
使用 Langchain-chatchat 搭建 RAG 应用,并使用postman进行测试验证
LangChain-Chatchat (原 Langchain-ChatGLM),一种利用 langchain 思想实现的基于本地知识库的问答应用,目标期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案。
最近这一两周不少互联网公司都已经开始秋招提前批面试了。
不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
总结如下:
《大模型面试宝典》(2024版) 发布!
《AIGC 面试宝典》圈粉无数!
喜欢本文记得收藏、关注、点赞

Github地址:https://github.com/chatchat-space/Langchain-Chatchat
一、概述
LangChain-Chatchat (原 Langchain-ChatGLM),一种利用 langchain 思想实现的基于本地知识库的问答应用,目标期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案。
本项目的最新版本中可使用 Xinference、Ollama 等框架接入 GLM-4-Chat、 Qwen2-Instruct、 Llama3 等模型,依托于 langchain 框架支持通过基于 FastAPI 提供的 API 调用服务,或使用基于 Streamlit 的 WebUI 进行操作。
本项目支持市面上主流的开源 LLM、 Embedding 模型与向量数据库,可实现全部使用开源模型离线私有部署。与此同时,本项目也支持 OpenAI GPT API 的调用,并将在后续持续扩充对各类模型及模型 API 的接入。
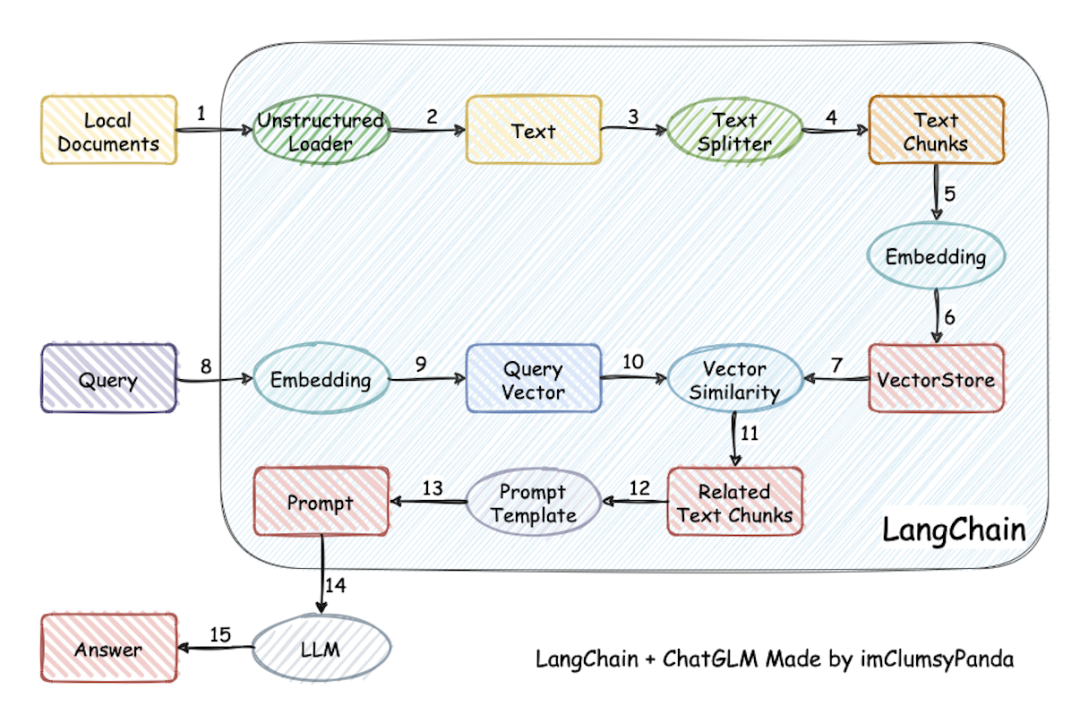
本项目实现原理如下图所示,过程包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的 top k个 -> 匹配出的文本作为上下文和问题一起添加到 prompt中 -> 提交给 LLM生成回答。
0.3.x 版本功能一览
| 功能 | 0.2.x | 0.3.x |
|---|---|---|
| 模型接入 | 本地:fastchat | |
| 在线:XXXModelWorker | 本地:model_provider,支持大部分主流模型加载框架 | |
| 在线:oneapi | ||
| 所有模型接入均兼容openai sdk | ||
| Agent | ❌不稳定 | ✅针对ChatGLM3和Qwen进行优化,Agent能力显著提升 |
| LLM对话 | ✅ | ✅ |
| 知识库对话 | ✅ | ✅ |
| 搜索引擎对话 | ✅ | ✅ |
| 文件对话 | ✅仅向量检索 | ✅统一为File RAG功能,支持BM25+KNN等多种检索方式 |
| 数据库对话 | ❌ | ✅ |
| 多模态图片对话 | ❌ | ✅ 推荐使用 qwen-vl-chat |
| ARXIV文献对话 | ❌ | ✅ |
| Wolfram对话 | ❌ | ✅ |
| 文生图 | ❌ | ✅ |
| 本地知识库管理 | ✅ | ✅ |
| WEBUI | ✅ | ✅更好的多会话支持,自定义系统提示词… |
0.3.x 版本的核心功能由 Agent 实现,但用户也可以手动实现工具调用:
| 操作方式 | 实现的功能 | 适用场景 |
|---|---|---|
| 选中"启用Agent",选择多个工具 | 由LLM自动进行工具调用 | 使用ChatGLM3/Qwen或在线API等具备Agent能力的模型 |
| 选中"启用Agent",选择单个工具 | LLM仅解析工具参数 | 使用的模型Agent能力一般,不能很好的选择工具 |
| 想手动选择功能 | ||
| 不选中"启用Agent",选择单个工具 | 不使用Agent功能的情况下,手动填入参数进行工具调用 | 使用的模型不具备Agent能力 |
