Macbook air M2 16G 用cpu跑同大模型知识库文档系统(Langchain-chatchat+llama2-7B量化模型)
经过了5个夜晚的煎熬,终于从一个完全不知大模型为何物的小白身份把知识库问答大模型搞起来,一路尝试几斤辛酸,特别记录下来踩过的各种坑,供大家借鉴!
Macbook air M2 16G 用cpu跑同大模型知识库文档系统(Langchain-chatchat+llama2-7B量化模型)
经过了5个夜晚的煎熬,终于从一个完全不知大模型为何物的小白身份把知识库问答大模型搞起来,一路尝试几斤辛酸,特别记录下来踩过的各种坑,供大家借鉴!
本人的目标:
- 在我自己的Macbook air m2 16g运行离线大模型,因为项目需要的一定是离线环境,不允许连接互联网。
- 一定要外接本地知识库进行问答,因为项目涉及海量TB级别的文件资料,必须以这些私域数据为基础进行场景构建。
过程中需要用到的工具
- miniconda,用来构建虚拟环境,以便在虚拟环境中下载相关依赖,免得把电脑的环境搞乱套了。
- git-lfs,高速下载工具,模型都比较大,这个工具下载速度很快。
- vscode(可选),用来查看源码,修改配置
运行效果
开始之前,先看下效果图:
-
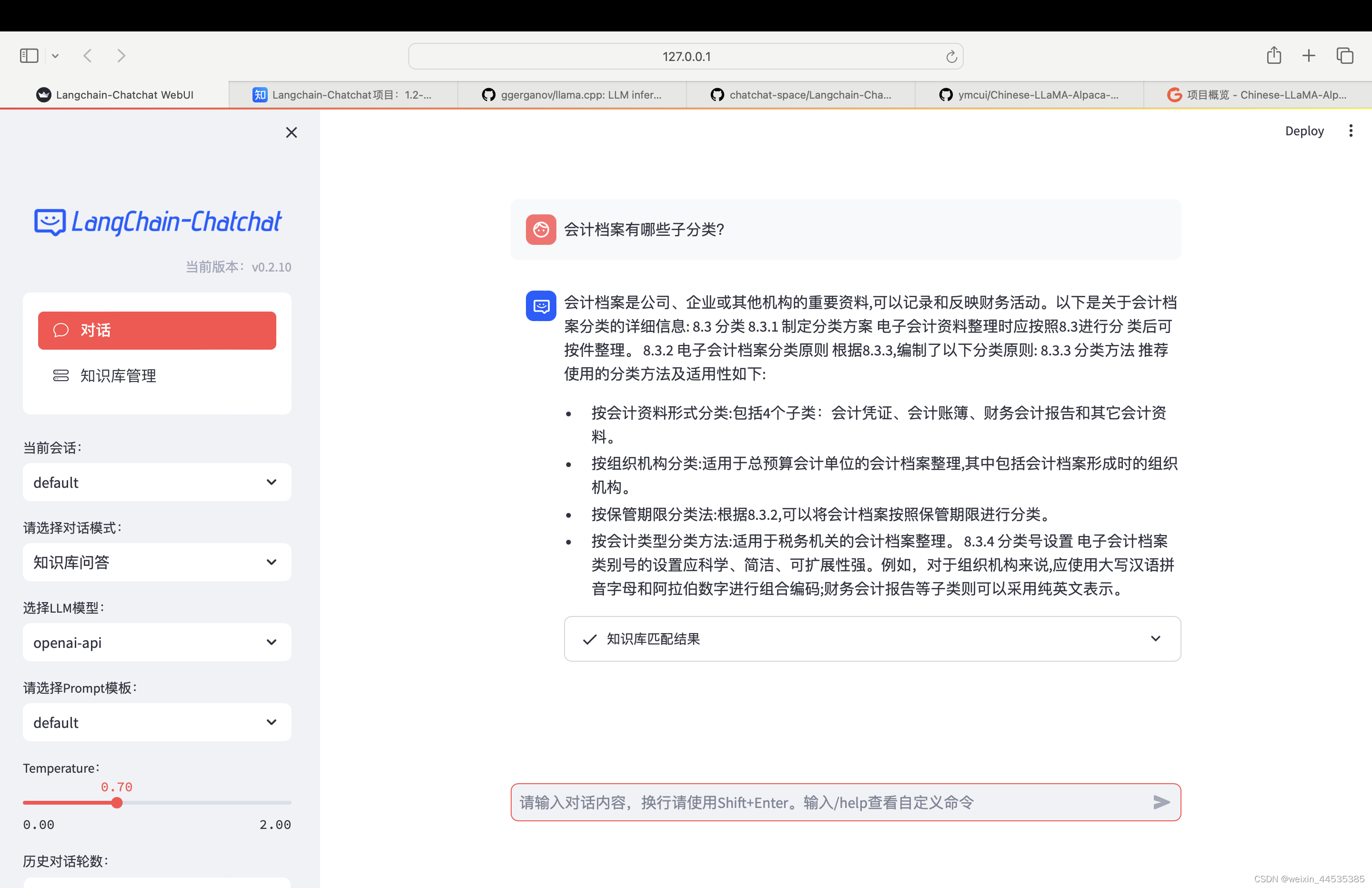
对话效果1

