毕业设计:基于深度学习的飞机识别目标检测系统 人工智能
毕业设计:基于深度学习的飞机识别目标检测系统通过结合深度学习和计算机视觉技术,该系统能够从大量的图像数据中学习飞机目标的特征,并实现高精度的目标检测和识别。这为计算机毕业设计提供了一个创新的方向,结合了深度学习和计算机视觉技术,为毕业生提供了一个有意义的研究课题。对于计算机专业、软件工程专业、人工智能专业、大数据专业的毕业生而言,提供了一个具有挑战性和创新性的研究课题。无论您对深度学习技术保持浓厚
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的飞机识别目标检测系统
设计思路
一、课题背景与意义
飞机识别目标检测是计算机视觉领域的重要研究方向。在军事、航空安全、无人机监管等领域,准确地检测和识别飞机目标对于实时监控、安全预警和自动化决策具有关键意义。然而,传统的目标检测方法在复杂场景下面临挑战,而基于深度学习的飞机识别目标检测系统能够通过学习大量的图像数据,自动提取飞机目标的特征,并实现高精度的目标检测和识别。该课题旨在结合深度学习和计算机视觉技术,开发一种高效准确的飞机识别目标检测系统,为相关领域的实际应用提供技术支持和解决方案。
二、算法理论原理
2.1 卷积神经网络
近年来,随着计算能力的提升,尤其是GPU集群等并行计算系统的普及,卷积神经网络得到了快速发展,并在计算机视觉、自然语言处理等领域得到广泛应用。卷积神经网络的核心特性包括稀疏连接和权值共享,这些特性减少了参数数量和存储需求,提高了网络的泛化能力,并有效避免了过拟合问题。此外,卷积神经网络通过卷积运算能够将低维图像信息映射为高维特征,其结构主要包括输入层、卷积层、池化层、非线性层和全连接层。

卷积神经网络(CNN)的输入层接收一张图像,通常表示为一个三维向量,其中长和宽代表图像的尺寸,高代表颜色通道数。输入层会对图像进行预处理以提高模型收敛速度和泛化性。卷积层使用卷积核(滤波器)在图像上滑动,通过内积提取特征,并使用梯度下降和反向传播更新权重。卷积过程中的步长和填充控制特征图分辨率。池化层通过降采样减少特征图分辨率,常用的池化方法包括最大池化、平均池化和随机池化,这些方法可以减少参数量和计算量,同时保留重要特征并提高网络的抗过拟合能力。

2.2 目标检测算法
CNN是二阶段目标检测的第一个算法,将深度卷积神经网络应用于目标检测。RCNN使用深度卷积神经网络作为骨干网络进行特征提取,而不是使用传统的特征描述符。这种改进提高了检测精度约30%,在VOC数据集上达到了58.8%的检测精度。RCNN的网络结构包括四个主要部分:生成候选区域、裁剪候选区域、使用卷积神经网络提取特征向量,以及使用SVM进行分类和回归。

Fast RCNN是对RCNN的改进,它的网络结构使用了ROI pooling和softmax分类器,同时进行分类和边界框回归的多任务训练,实现了端到端的检测。这些改进使得Fast RCNN在准确性和速度方面都优于RCNN和SPPNet。Fast RCNN算法结构由以下几个组成部分组成:首先,通过选择性搜索方法生成候选区域。然后,使用ROI pooling将这些候选区域映射到特征图上,并通过最大池化操作得到固定大小的特征。接下来,将这些特征送入全连接层进行分类和边界框回归,使用softmax代替支持向量机分类器,并进行多任务训练。最终,实现了端到端的检测。

三、检测的实现
3.1 数据集
由于网络上没有现有的合适的飞机目标检测数据集,我决定通过相机拍摄和互联网收集两种方式进行数据集的收集。首先,我使用相机对不同场景下的飞机进行拍摄,包括在机场、航空展览和实际飞行中等各种场景下的飞机图像。其次,我通过互联网收集了大量的飞机图像,包括各种型号、颜色和角度的飞机。通过这两种方式的数据采集,我得到了一个包含多个场景和丰富的飞机图像的数据集,为后续的目标检测研究提供了基础。

为了增加数据集的多样性和扩充训练样本,我使用了数据扩充技术。数据扩充是通过对原始数据进行变换和增强,生成新的样本,以增加训练集的多样性和数量。在飞机识别目标检测系统中,数据扩充可以包括图像的旋转、缩放、平移和镜像翻转等操作,以模拟不同角度和尺度下的飞机目标。此外,还可以应用随机裁剪、色彩变换和噪声添加等技术,使得模型对于光照、背景和噪声等因素具有更好的鲁棒性。通过数据扩充,我能够生成更多样化的训练样本,提高了模型的泛化能力和准确性。

3.2 实验环境搭建
实验采用的电脑硬件配置包括Intel(R) 3.3Core(TM)i7-10750H CPU和Nvidia GeForce GTX 1660Ti GPU,内存为16GB。操作系统为Ubuntu 20.04。实验使用了pytorch深度学习框架进行模型训练和推理,pycharm作为编译软件,以及Python编程语言进行编写。这样的配置能够提供较好的计算性能和运行效率,使得实验能够在相对较短的时间内进行模型训练和评估。
3.3 实验及结果分析
为了节省训练时间并加快模型的收敛速度,在自制数据集上进行了预训练,然后在飞机数据集上利用预训练得到的权重超参数进行实验。实验中设置了动量参数为0.9,权重衰减系数为0.0005,初始学习率为0.001,总共进行了100个epoch的训练。每隔30个epoch,学习率会降低为之前的0.1。实验中的batch_size为4,采用adam优化器对网络进行优化。

在本实验中,为了比较改进前后模型对飞机数据集中模糊、曝光等目标的检测效果以及检测性能,我们选择了准确率P(Precision)、召回率R(Recall)和平均精度AP(Average Precision)作为评价指标。

相关代码示例:
import torch
import torch.optim as optim
from torchvision.models import resnet18 # 假设我们使用ResNet-18作为基础模型
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
from torch.optim.lr_scheduler import StepLR
# 加载数据集
train_dataset = ImageFolder('path_to_train_dataset', transform=torchvision.transforms.ToTensor())
train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True)
# 加载预训练模型
model = resnet18(pretrained=True)
# 如果有自定义的模型,可以加载预训练权重
# model.load_state_dict(torch.load('path_to_pretrained_weights'))
# 设置优化器
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=0.0005)
# 设置学习率调度器
scheduler = StepLR(optimizer, step_size=30, gamma=0.1)
# 训练模型
num_epochs = 100
for epoch in range(num_epochs):
model.train()
for images, _ in train_loader:
optimizer.zero_grad()
outputs = model(images)
# 假设我们使用均方误差损失
loss = torch.mean((outputs - targets)**2)
loss.backward()
optimizer.step()
# 更新学习率
scheduler.step()
# 每个epoch结束后可以打印损失或者进行其他操作
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item()}')
# 保存训练好的模型
torch.save(model.state_dict(), 'trained_model.pth')
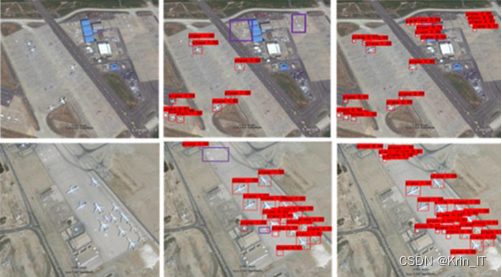
实现效果图样例:




创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!
最后

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 18
18 0
0- 0



 已为社区贡献67条内容
已为社区贡献67条内容

所有评论(0)