也谈人工智能--AI科普入门
人工智能(Artificial intelligence,AI),指由人制造出来的机器所表现出来的智能。通常人工智能是指通过普通计算机程序来呈现人类智能的技术,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。人工智能是一个构建能够推理、学习和行动的计算机和机器的科学领域,这种推理、学习和行动通常需要人类智力,或者涉及超出人类分析能力的数据规模。AI 是一个广博的领域,涵盖许多
1. 科普入门
- 入门参考资料:
人工智能的定义
人工智能(Artificial intelligence,AI),指由人制造出来的机器所表现出来的智能。通常人工智能是指通过普通计算机程序来呈现人类智能的技术,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。
人工智能是一个构建能够推理、学习和行动的计算机和机器的科学领域,这种推理、学习和行动通常需要人类智力,或者涉及超出人类分析能力的数据规模。
AI 是一个广博的领域,涵盖许多不同的学科,包括计算机科学、数据分析和统计、硬件和软件工程、语言学、神经学,甚至哲学和心理学。
在业务使用的操作层面上,AI 是一组主要基于机器学习和深度学习的技术,用于数据分析、预测、对象分类、自然语言处理、推荐、智能数据检索等等。
概况来说,人工智能利用计算机和机器,模仿人类思维的问题解决和决策制定能力。
人工智能的类型 - 弱 AI 与强 AI
弱 AI 也称为狭义 AI 或人工狭义智能 (ANI),是专注于执行特定任务的经过训练的 AI。 弱 AI 驱动了我们现在使用的大多数 AI。 “狭窄”可能是对这类 AI 更准确的描述,因为它一点也不弱;它支持一些非常强大的应用,如 Apple Siri、Amazon Alexa、IBM Watson 自动驾驶汽车。
强 AI 由人工常规智能 (AGI) 和人工超级智能 (ASI) 组成。 人工常规智能 (AGI) 是 AI 的一种理论形式,机器拥有与人类等同的智能;它具有自我意识,能够解决问题、学习和规划未来。 人工超级智能 (ASI) 也称为超级智能,将超越人类大脑的智力和能力。 虽然强 AI 仍完全处于理论阶段,还没有实际应用的例子,但这并不意味着 AI 研究人员不再探索它的发展。 与此同时,ASI 的最佳例子可能来自科幻小说中的人物,如 HAL、超人以及 《2001 太空漫游》中的无赖电脑助手。
人工智能、深度学习与机器学习
由于深度学习和机器学习这两个术语往往可互换使用,因此必须注两者之间的细微差别。 如上所述,深度学习和机器学习都是人工智能的子领域,深度学习实际上是机器学习的一个子领域。
深度学习实际上是由神经网络组成的。 深度学习中的“深度”指的是由三层以上的神经网络组成,包括输入和输出,可以被认为是一种深度学习算法。
深度学习和机器学习的不同之处在于每个算法的学习方式。 深度学习可以自动执行过程中的大部分特征提取,消除某些必需的人工干预,并能够使用更大的数据集。 您可将深度学习视为“可扩展的机器学习”,正如 Lex Fridman 在麻省理工学院的同一次讲座中提到的那样。 经典的或“非深度”的机器学习更依赖于人类的干预进行学习。 人类专家确定特征的层次结构,以了解数据输入之间的差异,通常需要更多结构化数据以用于学习。
"深度"机器学习则可以利用标签化数据集,也称为监督式学习,来确定算法,但不一定必须使用标签化数据集。 它可以原始格式(例如文本、图像)采集非结构化数据,并且可以自动确定区分不同类别数据的特征的层次结构。 与机器学习不同,它不需要人工干预数据的处理,使我们能够以更有趣的方式扩展机器学习。
人工智能的应用和使用场景
语音识别
也称为自动语音识别 (ASR)、计算机语音识别或语音到文本,能够使用自然语言处理 (NLP) 将人类语音转变为书面格式。 许多移动设备 — 如 Siri — 都在其系统中纳入了语音识别功能,以进行语音搜索,或者提供更方便的短信服务。