-
对话效果2

-
上述对话涉及的知识库

-
运行时电脑状态
cpu状态,如下图,负载极低,同时机器也完全不热;上传文档时会大量发热,尤其是上传扫描件的pdf时(大量的ocr运算导致的)

内存占用也很小,不得不说llama.cpp确实做的够牛

对话效果跟提问方式有挺大关系,还没太找到提问的最佳事件,这个就后续摸索了,也是大家此环境的目标。
长话短说,开始安装
安装过程
需要安装2个工程,下载1个模型,更改3-4个配置文件,最后2个命令运行。
第一步:安装llama.cpp,并以web服务的形式启动,提供rest接口给Langchain-chatchat进行调用
这个c++版本的工程是关键,就是这个工程使得在我这个电脑上轻松运行大模型成为可能。
进入macos自带的命令终端:
- 创建llama.cpp的虚拟环境
conda create -n llama-cpp python=3.11.7
- 激活虚拟环境
conda activate llama-cpp
关闭该环境的命令(暂时不要使用)
conda deactivate
3. 拉取源码将 llama.cpp
git clone https://github.com/ggerganov/llama.cpp.git
- 切换到 llama.cpp 目录
cd llama.cpp
- 安装依赖
pip install -r requirements.txt
- 编译 llama.cpp工程,会生成很多文件,包括可执行文件,前面的参数是:开启M2芯片的GPU推理
LLAMA_METAL=1 make
- 下载大语言模型文件Chinese-LLaMA-2-7B,下载embedding模型bge-large-zh(第二个工程安装时用到),两个模型。
下载方式1:百度网盘地址: https://pan.baidu.com/s/1wxx-CdgbMupXVRBcaN4Slw?pwd=kpn9
下载方式2:使用git-lfs工具(),获取去官网下载该工具;
依次此行如下命令,每一行为一个命令:
brew install git-lfs
cd models
git lfs install
wget https://hf-mirror.com/hfd/hfd.sh
chmod a+x hfd.sh
export HF_ENDPOINT=https://hf-mirror.com
brew install aria2
./hfd.sh BAAI/bge-large-zh --repo-type dataset --tool aria2 -x 4
./hfd.sh hfl/chinese-alpaca-2-7b --repo-type dataset --tool aria2 -x 4
模型官网:https://github.com/ymcui/Chinese-LLaMA-Alpaca-2
将下载好的模型目录拷贝至当前目录 (llama.cpp) 的 models 中。(得到模型目录位置为 llama.cpp/models/chinese-alpaca-2-7b-hf)
BGE-Large-zh 是一种基于百度大脑的中文通用语义表示模型,能够将文本转换为高维向量,用于各种自然语言处理任务。
aria2 是个多线程下载的工具库,下载模型时速度更快
- 生成量化版本(关键、关键、关键),量化为int4版本(啥叫量化,自己百度吧)
回到llama.cpp文件下
cd ..
执行如下命令进行量化,需要挺长时间
python convert.py models/chinese-alpaca-2-7b-hf/
./quantize ./models/chinese-alpaca-2-7b-hf/ggml-model-f16.gguf ./models/chinese-alpaca-2-7b-hf/ggml-model-q4_0.gguf q4_0
会在models/chinese-alpaca-2-7b-hf下生成2个新的文件,其中models/chinese-alpaca-2-7b-hf/ggml-model-q4_0.gguf,这个文件就是咱们量化的大语言模板文件了。
9. 修改执行脚步,可以用vscode等工具打开源码工程
cd examples
修改chat.sh文件,修改模型文件的位置,如下
./main -m ./models/chinese-alpaca-2-7b-hf/ggml-model-q4_0.gguf -c 512 -b 1024 -n 256 --keep 48 \
--repeat_penalty 1.0 --color -i \
-r "User:" -f prompts/chat-with-bob.txt
- 命令行方式启动,测试一下大模型
./examples/chat.sh
启动后即可进行对话,测试完成后,ctrl+c结束进程。
至此,llama2的中文7B量化模型安装完毕
11. web server方式启动
查看examples/server/README.md文件可以了解web server的相关说明
在llama.cpp根目录下,执行如下命令,可以启动web server
./server -m models/chinese-alpaca-2-7b-hf/ggml-model-q4_0.gguf -c 2048
启动后,在浏览器中http://localhost:8080

