【LLM】Langchain使用[三](基于文档的问答)
不同类型的chain链想在许多不同类型的块上执行相同类型的问答,该怎么办?上面的实验只返回了4个文档,如果有多个文档,我们可以使用几种不同的方法* Map Reduce将所有块与问题一起传递给语言模型,获取回复,使用另一个语言模型调用将所有单独的回复总结成最终答案,它可以在任意数量的文档上运行。可以并行处理单个问题,同时也需要更多的调用。它将所有文档视为独立的* Refine用于循环许多文档,实际
一、基于文档的问答
1. 创建向量存储
- CSVLoader加载csv数据,loader结合模型使用
- 使用Dock Array内存搜索向量存储,作为一个内存向量存储,不需要连接外部数据库
- 创建向量存储:导入一个索引,即向量存储索引创建器
from langchain.chains import RetrievalQA #检索QA链,在文档上进行检索
from langchain.chat_models import ChatOpenAI #openai模型
from langchain.document_loaders import CSVLoader #文档加载器,采用csv格式存储
from langchain.vectorstores import DocArrayInMemorySearch #向量存储
from IPython.display import display, Markdown #在jupyter显示信息的工具
file = 'OutdoorClothingCatalog_1000.csv'
loader = CSVLoader(file_path=file)
#查看数据
import pandas as pd
data = pd.read_csv(file,header=None)
数据是字段为name和description的文本数据:

# 创建向量存储
from langchain.indexes import VectorstoreIndexCreator #导入向量存储索引创建器
'''
将指定向量存储类,创建完成后,我们将从加载器中调用,通过文档记载器列表加载
'''
index = VectorstoreIndexCreator(
vectorstore_cls=DocArrayInMemorySearch
).from_loaders([loader])
query ="Please list all your shirts with sun protection \
in a table in markdown and summarize each one."
response = index.query(query)#使用索引查询创建一个响应,并传入这个查询
display(Markdown(response))#查看查询返回的内容

得到了一个Markdown表格,其中包含所有带有防晒衣的衬衫的名称和描述,描述是总结过的。
'''
为刚才的文本创建embedding,准备将它们存储在向量存储中,使用向量存储上的from documents方法来实现。
该方法接受文档列表、嵌入对象,然后我们将创建一个总体向量存储
'''
db = DocArrayInMemorySearch.from_documents(
docs,
embeddings
)
query = "Please suggest a shirt with sunblocking"
docs = db.similarity_search(query)#使用这个向量存储来查找与传入查询类似的文本,如果我们在向量存储中使用相似性搜索方法并传入一个查询,我们将得到一个文档列表
len(docs)# 我们可以看到它返回了四个文档
# 回答文档的相关问题
retriever = db.as_retriever() #创建检索器通用接口
llm = ChatOpenAI(temperature = 0.0,max_tokens=1024) #导入语言模型
qdocs = "".join([docs[i].page_content for i in range(len(docs))]) # 将合并文档中的所有页面内容到一个变量中
response = llm.call_as_llm(f"{qdocs} Question: Please list all your \
shirts with sun protection in a table in markdown and summarize each one.") #列出所有具有防晒功能的衬衫并在Markdown表格中总结每个衬衫的语言模型
向量数据库使用的是chromadb。通过LangChain链封装起来,创建一个检索QA链,对检索到的文档进行问题回答,要创建这样的链,我们将传入几个不同的东西
- 1、语言模型,在最后进行文本生成
- 2、传入链类型,这里使用
stuff,将所有文档塞入上下文并对语言模型进行一次调用 - 3、传入一个检索器
qa_stuff = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
verbose=True
)
query = "Please list all your shirts with sun protection in a table \
in markdown and summarize each one."#创建一个查询并在此查询上运行链
response = qa_stuff.run(query)
display(Markdown(response))#使用 display 和 markdown 显示它
RetrievalQA链其实就是把合并文本片段和调用语言模型这两步骤封装起来,如果没有RetrievalQA链,我们需要这样子实现:
# 将检索出来的文本片段合并成一段文本
qdocs = "".join([docs[i].page_content for i in range(len(docs))])
# 将合并后的文本和问题一起传给LLM
response = llm.call_as_llm(f"{qdocs} Question: Please list all your \
shirts with sun protection in a table in markdown and summarize each one.")
2. 不同类型的chain链
想在许多不同类型的块上执行相同类型的问答,该怎么办?上面的实验只返回了4个文档,如果有多个文档,我们可以使用几种不同的方法
- Map Reduce
将所有块与问题一起传递给语言模型,获取回复,使用另一个语言模型调用将所有单独的回复总结成最终答案,它可以在任意数量的文档上运行。可以并行处理单个问题,同时也需要更多的调用。它将所有文档视为独立的 - Refine
用于循环许多文档,实际上是迭代的,建立在先前文档的答案之上,非常适合前后因果信息并随时间逐步构建答案,依赖于先前调用的结果。它通常需要更长的时间,并且基本上需要与Map Reduce一样多的调用 - Map Re-rank
对每个文档进行单个语言模型调用,要求它返回一个分数,选择最高分,这依赖于语言模型知道分数应该是什么,需要告诉它,如果它与文档相关,则应该是高分,并在那里精细调整说明,可以批量处理它们相对较快,但是更加昂贵 - Stuff
将所有内容组合成一个文档
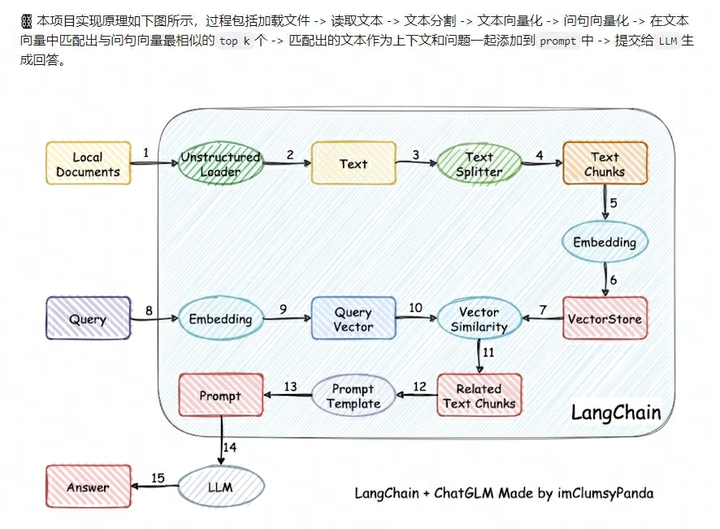
二、本地知识库问答
1.1 整体框架