| 不选中任何工具,上传一个图片 | 图片对话 | 使用 qwen-vl-chat 等多模态模型 |
已支持的模型部署框架与模型
本项目中已经支持市面上主流的如 GLM-4-Chat 与 Qwen2-Instruct 等新近开源大语言模型和 Embedding 模型,这些模型需要用户自行启动模型部署框架后,通过修改配置信息接入项目,本项目已支持的本地模型部署框架如下:
| 模型部署框架 | Xinference | LocalAI | Ollama | FastChat |
|---|---|---|---|---|
| OpenAI API 接口对齐 | ✅ | ✅ | ✅ | ✅ |
| 加速推理引擎 | GPTQ, GGML, vLLM, TensorRT, mlx | GPTQ, GGML, vLLM, TensorRT | GGUF, GGML | vLLM |
| 接入模型类型 | LLM, Embedding, Rerank, Text-to-Image, Vision, Audio | LLM, Embedding, Rerank, Text-to-Image, Vision, Audio | LLM, Text-to-Image, Vision | LLM, Vision |
| Function Call | ✅ | ✅ | ✅ | / |
| 更多平台支持(CPU, Metal) | ✅ | ✅ | ✅ | ✅ |
| 异构 | ✅ | ✅ | / | / |
| 集群 | ✅ | ✅ | / | / |
| 操作文档链接 | Xinference 文档 | LocalAI 文档 | Ollama 文档 | FastChat 文档 |
| 可用模型 | Xinference 已支持模型 | LocalAI 已支持模型 | Ollama 已支持模型 | FastChat 已支持模型 |
除上述本地模型加载框架外,项目中也为可接入在线 API 的 One API 框架接入提供了支持,支持包括 OpenAI ChatGPT、Azure OpenAI API、Anthropic Claude、智谱清言、百川 等常用在线 API 的接入使用。
二、安装使用
2.1 软硬件要求
💡 软件方面,本项目已支持在 Python 3.8-3.11 环境中进行使用,并已在 Windows、macOS、Linux 操作系统中进行测试。
💻 硬件方面,因 0.3.0 版本已修改为支持不同模型部署框架接入,因此可在 CPU、GPU、NPU、MPS 等不同硬件条件下使用。
2.2 安装 Langchain-Chatchat
从 0.3.0 版本起,Langchain-Chatchat 提供以 Python 库形式的安装方式,具体安装请执行:
pip install langchain-chatchat -U
执行上述命令之前,最好先安装一个python虚拟机,具体安装方式如下:
conda create -n chatchat python=3.11
因模型部署框架 Xinference 接入 Langchain-Chatchat 时需要额外安装对应的 Python 依赖库,因此如需搭配 Xinference 框架使用时,建议使用如下安装方式:
pip install "langchain-chatchat[xinference]" -U
安装好python环境后,正式进入Langchain-chatchat环境配置。
2.3 初始化项目配置与数据目录
1. 设置 Chatchat 存储配置文件和数据文件的根目录(可选)
# on linux or macos
export CHATCHAT_ROOT=/path/to/chatchat_data
# on windows
set CHATCHAT_ROOT=/path/to/chatchat_data
|若不设置该环境变量,则自动使用当前目录。
2. 执行初始化
chatchat init
该命令会执行以下操作:
-
创建所有需要的数据目录
