【LLM大模型】5分钟打造基于 LangChain+Gradio 的个人知识助理
一直在研究大模型的 langchain 编程和检索增强相关的内容,今天和大家分享一些如何在5分钟之内利用 LangChain+Gradio 搭建一个自己的个人知识助理。
一直在研究大模型的 langchain 编程和检索增强相关的内容,今天和大家分享一些如何在5分钟之内利用 LangChain+Gradio 搭建一个自己的个人知识助理。这听起来就很酷,我们不需要依赖其他第三方提供的服务,也可以保证自己数据的安全性,赶紧顺着本文往下看吧。
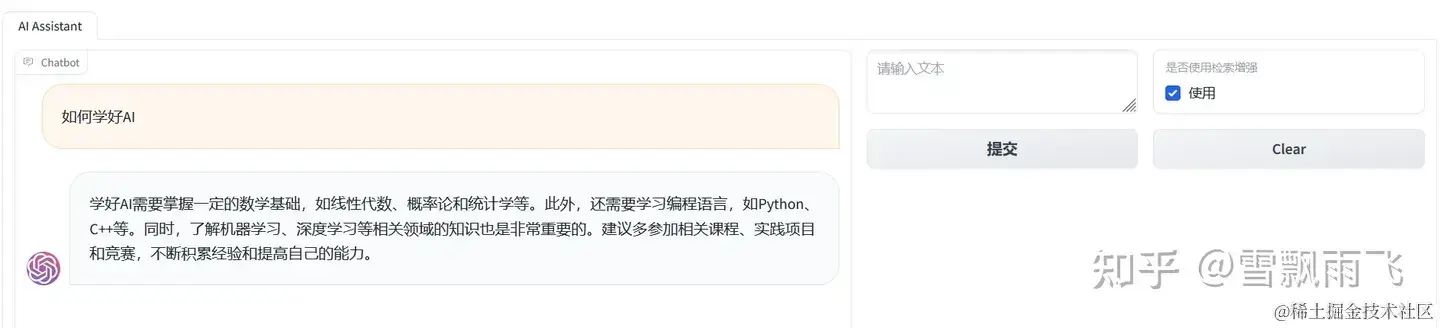
一、效果预览
最终的展示效果如下图,可以自行选择是否开启检索增强的功能。在使用检索增强调用之后,大模型能根据检索到的上下文进行回答,有效减少幻觉问题。当然,限于提供的示例代码本身的能力并不强,还有许多优化的空间,因此有一些问题回答并不好。

二、环境搭建
本项目在 python 3.8.5 版本进行实测,过低的版本,langchain 会有 bug,不建议使用。可以使用下面的命令,安装所需要的依赖项,如果因为网络问题导致本地安装失败,可以尝试使用清华源进行安装。
bash
复制代码
pip install flask chromadb gradio fastapi langchain FlagEmbedding
# 可选使用清华或者其他源下载依赖包
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple flask
FlagEmbedding 是一个向量模型的依赖包,直接安装之后,会把 pytorch、transformer 等一系列的依赖都安装上,因此整体执行的时间会偏长,需要耐心等待安装完毕。
FlagEmbedding 默认安装的是 CPU 版本的 pytorch,执行代码的时间也相对比较长。如果有条件,可以自行先安装 GPU 版本的 pytorch,然后再安装 FlagEmbedding。GPU 的显存在 4G 以上都可以正常调用,考虑到 GPU相关配置比较复杂,在5分钟内是搞不定的,有需要的话,我们下次再讲。
三、数据配置
一)知识库建立
可以使用自己的任意数据集作为知识库,将数据保存成 txt 文件就可以。在这里,我使用在网上自己处理的关于知识星球的数据作为知识库,然后建立本地路径进行存储。示例的数据已经和代码放在了一起,可以参考示例数据进行定义,文件要求使用 UTF-8 进行编码。
二)向量模型下载
FlagEmbedding 对应的向量模型是 BGE,目前是效果比较好的中文向量模型,原始的模型权重需要在 hugging face 上才能下载,需要一些特殊的网络环境,适合有经验的人员进行下载。非专业人员可以直接使用我下载好的权重模型,如果想自己下载,需要先安装 git lfs。然后执行下面的命令,就可以下载整个模型的权重以及相关配置文件。下载完成后,同样,需要将模型的文件夹存放到你自己的指定目录。
bash
复制代码
git lfs install
git clone https://huggingface.co/BAAI/bge-large-zh
四、大模型配置
为了调用方便,我们使用了讯飞星火的API作为本次的大模型,在讯飞的官方页面就可以申请免费的 token,足够我们日常使用和测试了。讯飞的官方地址: xinghuo.xfyun.cn/
我们这次只需要使用 2.0 版本的 API 就可以,申请之后可以看到接口服务认证的信息,需要记录下来,后面需要将这个地方修改为自己的信息。这三个信息是 APPID、APISecret 和 APIKey 的信息。获取这三个信息之后,大模型的部分就处理完成了。

五、代码修改
整个项目的代码结构主要有四个 python 文件和一个图片构成,下面先介绍各个文件的作用,以及要执行代码需要修改的内容。
- SparkApi 讯飞星火的 api 调用代码,无需修改
- SparkGPT 讯飞星火的包装类,需要修改
- prompt_utils 提示词的包装类,无需修改
- gradio_demo 主界面的入口,需要修改里面的路径
- GPT4.png 主界面上 GPT 头像的资源图片,无需修改
SparkGPT.py 代码中,需要将第 7-9 行的内容进行修改,将你在讯飞星火的控制台中获取的信息填写上去。
ini
复制代码
import SparkApi
from abc import ABC, abstractmethod
appid = "" # 填写控制台中获取的 APPID 信息
api_secret = "" # 填写控制台中获取的 APISecret 信息
api_key = "" # 填写控制台中获取的 APIKey 信息
gradio_demo.py 代码中,需要将第 20-21 行进行替换成你的模型和数据所在的文件夹路径。
javascript
复制代码
import gradio as gr
import uvicorn
from fastapi import FastAPI
from langchain.text_splitter import RecursiveCharacterTextSplitter
import os
from typing import List
from FlagEmbedding import FlagModel
from langchain.document_loaders import TextLoader
from langchain.retrievers import ParentDocumentRetriever
from langchain.schema.embeddings import Embeddings
from langchain.storage import InMemoryStore
from langchain.vectorstores import Chroma
from SparkGPT import SparkGPT
from prompt_utils import generate_prompt
BGE_MODEL_PATH = "D:\codes\bge-large-zh"
FILE_PATH="D:\codes\zsxq"
修改完毕后,执行 python gradio_demo.py 看到如下的启动命令,则启动成功。点击对应的 URL 即可看到开头所示的界面,然后就可以进行使用了。

六、代码
所有开源的代码都可以免费进行下载和使用,如果有不明白的地方,请及时联系。后续也会出一期,针对代码的讲解。
如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型商业化落地方案

阶段1:AI大模型时代的基础理解
- 目标:了解AI大模型的基本概念、发展历程和核心原理。
- 内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践 - L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
- 目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
- 内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例 - L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词 - L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用 - L2.4 总结与展望
- L2.1 API接口
阶段3:AI大模型应用架构实践
- 目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
- 内容:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节 - L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景 - L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例 - L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例 - L3.5 其他大模型介绍
- L3.1 Agent模型框架
阶段4:AI大模型私有化部署
- 目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
- 内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓


开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 25
25 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)