类似openAI的接口启动成功,此接口为langchain-chatchat应用提供大语言模型能力:
base_url="http://localhost:8080/v1", # "http://<Your api-server IP>:port"
api_key = "sk-no-key-required"
至此,本次部署的第一个应用完成。
第二步,部署Langchain-chatchat,该应用的目的是提供本地文档知识库、文档分割、文档向量话,并提供可视化界面。
该工程基于Langchain框架,原理如下图:

图中的LLM就是第一步部署的本地LLama2-7B的量化模型,当然该框架支持的LLM还有很多,可以参考官网资料:
https://github.com/chatchat-space/Langchain-Chatchat
开始安装Langchain-chatchat
- 拉取工程源码:
# 拉取仓库
git clone https://github.com/chatchat-space/Langchain-Chatchat.git
- 修改配置文件
找到配置文件requirements,注释掉如下两行:
python-magic-bin; sys_platform == 'win32'
vllm==0.2.7; sys_platform == "linux"
然后,依次执行如下命令
conda create -n langchain-chatchat python=3.11.7
conda activate langchain-chatchat
- 进入工程根目录Langchain-chatchat
# 安装全部依赖
pip install -r requirements.txt
pip install -r requirements_api.txt
pip install -r requirements_webui.txt
# 默认依赖包括基本运行环境(FAISS向量库)。如果要使用 milvus/pg_vector 等向量库,请将 requirements.txt 中相应依赖取消注释再安装。
> 如果提示你torch安装失败,则执行pip install torch==2.1.2 然后再执行上面的3个安装命令。
- 初始化配置文件、初始化samples知识库,安装矢量数据库
# 将项目 configs/ 目录下的 example 配置文件复制生成一份新的配置文件
# 后续根据自己的环境对配置文件进行修改
$ python copy_config_example.py
# 创建矢量数据库。矢量数据库用于后续自建知识库时存储分词、索引后的数据
$ python init_database.py --recreate-vs
- 编辑 configs/model_config.py 文件,修改如下几个参数
# 模型存放目录,修改成模型下载的路径
MODEL_ROOT_PATH = ""
# Embedding 模型运行设备。设为 "auto" 会自动检测(会有警告),也可手动设定为 "cuda","mps","cpu","xpu" 其中之一。
EMBEDDING_DEVICE = "mps"
# LLM 模型运行设备。设为"auto"会自动检测(会有警告),也可手动设定为 "cuda","mps","cpu","xpu" 其中之一。
LLM_DEVICE = "mps"
继续修改改配置文件,设置启动时调用的模型
LLM_MODELS = ["openai-api"]
关键:修改在线大语言模型配置,改为我们的llama.cpp启动的本地llm模型对应的rest接口,如下
ONLINE_LLM_MODEL = {
# "openai-api": {
# "model_name": "gpt-4",
# "api_base_url": "https://api.openai.com/v1",
# "api_key": "",
# "openai_proxy": "",
# },
#llama.cpp(模拟openai的api)运行量化后llama2模型chinese-alpaca-2-7b-hf,
"openai-api": {
"model_name": "gpt-4",
"api_base_url": "http://localhost:8080/v1",
"api_key": "sk-no-key-required",
"openai_proxy": "",
},
至此,Langchain-chatchat安装完毕
启动项目
- 确保第一步安装的llama.cpp的webserver已经启动
- 启动langchain-chatchat
进入工程根目录,执行如下命令:
# python startup.py -h 查看帮助,
# -a 是api服务和webui服务都启动
python startup.py -a
浏览器地址 http://localhost:8501
完毕!!!
参考文档:
- 使用 MacBook Pro M1 16G 运行 Llama 2 7B (Apple Silicon 通用方法)
原文链接:https://blog.csdn.net/weixin_45063926/article/details/134223582 - [机器学习]-如何在MacBook上部署运行Langchain-Chatchat
原文链接:https://blog.csdn.net/owlion/article/details/136526106 - https://github.com/THUDM/ChatGLM3/discussions/894
- https://blog.csdn.net/weixin_42232045/article/details/134659394
- https://zhuanlan.zhihu.com/p/653378749
- https://zhuanlan.zhihu.com/p/664118127

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 53
53 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)