-
复制 samples 知识库内容
-
生成默认 yaml 配置文件
3. 修改配置文件
a)配置模型(model_settings.yaml)
需要根据步骤 2. 模型推理框架并加载模型 中选用的模型推理框架与加载的模型进行模型接入配置,具体参考 model_settings.yaml 中的注释。主要修改以下内容:
# 默认选用的 LLM 名称
DEFAULT_LLM_MODEL: qwen1.5-chat
# 默认选用的 Embedding 名称
DEFAULT_EMBEDDING_MODEL: bge-large-zh-v1.5
# 将 `LLM_MODEL_CONFIG` 中 `llm_model, action_model` 的键改成对应的 LLM 模型
# 在 `MODEL_PLATFORMS` 中修改对应模型平台信息
b)配置知识库路径(basic_settings.yaml)(可选)
默认知识库位于 CHATCHAT_ROOT/data/knowledge_base,如果你想把知识库放在不同的位置,或者想连接现有的知识库,可以在这里修改对应目录即可。
# 知识库默认存储路径
KB_ROOT_PATH: D:\chatchat-test\data\knowledge_base
# 数据库默认存储路径。如果使用sqlite,可以直接修改DB_ROOT_PATH;如果使用其它数据库,请直接修改SQLALCHEMY_DATABASE_URI。
DB_ROOT_PATH: D:\chatchat-test\data\knowledge_base\info.db
# 知识库信息数据库连接URI
SQLALCHEMY_DATABASE_URI: sqlite:///D:\chatchat-test\data\knowledge_base\info.db
c)配置知识库(kb_settings.yaml)(可选)
默认使用 FAISS 知识库,如果想连接其它类型的知识库,可以修改 DEFAULT_VS_TYPE 和 kbs_config。
2.4 初始化知识库
进行知识库初始化前,请确保已经启动模型推理框架及对应 embedding 模型,且已按照上述步骤3完成模型接入配置。
chatchat kb -r
|会预加载Langchain-chatchat自带的文档,包括txt,excel,csv等格式文件
2.5 启动项目
chatchat start -a
出现以下界面即为启动成功:
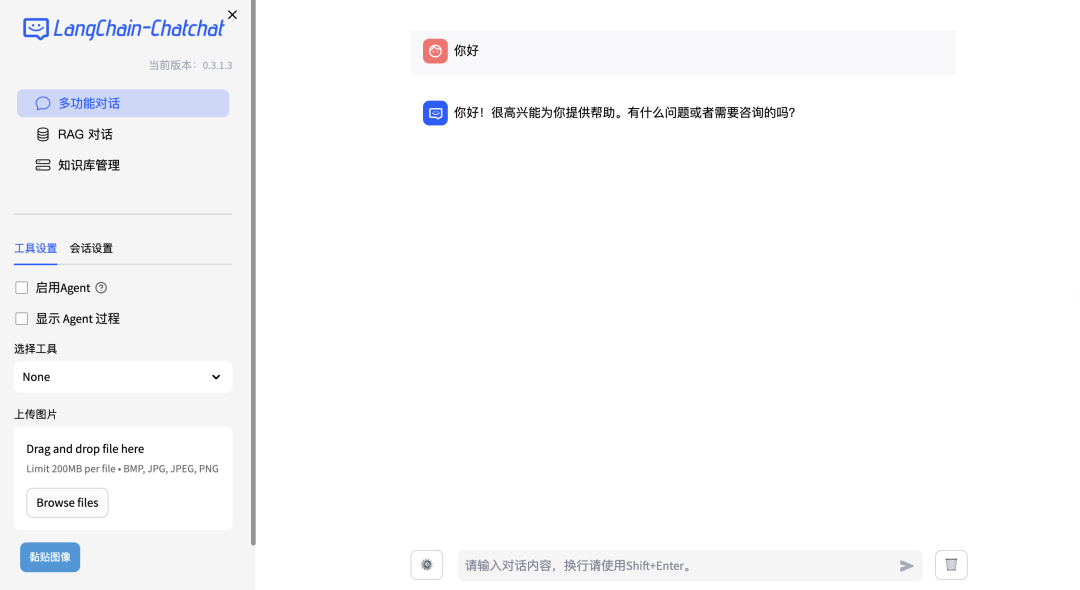
可以在Langchain-chatchatWEBUI界面中选择《多功能对话》、《RAG对话》、《知识库管理》等功能,其中,《多功能对话》中也可以选择“本地知识库”实现RAG对话功能。
其他功能,自行开发。
三、项目部署调用
3.1 API调用方式
可以参考官方链接:
https://github.com/chatchat-space/Langchain-Chatchat/blob/master/docs/contributing/api.md
把如下文件内容写入infer_test.py即可进行测试验证。
base_url = "http://127.0.0.1:7861/knowledge_base/local_kb/samples"
data = {
"model": "qwen:7b",
"messages": [
{"role": "user", "content": "你好"},
{"role": "assistant", "content": "你好,我是人工智能大模型"},
{"role": "user", "content": "我司的愿景是什么?"},
],
"stream": True,
"temperature": 0.7,
"extra_body": {
"top_k": 3,
"score_threshold": 2.0,
"return_direct": False,
},
}
import openai
