【毕业设计】基于GAN的照片动漫图像生成系统 深度学习 人工智能
毕业设计:基于GAN的照片动漫图像生成系统利用生成对抗网络(GAN)技术实现了从真实照片到动漫图像的转换。通过深度学习和计算机视觉技术的结合,该系统能够生成具有各种艺术风格的动漫图像,为用户提供了一个全新且富有创意的图像生成体验。本文研究为计算机毕业设计提供了一个创新的方向,结合了深度学习和计算机视觉技术,为毕业生提供了一个有意义的研究课题。对于计算机专业、软件工程专业、人工智能专业、大数据专业的
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于GAN的照片动漫图像生成系统
设计思路
一、课题背景与意义
随着深度学习和计算机视觉技术的快速发展,图像生成成为一个备受关注的研究领域。在此背景下,照片动漫图像生成系统成为了一个具有挑战性和创新性的研究课题。该系统能够将真实照片转换为富有艺术风格的动漫图像,为用户提供了一种全新的图像表达方式。
二、算法理论原理
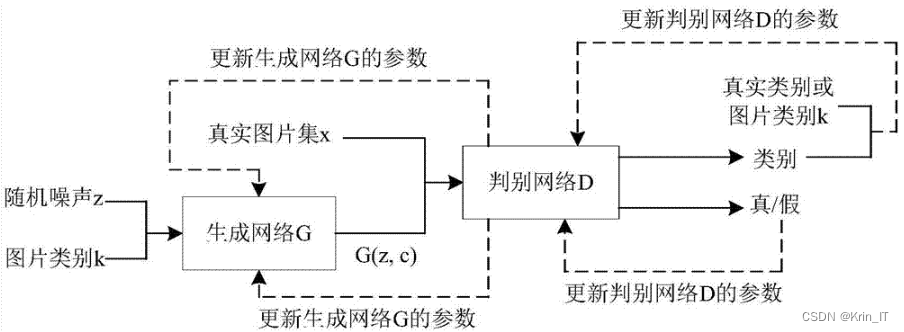
2.1 生成对抗网络
生成对抗网络(GAN)是一种深度学习模型,由生成器(Generator)和判别器(Discriminator)组成。它们通过对抗的方式相互训练,使生成器能够生成逼真的数据样本,而判别器则能够准确地区分生成的样本和真实样本。GAN在照片生成方面具有广泛的应用和优势。
GAN在照片生成系统中的应用非常丰富。它可以用于图像修复,将损坏或缺失的部分恢复到原始图像中。它还可以用于图像转换,将照片转化为艺术风格或动漫风格的图像,增加了图像的趣味性和创造性。此外,GAN还可以用于图像合成,生成新的图像样本,如虚拟角色、景观等。GAN在照片生成系统中的优势也是显著的。与传统的基于规则的图像生成方法相比,GAN能够从大量真实图像中学习到数据的分布特征,生成更加逼真和多样化的图像。它能够捕捉到图像中的高级语义信息,生成更具艺术性和创造性的图像结果。此外,GAN还能够通过调整生成器和判别器的训练策略,实现对生成结果的精细控制。

GAN的算法介绍如下:生成器通过输入一个随机噪声向量,经过一系列的卷积和反卷积操作,逐渐生成逼真的图像。判别器则接收生成器生成的图像和真实图像,并对其进行分类,判断其真实性。生成器和判别器相互博弈,通过对抗训练的方式不断优化自身,最终使生成器能够生成越来越逼真的图像,而判别器也能够更准确地区分真实和生成的图像。

神经风格迁移和生成对抗网络(GAN)是两种强大的图像处理技术,它们在图像生成和转换方面都具有重要的应用。将神经风格迁移和GAN结合起来,可以进一步提升图像生成的质量和多样性。神经风格迁移是一种技术,通过将一幅图像的风格与另一幅图像的内容进行融合,生成具有新风格的图像。它基于深度学习模型,如卷积神经网络(CNN),通过将图像的内容特征和风格特征进行分离和重组,实现图像的风格迁移。神经风格迁移可以实现将一幅图像的艺术风格应用到另一幅图像上,生成具有艺术风格的新图像。

