Langchain-Chatchat+Qwen实现本地知识库
Langchain-Chatchat一种利用langchain思想实现的基于本地知识库的问答应用,目标期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案。大致过程包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的top k个 -> 匹配出的文本作为上下文和问题一起添加到prompt中 -> 提交给LLM
1.基础介绍
Langchain-Chatchat一种利用 langchain 思想实现的基于本地知识库的问答应用,目标期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案。大致过程包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的 top k个 -> 匹配出的文本作为上下文和问题一起添加到 prompt中 -> 提交给 LLM生成回答。
Qwen-7B(14B)是阿里云研发的通义千问大模型系列的70(140)亿参数规模的模型。是基于Transformer的大语言模型, 在超大规模的预训练数据上进行训练得到。预训练数据类型多样,覆盖广泛,包括大量网络文本、专业书籍、代码等。同时,在此的基础上,使用对齐机制打造了基于大语言模型的AI助手Qwen-7(14)B-Chat。
接下来就让我们结合Langchain-Chatchat+Qwen-7B(14B),一步一步的搭建一个属于自己的本地知识库吧~
2.前期准备:
python:3.10+,torch 推荐使用 2.0 及以上的版本。gpu如果使用Qwen-7b 和Qwen-14b-int4需要大概24g显存,使用Qwen-14b需要40g左右显存。
3.环境搭建:
先拉取Langchain-Chatchat的项目代码
git clone https://github.com/chatchat-space/Langchain-Chatchat.git
安装依赖
pip install -r requirements.txt
pip install -r requirements_api.txt
pip install -r requirements_webui.txt
4.模型下载:
模型主要分两块,一个是llm模型,另一个是Embedding 模型,支持的Embedding 模型有以下这些:
"ernie-tiny": "nghuyong/ernie-3.0-nano-zh",
"ernie-base": "nghuyong/ernie-3.0-base-zh",
"text2vec-base": "shibing624/text2vec-base-chinese",
"text2vec": "GanymedeNil/text2vec-large-chinese",
"text2vec-paraphrase": "shibing624/text2vec-base-chinese-paraphrase",
"text2vec-sentence": "shibing624/text2vec-base-chinese-sentence",
"text2vec-multilingual": "shibing624/text2vec-base-multilingual",
"text2vec-bge-large-chinese": "shibing624/text2vec-bge-large-chinese",
"m3e-small": "moka-ai/m3e-small",
"m3e-base": "moka-ai/m3e-base",
"m3e-large": "moka-ai/m3e-large",
"bge-small-zh": "BAAI/bge-small-zh",
"bge-base-zh": "BAAI/bge-base-zh",
"bge-large-zh": "BAAI/bge-large-zh",
"bge-large-zh-noinstruct": "BAAI/bge-large-zh-noinstruct",
"bge-base-zh-v1.5": "BAAI/bge-base-zh-v1.5",
"bge-large-zh-v1.5": "/root/autodl-tmp/bge-large-zh-v1.5",
"piccolo-base-zh": "sensenova/piccolo-base-zh",
"piccolo-large-zh": "sensenova/piccolo-large-zh",
"nlp_gte_sentence-embedding_chinese-large": "damo/nlp_gte_sentence-embedding_chinese-large",
"text-embedding-ada-002": "your OPENAI_API_KEY",
},
个人推荐使用bge-large-zh-v1.5
git clone https://www.modelscope.cn/Xorbits/bge-large-zh-v1.5.git
langchain-chatchat v0.28版本增加了很多llm模型的支持,具体如下:
# 以下部分模型并未完全测试,仅根据fastchat和vllm模型的模型列表推定支持
"chatglm2-6b": "THUDM/chatglm2-6b",
"chatglm2-6b-32k": "THUDM/chatglm2-6b-32k",
"chatglm3-6b": "THUDM/chatglm3-6b",
"chatglm3-6b-32k": "THUDM/chatglm3-6b-32k",
"chatglm3-6b-base": "THUDM/chatglm3-6b-base",
