毕业设计-基于深度学习的人脸疲劳检测识别系统 人工智能 算法 机器视觉
毕业设计选题:基于深度学习的人脸疲劳检测识别算法系统的毕业设计。通过融合先进的计算机视觉技术和深度学习算法,该系统能够实时监测驾驶员或操作人员的疲劳状态,如闭眼、低头、打哈欠等迹象,并及时发出警示,确保驾驶安全和工作效率。为计算机科学、人工智能、图像处理等专业的毕业生提供了一个具有挑战性和创新性的研究课题。无论您对深度学习技术保持浓厚兴趣,还是希望在人机交互、智能驾驶或工作场所安全等领域深入研究,
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的人脸疲劳检测识别系统
课题背景和意义
疲劳检测可以应用于驾驶员监控、工作场所安全以及医疗健康等领域,旨在识别和预测人的疲劳状态,以便及时采取措施避免潜在的危险。深度学习模型可以自动学习到人脸图像中与疲劳相关的特征,并在训练过程中优化模型的参数,以最大程度地提高疲劳检测的准确性和鲁棒性。
实现技术思路
一、疲劳检测方法
1.1 人脸检测方法
基于人脸构图比例的方法来判断和识别人脸:
-
人脸构图比例:人类脸部的排列方式是固定的,因此可以使用这种知识来确定哪些信息属于人脸。根据人脸构图比例,可以快速判断一张图片是否包含人脸,以及在人脸照片中通过构图比例快速识别人脸的坐标信息。利用人脸构图比例作为筛选器,可以判断符合构图位置比例的区域是否为人脸。
-
阈值选择:随着研究的深入,确定阈值变得困难。如果阈值过高,很难检测到符合规定的人脸区域,导致无法识别人脸。如果阈值过低,图片中可能存在多个符合规定的区域,增加了误识别的风险。因此,选择合适的阈值对于准确的人脸识别至关重要。
基于人脸构图比例的方法可以用于判断和识别人脸,但阈值的选择需要权衡准确性和误识别率。这需要根据具体的应用场景和需求进行调整。
import cv2
# 加载人脸识别分类器
face_cascade = cv2.CascadeClassifier('path/to/haarcascade_frontalface_default.xml')
# 加载图像
image = cv2.imread('path/to/image.jpg')
# 将图像转换为灰度图像
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 检测人脸
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30))
# 遍历检测到的人脸
for (x, y, w, h) in faces:
# 在原图上绘制人脸框
cv2.rectangle(image, (x, y), (x+w, y+h), (0, 255, 0), 3)
# 显示结果图像
cv2.imshow('Faces', image)
cv2.waitKey(0)
cv2.destroyAllWindows()特征检测方法和统计学习方法在人脸识别中的应用:
-
特征检测方式:特征检测方式是基于已知的人类面部特征信息,通过预设的判断器来找到它们之间的相互关系,并对图像进行识别。目前,人们常用的方法是基于人类肤色特征进行识别。人类皮肤颜色在一定区域内变化不大,因此可以相对容易地区分静态环境和人脸位置信息。
-
肤色检测方法的局限性:然而,肤色检测方法对亮度非常敏感,而驾驶员的驾驶环境通常是室外的,这直接影响了检测的准确性。在实施疲劳监测系统时,必然需要处理光线明暗的问题。
-
统计学习方法:统计学习方法是近年来比较热门的人脸检测方法之一。它是一种基于统计学的人脸检测方法,其基本原理是建立人脸分类器程序,然后通过大量的人脸样本,找到人脸区域的特征数据。由于有大量的原始数据和分析数据支持,这种方法可以非常准确地识别人脸区域。
特征检测方式可以根据已知的人脸特征信息进行识别,其中基于人类肤色特征的方法常被使用。然而,肤色检测方法对光线变化敏感,因此在疲劳监测等特定环境下会面临准确性的挑战。统计学习方法则通过建立分类器和利用大量样本数据来实现准确的人脸识别。
# 创建支持向量机分类器
clf = svm.SVC()
# 训练分类器
clf.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = clf.predict(X_test)
# 计算准确率
accuracy = np.mean(y_pred == y_test)
print("Accuracy:", accuracy)1.2 人眼检测方法
基本的人眼定位方法:灰度投影法和Hough变换法。
-
灰度投影法:该方法通过采集图像并计算每张图片的相似度,然后进行投影处理,最终根据阈值分割或边缘检测来定位和提取人眼及其参数。灰度投影法执行速度快,但对采集图片的环境光线要求较高,导致人眼定位的准确率较低。
-
Hough变换法:该方法也是通过对采集的素材进行相似度计算,但后续主要通过边缘提取的方法,在图像中比对区域来找到人眼坐标。然而,Hough变换法的计算量较大,不容易实现实时的人眼定位。
总结起来,灰度投影法执行速度快但准确率低,而Hough变换法准确率较高但计算量大且不易实时应用。选择适合的人眼定位方法需要考虑准确率、计算效率和实时性等因素。
代码示例如下:
import cv2
import numpy as np
# 读取图像
image = cv2.imread("input_image.jpg")
# 将图像转换为灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 边缘检测
edges = cv2.Canny(gray, 50, 150)
# 进行Hough变换
circles = cv2.HoughCircles(edges, cv2.HOUGH_GRADIENT, dp=1, minDist=100, param1=50, param2=30, minRadius=10, maxRadius=50)
if circles is not None:
# 将检测到的圆形标记出来
circles = np.round(circles[0, :]).astype("int")
for (x, y, r) in circles:
cv2.circle(image, (x, y), r, (0, 255, 0), 2)
# 显示结果
cv2.imshow("Eye Detection", image)
cv2.waitKey(0)
cv2.destroyAllWindows()二、 数据集
由于网络上没有现有的合适的数据集,我决定自己进行实地拍摄,收集照片并创建一个全新的数据集,专注于疲劳监测系统的研究。这个数据集包含了不同工作场景下的照片,涵盖了各种职业和工作环境,以及人们在工作过程中的表情和姿势。在这个自制的数据集中,我着重关注工作者的面部表情、眼部活动以及姿势变化等特征,以便有效监测和识别疲劳状态。通过收集大量的样本图片,我可以构建一个全面且有代表性的数据集,涵盖不同工作强度和疲劳程度的情况。