计算机视觉
该 AI 技术使计算机和系统能够从数字图像、视频和其他可视输入中获取有意义的信息,并基于这些输入采取行动。 这种提供建议的能力将其与图像识别任务区分开来。 计算机视觉由卷积神经网络提供支持,应用在社交媒体的照片标记、医疗保健中的放射成像以及汽车工业中的自动驾驶汽车等领域。
客户服务
在线虚拟客服正在取代工人客服为客户服务。 他们回答各种主题的常见问题 (FAQ) ,例如送货,或为用户提供个性化建议,交叉销售产品,提供用户尺寸建议,改变了我们对网站和社交媒体中客户互动的看法。 示例包括具有 虚拟客服的电子商务站点上的聊天机器人、消息传递应用(例如 Slack 和 Facebook Messenger)以及虚拟助理和 语音 手通常执行的任务。
建议引擎
AI 算法使用过去的消费行为数据,帮助发现可用于制定更有效的交叉销售策略的数据趋势。 这用于在在线零售商的结账流程中向客户提供相关的附加建议。
数据分析
针对商业智能寻找数据中的模式和关系。
网络安全
独立自主扫描网络以检测是否存在网络攻击和威胁。
行业应用
- 医疗行业
- 智慧诊疗
- 智慧医学影像
- 智慧健康管理
- 教育行业
- 远程教育AI辅助
- 行为检测
- 场景识别
- 线上监考
- 远程教育AI辅助
- 交通行业
- 交通工具智慧化
- 出行方式智慧化
- 道路管理智慧化
- 物流行业
- 智能仓储
- 商品自动储存
- 拣选
- 分选
- 智能仓储
- 制造行业
- 产品智能化研究设计
- 智慧质检
- 生成设备预测性维护
- ……
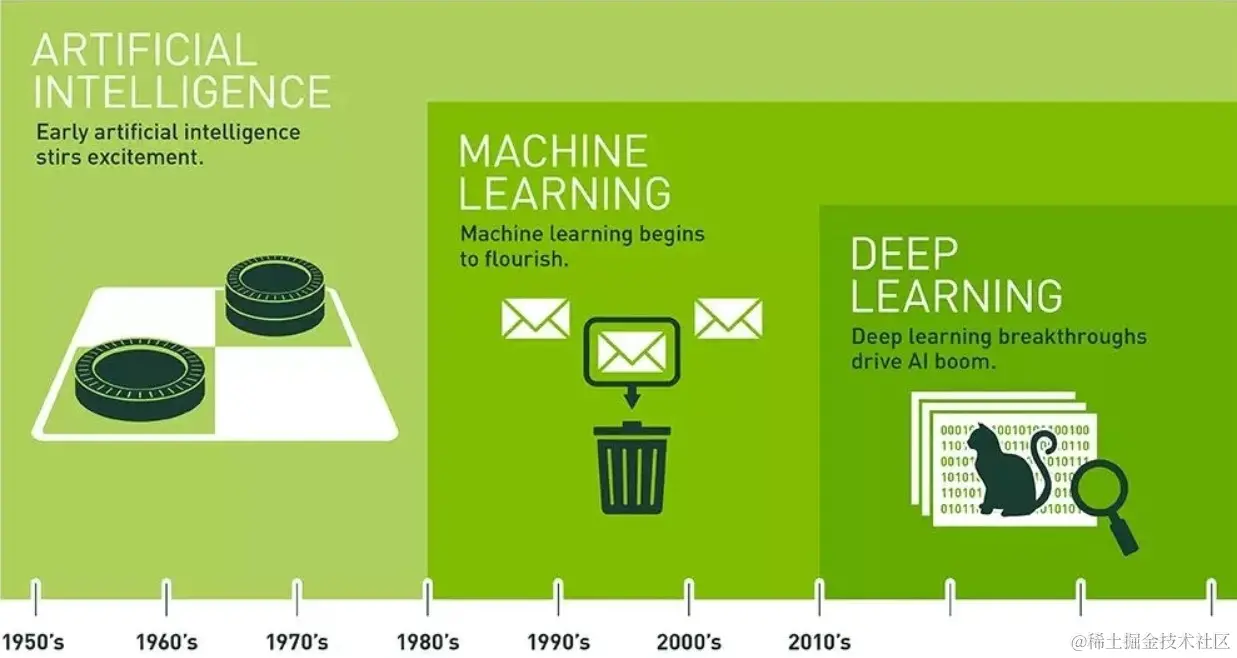
人工智能发展史
- 1950 年:阿兰图灵发表了*“计算机器与智能”。* 在这篇文章中,因在二战期间破译纳粹 ENIGMA 密码而闻名的图灵,提议回答 “机器能思考吗?”这一问题 并介绍了图灵测试,用于确定计算机能否展示出与人类相同的智慧(或相同智慧产生的结果)。 自此之后,人们就图灵测试的价值一直争论不休。
- 1956 年:John McCarthy 在达特茅斯学院人工智能会议上创造了“人工智能”(AI) 一词,这是人工智能诞生的标志。 (McCarthy 后来又发明了 Lisp语言。) 同年晚些时候,Allen Newell、J.C. Shaw 和 Herbert Simon 创建了有史以来第一个运行 AI 软件程序的机器 “Herbert Simon”。
- 1967 年: Frank Rosenblatt 构建了 Mark 1 Perceptron,这是第一台基于神经网络的计算机,它可以通过试错法不断学习。 就在一年后,Marvin Minsky 和 Seymour Papert 出版了一本名为 《感知器》(Perceptrons) 的书籍,这本书既成为神经网络领域的标志性作品,同时至少在一段时间内,也是反对未来神经网络研究项目的论据。
- 20 世纪 80 年代: 使用反向传播算法训练自己的神经网络在 AI 应用中广泛使用。
- 1997 年: IBM 的深蓝计算机在国际象棋比赛(和复赛)中击败国际象棋世界冠军 Garry Kasparov。
- 2011 年: IBM Watson 在《Jeopardy!》挑战赛中击败了 Ken Jennings 和 Brad Rutter。
- 2015 年: 百度的 Minwa 超级计算机使用一种称为卷积神经网络的特殊深度神经网络来识别图像并进行分类,其准确率高于一般的人类。
- 2016 年: 由深度神经网络支持的 DeepMind 的 AlphaGo 程序在五轮比赛中击败了围棋世界冠军 Lee Sodol。 考虑到随着游戏的进行,可能的走法非常之多,这一胜利具有重要意义(仅走了四步之后走法就超过 14.5 万亿种!)。 后来,谷歌以四亿美元的报价收购了 DeepMind。
自诞生至今已有60多年发展历史,目前处于爆发期,经历过两次寒冬期
- 第一次因为算力不足
- 第二次因为硬件市场崩溃、资金不足、研究迷茫