"Qwen-1_8B": "Qwen/Qwen-1_8B",
"Qwen-1_8B-Chat": "Qwen/Qwen-1_8B-Chat",
"Qwen-1_8B-Chat-Int8": "Qwen/Qwen-1_8B-Chat-Int8",
"Qwen-1_8B-Chat-Int4": "Qwen/Qwen-1_8B-Chat-Int4",
"Qwen-7B": "Qwen/Qwen-7B",
"Qwen-14B": "Qwen/Qwen-14B",
"Qwen-7B-Chat": "/root/autodl-tmp/Qwen-7B-Chat",
"Qwen-14B-Chat": "/root/autodl-tmp/Qwen-14B-Chat",
"Qwen-14B-Chat-Int8": "Qwen/Qwen-14B-Chat-Int8", # 确保已经安装了auto-gptq optimum flash-attn
"Qwen-14B-Chat-Int4": "/root/autodl-tmp/Qwen-14B-Chat-Int4",# 确保已经安装了auto-gptq optimum flash-attn
"Qwen-72B": "Qwen/Qwen-72B",
"Qwen-72B-Chat": "Qwen/Qwen-72B-Chat",
"Qwen-72B-Chat-Int8": "Qwen/Qwen-72B-Chat-Int8",
"Qwen-72B-Chat-Int4": "Qwen/Qwen-72B-Chat-Int4",
"baichuan2-13b": "baichuan-inc/Baichuan2-13B-Chat",
"baichuan2-7b": "baichuan-inc/Baichuan2-7B-Chat",
"baichuan-7b": "baichuan-inc/Baichuan-7B",
"baichuan-13b": "baichuan-inc/Baichuan-13B",
"baichuan-13b-chat": "baichuan-inc/Baichuan-13B-Chat",
"aquila-7b": "BAAI/Aquila-7B",
"aquilachat-7b": "BAAI/AquilaChat-7B",
"internlm-7b": "internlm/internlm-7b",
"internlm-chat-7b": "internlm/internlm-chat-7b",
"falcon-7b": "tiiuae/falcon-7b",
"falcon-40b": "tiiuae/falcon-40b",
"falcon-rw-7b": "tiiuae/falcon-rw-7b",
"gpt2": "gpt2",
"gpt2-xl": "gpt2-xl",
"gpt-j-6b": "EleutherAI/gpt-j-6b",
"gpt4all-j": "nomic-ai/gpt4all-j",
"gpt-neox-20b": "EleutherAI/gpt-neox-20b",
"pythia-12b": "EleutherAI/pythia-12b",
"oasst-sft-4-pythia-12b-epoch-3.5": "OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5",
"dolly-v2-12b": "databricks/dolly-v2-12b",
"stablelm-tuned-alpha-7b": "stabilityai/stablelm-tuned-alpha-7b",
"Llama-2-13b-hf": "meta-llama/Llama-2-13b-hf",
"Llama-2-70b-hf": "meta-llama/Llama-2-70b-hf",
"open_llama_13b": "openlm-research/open_llama_13b",
"vicuna-13b-v1.3": "lmsys/vicuna-13b-v1.3",
"koala": "young-geng/koala",
"mpt-7b": "mosaicml/mpt-7b",
"mpt-7b-storywriter": "mosaicml/mpt-7b-storywriter",
"mpt-30b": "mosaicml/mpt-30b",
"opt-66b": "facebook/opt-66b",
"opt-iml-max-30b": "facebook/opt-iml-max-30b",
"agentlm-7b": "THUDM/agentlm-7b",
"agentlm-13b": "THUDM/agentlm-13b",
"agentlm-70b": "THUDM/agentlm-70b",
"Yi-34B-Chat": "https://huggingface.co/01-ai/Yi-34B-Chat",
},
我们本次选用Qwen-7B-Chat,Qwen-14B-Chat及Qwen-14B-Chat-Int4,注意7b和14b-int4大概需要预留30g硬盘空间,14b需要50g硬盘空间
git clone https://www.modelscope.cn/qwen/Qwen-7B-Chat.git
git clone https://www.modelscope.cn/qwen/Qwen-14B-Chat-Int4.git
git clone https://www.modelscope.cn/qwen/Qwen-14B-Chat.git
14b-int4需要确保已经安装了flash-attn库
git clone https://github.com/Dao-AILab/flash-attention cd flash-attention && pip install .