client = openai.Client(base_url=base_url, api_key="EMPTY")
resp = client.chat.completions.create(**data)
result_str = ""
for r in resp:
result_str += r.choices[0].delta.content
print("result_str------------------------\n", result_str)
3.2 flask调用方式
把如下文件内容写入infer_flask.py即可进行测试验证。
from flask import Flask
from flask import request
import json
app = Flask(__name__)
@app.route("/", methods=["GET"])
def hello_world():
return "<p>Hello, World!</p>"
@app.route('/query', methods=["GET", "POST"])
def query():
if request.method == 'POST':
base_url = "http://127.0.0.1:7861/knowledge_base/local_kb/samples"
query = request.form.get("query")
data = {
"model": "qwen:7b",
"messages": [
{"role": "user", "content": "你好"},
{"role": "assistant", "content": "你好,我是人工智能大模型"},
{"role": "user", "content": query},
],
"stream": True,
"temperature": 0.7,
"extra_body": {
"top_k": 3,
"score_threshold": 2.0,
"return_direct": False,
},
}
import openai
client = openai.Client(base_url=base_url, api_key="EMPTY")
resp = client.chat.completions.create(**data)
result_str = ""
for r in resp:
result_str += r.choices[0].delta.content
print("Query:",query)
return f'Answer:{result_str}'
else:
return "successful"
if __name__ == '__main__':
# 运行app,默认运行在5000
# 默认是host='127.0.0.1', port=5000端口
app.run(host="0.0.0.0", port=7777, debug=True)
运行上述文件
python infer_flask.py
可以在浏览器输入对应的url进行GET请求访问(下面内容仅用作测试)
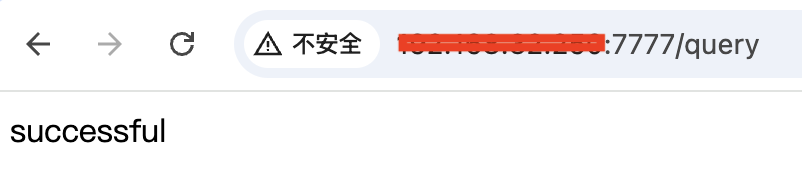
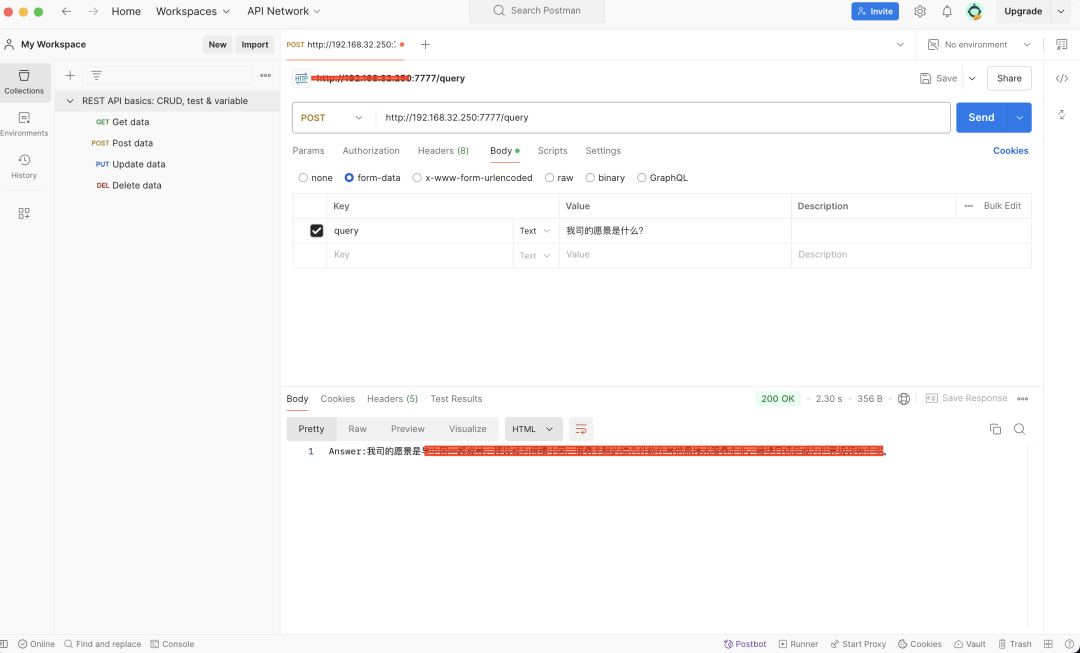
由于浏览器无法验证POST请求,因此需要下载postman软件进行验证,下载地址:https://www.postman.com/downloads/
下载好postman软件,然后新建Collections,输入测试的url,并选择请求类型(比如GET、POST),如果有参数,可以输入参数名称和参数内容,最后执行“send”即可。案例如下图所示:

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 17
17 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)