产业结构层级
- 基础层
- 数据服务
- 通用数据
- 来源:开源数据集平台
- 面向对象:大众
- 是否支持分享:支持,对外开放
- 行业数据
- 来源:各行业企业的内部系统
- 面向对象:企业内部
- 是否支持分享:不支持,不对外开放
- 通用数据
- 软件设施
- 云计算平台
- 大数据平台
- 硬件设施
- 芯片(算力支持)
- 传感器(数据采集)
- 数据服务
- 技术层
- 开发框架
- TensorFlow
- PyTorch
- Coffe
- Keras
- ……
- 算法模型
- 机器学习模型:实现人工智能的重要手段
- 深度学习模型:图像、文本、声音等高维度复杂数据处理
- 通用技术
- 计算机视觉
- 自然语言处理
- 智能语音
- 知识图谱
- 开发框架
- 应用层
- 人工智能产品
- 智能音箱
- 自动驾驶汽车
- 智能机器人
- 人脸支付
- ……
- 人工智能应用场景:上述1.4和1.5节内容
- 人工智能产品

系统架构
典型的AI系统架构图如下:

后续针对该部分单独介绍,此处不做赘述。
人工智能标准体系
人工智能标准化白皮书(2021版).pdf (第64页开始有部分案例介绍)

2. 细分领域
- 计算框架
- chatGPT引爆AIGC
【AIGC算力时代系列报告】:ChatGPT研究框架-230214.pdf
火出圈的典型: chatGPT
| 参数数量 | 训练数据 | |
|---|---|---|
| GPT-1 | 1.2亿 | BookCorpus[8]:是一个包含7000本未出版书籍的语料库,总大小为4.5 GB。这些书籍涵盖了各种不同的文学流派和主题。 |
| GPT-2 | 15亿 | WebText:一个包含八百万个文档的语料库,总大小为40 GB。这些文本是从Reddit上投票最高的4,500万个网页中收集的,包括各种主题和来源,例如新闻、论坛、博客、维基百科和社交媒体等。 |
| GPT-3 | 1750亿 | 一个总大小为570 GB的大规模文本语料库,其中包含约四千亿个标记。这些数据主要来自于CommonCrawl、WebText、英文维基百科和两个书籍语料库(Books1和Books2)。 |
如何快速体验chatGPT:微软新必应浏览器
- AI生产过程管理面临的问题


开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 36
36 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)