数据增光和数据扩充是在机器学习和深度学习中常用的技术,用于增加训练数据的数量和多样性。数据增光通过对原始数据进行随机变换和扰动来生成新的样本,而数据扩充则通过引入外部数据源来丰富训练数据。这些技术的目的是提供更多、更丰富的训练样本,使模型具备更好的泛化能力和鲁棒性,从而改善模型的性能和减轻过拟合问题。然而,需要合理使用这些技术,并根据任务和数据特点选择适当的增光和扩充方式,以确保生成的数据对于训练模型是有益的。
相关代码示例:
import numpy as np
from PIL import Image
import torchvision.transforms as transforms
# 图像旋转和翻转
def image_augmentation(image_path):
image = Image.open(image_path)
# 旋转图像
rotated_image = image.rotate(45) # 以45度角旋转图像
# 水平翻转图像
flipped_image = image.transpose(Image.FLIP_LEFT_RIGHT)
# 垂直翻转图像
flipped_image_updown = image.transpose(Image.FLIP_TOP_BOTTOM)
# 显示增光后的图像
image.show()
rotated_image.show()
flipped_image.show()
flipped_image_updown.show()
# 图像缩放和裁剪
def image_resizing(image_path):
image = Image.open(image_path)
# 缩放图像
resized_image = image.resize((256, 256)) # 将图像大小调整为256x256像素
# 裁剪图像
cropped_image = image.crop((100, 100, 400, 400)) # 从图像中裁剪出100x100到400x400像素的区域
# 显示增光后的图像
image.show()
resized_image.show()
cropped_image.show()
# 图像亮度和对比度调整
def image_brightness_contrast(image_path):
image = Image.open(image_path)
# 调整图像亮度
brightness_adjusted_image = transforms.functional.adjust_brightness(image, 0.2) # 将亮度降低20%
# 调整图像对比度
contrast_adjusted_image = transforms.functional.adjust_contrast(image, 1.5) # 将对比度增加50%
# 显示增光后的图像
image.show()
brightness_adjusted_image.show()
contrast_adjusted_image.show()
# 添加高斯噪声
def add_gaussian_noise(image_path, mean, std):
image = Image.open(image_path)
np_image = np.array(image)
# 添加高斯噪声
noise = np.random.normal(mean, std, np_image.shape).astype(np.uint8)
noisy_image = np.clip(np_image + noise, 0, 255)
noisy_image = Image.fromarray(noisy_image)
# 显示增光后的图像
image.show()
noisy_image.show()
# 示例用法
image_augmentation("image.jpg")
image_resizing("image.jpg")
image_brightness_contrast("image.jpg")
add_gaussian_noise("image.jpg", 0, 20)三、实验及结果分析
3.1 实验环境搭建
在桌面端已经实现了疲劳检测系统的基本功能。从图片输入,人脸检测, 数据验证,输出结果已经完成了一个程序该有的闭环功能。

