变量st.session_state中有生成的响应,那么我们将启动一个for循环。循环将按照从最新响应到最早响应的顺序迭代列表。
对于每个生成的响应,我们调用message()函数两次,以显示用户提出的查询和由llm生成的响应。参数key用于唯一标识每条消息。
if st.session_state['responses']:
for i in range(len(st.session_state['responses'])-1, -1, -1):
message(st.session_state['requests'][i], is_user=True, key=str(i) + '_user')
message(st.session_state["responses"][i], key=str(i))
到此,我们已经成功构建了一个具有会话记忆的自定义聊天机器人,并且可以使用以下命令运行该应用程序。
streamlit run file_name.py
5.2、CLI命令行交互式机器人
为了方便直接在Google Colab环境中运行带记忆能力的机器人,直接使用以下代码运行,输入quit结束对话。
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationChain
from langchain.chains.conversation.memory import ConversationBufferWindowMemory
import os
import sys
def message(msg, is_user=False, key=None):
if is_user:
print(f"User: {msg}")
else:
print(f"Bot: {msg}")
print("Smart ChatBot")
if 'responses' not in globals():
responses = []
if 'requests' not in globals():
requests = []
llm = ChatOpenAI(model_name="gpt-3.5-turbo", openai_api_key=os.getenv("OPENAI_API_KEY"))
if 'buffer_memory' not in globals():
buffer_memory = ConversationBufferWindowMemory(k=3)
conversation = ConversationChain(
llm=llm,
memory=buffer_memory,
verbose=True
)
while True:
query = input("Query: ")
if query.lower() == "quit":
break
response = conversation.run(query)
requests.append(query)
responses.append(response)
message(query, is_user=True)
message(response)
Jupyter Notebook 的完整代码:
https://github.com/Crossme0809/langchain-tutorials/blob/main/LangChainMemoryChatGPT_ChatBot.ipynb
六、总结
本文介绍了在快速发展的人工智能领域中,聊天机器人的重要性以及传统聊天机器人的局限性。为了解决这些问题,引入了LangChain对话记忆的概念,使聊天机器人能够记住过去的交互并生成更相关的响应。
文章详细介绍了LangChain的内存世界和各种类型及功能,并探讨了如何将LangChain与Streamlit和OpenAI GPT API结合起来构建更智能、反应更灵敏的聊天机器人。
最后,文章提出了使用LangChain Memory来增强聊天机器人记忆功能的方法,使其更接近人类智能水平。
如果你对这篇文章感兴趣,而且你想要了解更多关于AI领域的实战技巧,可以关注「技术狂潮AI」公众号。在这里,你可以看到最新最热的AIGC领域的干货文章和案例实战教程。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐

 1
1 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)