pip install csrc/layer_norm
pip install csrc/rotary
如果flash-attn在安装过程中出现卡顿,可以手动安装需要的组件库
pip install auto-gptq --extra-index-url /autogptq-index/whl/cu120/
5.初始化知识库和配置文件:
python copy_config_example.py
python init_database.py --recreate-vs
打开/configss/model-config.py,修改配置信息及模型路径
EMBEDDING_MODEL = "bge-large-zh-v1.5"
LLM_MODELS = ["Qwen-14B-Chat", "zhipu-api", "openai-api"]
打开14b-int4模型所在文件夹的config.json,在quantization_config下添加 “disable_exllama”: true
"quantization_config": {
"bits": 4,
"group_size": 128,
"damp_percent": 0.01,
"desc_act": false,
"static_groups": false,
"sym": true,
"true_sequential": true,
"model_name_or_path": null,
"model_file_base_name": "model",
"disable_exllama": true,
"quant_method": "gptq"
},
6.项目启动:
6.1 api启动
python server/api.py
启动完成可以通过相应的端口查看api文档
6.2 webui启动
请先确保api已经在运行中
streamlit run webui.py --server.port 6006
6.3 一键启动
python startup.py -a
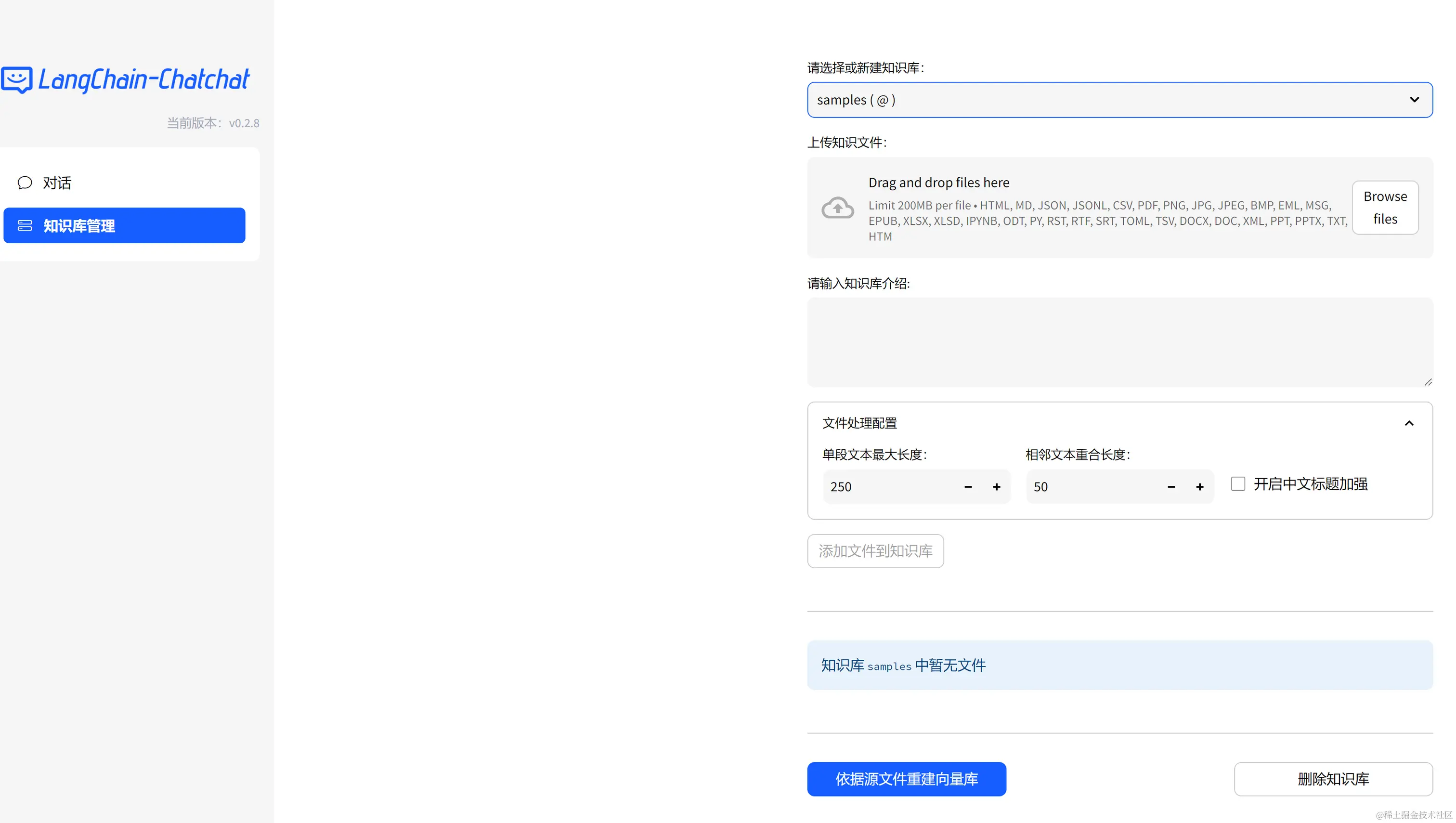
7.创建知识库:
启动以后点击知识库,支持的知识文件如下
 创建一个自己的知识csv文件,可以采用一问一答的形式
创建一个自己的知识csv文件,可以采用一问一答的形式
 导入保存
导入保存
8.大功告成,验证结果吧:
首先是不使用知识库的情况:  qwen7b+知识库:
qwen7b+知识库:  qwen14b+知识库:
qwen14b+知识库:  可以看到知识库可以在处理知识库范围之内的内容的同时,保证其他对话正常进行。 14b与7b的性能差异如下
可以看到知识库可以在处理知识库范围之内的内容的同时,保证其他对话正常进行。 14b与7b的性能差异如下 
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。
本文转自 https://blog.csdn.net/kaka0722ww/article/details/141889769?spm=1001.2014.3001.5501,如有侵权,请联系删除。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 20
20 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)