3.2 一阶段数据分析
本阶段实验数据为300张人脸照片,测试程序对人脸识别和关键点数据的采集。先分析一张标准正面人脸,在分析正面情况的时候,使用了一张纯色背景,非常干净的正面图来做测试,以检验在理想状态下程序识别的情况。

图像识别的也非常理想,人脸和人眼的关键点定位的非常准确。根据此关键点坐标,建立直角坐标系,把坐标点输入微软Excel软件。 网页使用的坐标系并非常用的零点在左下的直角坐标系,而是使用的零点在左上的直角坐标系,因此需要对原有坐标系坐标进行简单变换得到。


侧面的情况的时候,程序可以正确识别人脸,对画面中出现的人眼给予正确定位,这个时候关键点的定位已经不准确了,只能给出大概位置和一个不是很正确的轮廓参数,并且另外一个眼睛关键点的定位坐标位置也是错误的(因为另外一个眼睛根本没有露出),但是从图像看出,这个定位点是系统按照面部倾角给出了假设值。因此可以确认侧面进行疲劳监测基本无法准确测量。


3.2 二阶段数据分析
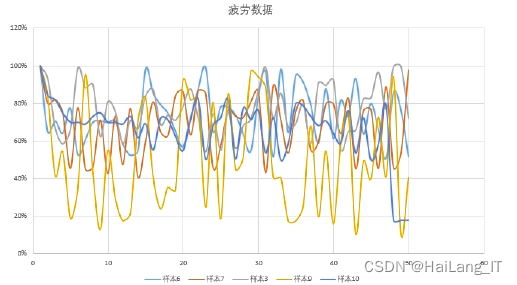
第二阶段数据以个体实验者,多次试验数据作为样本进行分析。 先以三张个体眼睛睁开程度不一样的数据作为基础样本。通过变化人眼坐标得到下列数据:

建立坐标系:

此时散点图与系统给到的关键点标记图一致。通过计算left_eye_top和left_eye_bottom两点之间的距离,按照最大值为基础值,其他时间长度和该值的比例即可判定是否符合P80标准。 P80模式识别成功率为99%。P70识别成功率为61%。并且P80模式在检测自认为清醒的样本数据成功率是P70模式的700%。而P70模式失误率高达 39%。P80的数据t检验p值小于0.05符合统计学原理,P80标准确实更加符合疲劳 监测系统的标准。


相关代码示例:
# 加载训练好的深度学习模型
model = Sequential()
# 添加卷积层和池化层
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
# 添加全连接层
model.add(Dense(64, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 加载人脸图像数据和标签
data = np.load('path/to/data.npy')
labels = np.load('path/to/labels.npy')
# 将数据归一化为0到1之间的范围
data = data.astype('float32') / 255.0
# 将数据分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, random_state=42)
# 训练模型
model.fit(X_train, y_train, epochs=10, batch_size=32, validation_data=(X_test, y_test))
# 在测试集上评估模型
loss, accuracy = model.evaluate(X_test, y_test)
print("Loss:", loss)
print("Accuracy:", accuracy)最后
我是海浪学长,创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 17
17 0
0- 0



 已为社区贡献75条内容
已为社区贡献75条内容

所有评论(0)