将神经风格迁移和GAN结合起来,可以获得更加强大的图像生成和转换能力。一种常见的方法是使用GAN作为神经风格迁移的优化器,通过对抗训练的方式进一步提升生成的图像质量。生成器可以通过对抗训练来生成更逼真的图像样本,而判别器可以帮助生成器更好地捕捉风格特征和细节。这种组合方法可以在保持图像内容一致的同时,生成具有更丰富风格的图像。
2.2 图像动漫化
采用神经风格迁移和生成对抗网络(GAN)的组合的模型,用于实现照片到动漫图像的转换。相比于CartoonGAN,AnimeGAN的模型更小、计算量更小,并具有更快的记忆推理速度。为了提升动漫风格化的视觉效果,AnimeGAN提出了三个全新的损失函数:灰度风格损失、灰度对抗损失和颜色重建损失。
这三个损失函数在AnimeGAN中的应用具有重要意义。灰度风格损失用于捕捉图像的灰度风格特征,帮助生成器更好地迁移动漫风格。灰度对抗损失通过对抗训练的方式,使生成的图像在灰度上能够更好地伪装成动漫图像,增强了图像的整体一致性。颜色重建损失用于保持原始图像的颜色信息,确保生成的图像在风格迁移的同时能够保留原始照片的色彩特征。
这些全新的损失函数的引入使得AnimeGAN能够生成更具有动漫风格的图像,并提升了图像转换的质量和效果。同时,AnimeGAN的模型更小且计算量更小,使其在实际应用中具有更高的实时性和效率。通过这种方式,AnimeGAN在动漫图像生成领域取得了显著的进展,并为照片到动漫图像的转换提供了一种更加高效、高质量的解决方案。
三、检测的实现
3.1 数据集
由于网络上没有现有的合适的数据集,本研究决定自己进行网络爬取,收集了大量真实照片和对应的动漫图像,构建了一个全新的数据集。这个数据集包含了各种场景、主题和风格的照片和对应的动漫图像,涵盖了不同的内容和视觉特征。数据扩充通过应用图像处理技术和数据增强方法,例如旋转、缩放、裁剪和颜色变换等,将原始数据集进行扩充,生成了更丰富、更具变化性的数据样本。数据扩充能够增加模型的泛化能力,提高生成的动漫图像的质量和多样性。
3.2 实验环境搭建
实验环境使用Windows操作系统,并利用Python作为主要的编程语言进行算法和模型的实现。使用PyTorch作为深度学习框架,构建和训练神经网络模型。借助Pandas等库,完成数据的加载、处理和转换。这样的实验环境提供了一个方便和高效的平台,用于开发和测试算法系统。
3.3 实验及结果分析
训练过程中,采用了对风格图片进行预处理的步骤。这包括对动漫图片进行边缘平滑处理,使用OpenCV的Canny算法进行边缘检测,并应用高斯滤波对图像进行降噪,以达到图像平滑的效果。Canny算法的主要步骤如下:
- 噪声抑制:首先,对输入图像进行高斯滤波,以平滑图像并减少噪声的影响。高斯滤波有助于去除图像中的高频噪声,使得后续的边缘检测更加稳定可靠。
- 计算梯度:在平滑后的图像上,使用Sobel算子计算图像的梯度。通过计算图像中每个像素点的梯度幅值和梯度方向,可以得到图像的边缘强度和方向信息。
- 非极大值抑制:在梯度图像上执行非极大值抑制,以细化边缘。对于梯度图像中的每个像素点,检查其梯度方向上的两个邻近像素点,如果当前像素点的梯度幅值最大,那么该像素点被保留,否则被抑制。
- 双阈值处理:使用双阈值处理来确定真正的边缘。将梯度图像中的像素点分为强边缘、弱边缘和非边缘三个类别。如果像素点的梯度幅值高于高阈值,被认为是强边缘;如果梯度幅值介于高阈值和低阈值之间,被认为是弱边缘;如果梯度幅值低于低阈值,被认为是非边缘。通常,高阈值和低阈值的选择是根据经验和应用需求来确定。
- 边缘连接:最后,通过连接强边缘和与之相连的弱边缘来形成完整的边缘。连接过程中,只要与强边缘相连的弱边缘也被认为是边缘,并递归地进行连接,直到没有新的弱边缘与强边缘相连为止。

边缘平滑处理的目的是消除非边缘像素,同时保留一些细微的线条,同时减少图像的数据规模,从而减轻模型训练和推理的计算负担,提高处理速度和效率。在经过边缘检测后,还进行了膨胀操作,扩展边缘线条,使其更连续和明显,增强图像的边缘特征。
通过这些预处理步骤,能够改善模型的训练效果和速度。边缘平滑处理和膨胀操作使输入图像具有更清晰和鲜明的边缘特征,有助于模型更好地学习和捕捉动漫风格的细节。同时,减少图像的数据规模也减轻了模型的计算负担,提高了训练和推理的效率。
相关代码示例:
class StyleLoss(nn.Module):
def __init__(self):
super(StyleLoss, self).__init__()
self.criterion = nn.MSELoss()
def forward(self, input, target):
input_mean = torch.mean(input, (2, 3), keepdim=True)
target_mean = torch.mean(target, (2, 3), keepdim=True)
input_std = torch.std(input, (2, 3), keepdim=True)
target_std = torch.std(target, (2, 3), keepdim=True)
normalized_input = (input - input_mean) / input_std
normalized_target = (target - target_mean) / target_std
return self.criterion(normalized_input, normalized_target)
# 定义训练函数
def train(model_G, model_D, dataloader, num_epochs, style_weight):
criterion = nn.BCELoss()
style_loss = StyleLoss()
optimizer_G = optim.Adam(model_G.parameters(), lr=0.001)
optimizer_D = optim.Adam(model_D.parameters(), lr=0.001)
Tensor = torch.cuda.FloatTensor if torch.cuda.is_available() else torch.FloatTensor
for epoch in range(num_epochs):
for i, (imgs, _) in enumerate(dataloader):
imgs = Variable(imgs.type(Tensor))
real_labels = Variable(Tensor(imgs.size(0), 1).fill_(1.0), requires_grad=False)
fake_labels = Variable(Tensor(imgs.size(0), 1).fill_(0.0), requires_grad=False)
optimizer_G.zero_grad()实现效果图样例:




创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!
最后

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 8
8 0
0- 0



 已为社区贡献67条内容
已为社区贡献67条内容

所有评论(0)