向量检索(二)Faiss 不同索引的性能
faiss 中不同算法构建索引,不同的搜索参数, 搜索的性能和召回率差异巨大。 本文在召回率比较好的情况下 (>0.99),对比常用的 IVF 索引和 HNSW 索引的性能差异
IVF + Flat 索引的性能
sift1m 数据集合, 指定 nlist 为 16384,对搜索的性能做测试,
机器环境: Mac Pro 2020, Intel, 16G 内存
index = faiss.index_factory(d, "IVF16386,Flat")
index.train(xb)
index.add(xb)
index.nprobe = 256
D, I = index.search(xq, k)
recall(I)
nprobe = 256时,不论取 nlist = 16384, 还是 nlist = 4096, recall 都接近1, 响应时间 < 4ms 单个请求。
| nprobe | Recall | Search Time |
|---|---|---|
| 1 | 0 | 1.55ms |
| 16 | 1.0 | 1.48ms |
| 128 | 1.0 | 2.46ms |
| 256 | 1.0 | 3.43ms |
这是每次执行单个搜索请求的性能。 当一次执行多个向量(一次检索100个,10000个 query)的检索时,整体的耗时变化不大。 faiss 并行检索的性能非常好。
sfit1m 的数据集, IVF Flat 的索引大约为 520M,创建索引的时间约为 5 分钟。
参考:
https://github.com/facebookresearch/faiss/issues/23
http://ann-benchmarks.com/index.html
https://github.com/facebookresearch/faiss/wiki/Indexing-1M-vectors
IVF + HNSW 索引的参数与性能
IVF 索引,聚类的中心点数量建议设置在 4096 以上。
1 million 的数据索引, 推荐设置 nlist 值为 65536, 这种情况下需要 30*nlist == 1.97M 的向量来传入到 index.train 做训练。
就 sift1m 128维度的数据来说, 对于 IVF+HNSW 的索引, 由于数据量不够 1.97M, 使用 nlist=4096能够得到一个很好的召回率。
index = faiss.index_factory(d, "IVF4096_HNSW32,Flat")
index.train(xb)
index.add(xb)
D, I = index.search(xq, k)
recall(I)
%%timeit
index.search(xq, k)
index.nprobe = 146
D, I = index.search(xq, k)
recall(I)
%%timeit
index.search(xq, k)

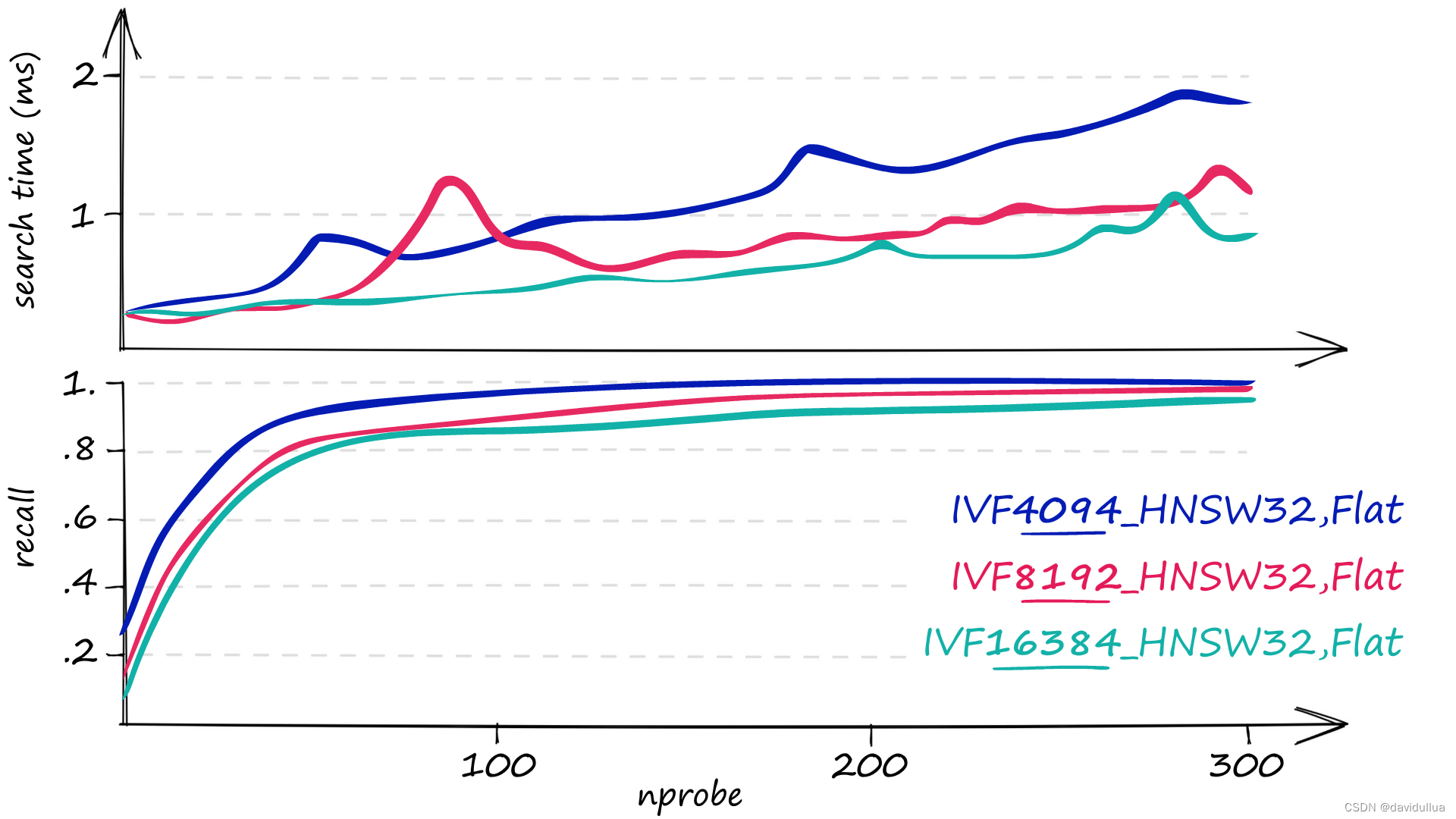
不同的 nprobe 跑出来的 recall 和搜索耗时 (1million sift1m 数据)
HNSW 有很好的召回和检索性能, 缺点是内存消耗大。 Sift1M 128维的数据集,索引大小约在 523M+, 内存耗用大约也是这个大小。
| Index (nprobe = 64) | Recall | Search Time | Memory |
|---|---|---|---|
IVF4096_HNSW,Flat | 90% | 550µs | 523MB |
IVF4096_HNSW,PQ32 (PQ) | 69% | 550µs | 43MB |
OPQ32,IVF4096_HNSW,PQ32 (OPQ) | 74% | 364µs | 43MB |
不同索引类型的召回率
从图中可以看出来, 当 nprobe 设置为 150 左右时,IVF4096, HNSW32 的召回率为 1。
参考:
https://www.pinecone.io/learn/composite-indexes/
https://www.pinecone.io/learn/hnsw/

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)