- 改进的点(方向):
- 改LLM模型
- embedding模型
- 文本分割方式
- 多卡加速模型部署
- 提升top-k检索召回的质量
- 基于数据隐私和私有化部署,可以方便的使用Langchain+大模型进行推理
2. 文本切分
Langchain源码:https://github.com/hwchase17/langchain/blob/master/langchain/text_splitter.py
Langchain的内置文本拆分模块的常见参数:
- chunk_size:文本块的大小,即文本块的最大尺寸;
- chunk_overlap:表示两个切分文本之间的重合度,文本块之间的最大重叠量,保留一些重叠可以保持文本块之间的连续性,可以使用滑动窗口进行构造,这个比较重要。
- length_function:用于计算文本块长度的方法,默认为简单的计算字符数;
其他文本分割器:
文本分割器
LatexTextSplitter
沿着Latex标题、标题、枚举等分割文本。
MarkdownTextSplitter
沿着Markdown的标题、代码块或水平规则来分
割文本。
NLTKTextSplitter
使用NLTK的分割器
PythonCodeTextSplitter
沿着Python类和方法的定义分割文本。
RecursiveCharacterTextSplitter
用于通用文本的分割器。它以一个字符列表为
参数, 尽可能地把所有的段落 (然后是句子,
然后是单词) 放在一起
SpacyTextSplitter
使用Spacy的分割器
TokenTextSplitter
根据openAl的token数进行分割
\begin{array}{|c|c|} \hline \text { 文本分割器 } & \\ \hline \text { LatexTextSplitter } & \text { 沿着Latex标题、标题、枚举等分割文本。 } \\ \hline \text { MarkdownTextSplitter } & \begin{array}{l} \text { 沿着Markdown的标题、代码块或水平规则来分 } \\ \text { 割文本。 } \end{array} \\ \hline \text { NLTKTextSplitter } & \text { 使用NLTK的分割器 } \\ \hline \text { PythonCodeTextSplitter } & \text { 沿着Python类和方法的定义分割文本。 } \\ \hline \text { RecursiveCharacterTextSplitter } & \begin{array}{l} \text { 用于通用文本的分割器。它以一个字符列表为 } \\ \text { 参数, 尽可能地把所有的段落 (然后是句子, } \\ \text { 然后是单词) 放在一起 } \end{array} \\ \hline \text { SpacyTextSplitter } & \text { 使用Spacy的分割器 } \\ \hline \text { TokenTextSplitter } & \text { 根据openAl的token数进行分割 } \\ \hline \end{array}
文本分割器 LatexTextSplitter MarkdownTextSplitter NLTKTextSplitter PythonCodeTextSplitter RecursiveCharacterTextSplitter SpacyTextSplitter TokenTextSplitter 沿着Latex标题、标题、枚举等分割文本。 沿着Markdown的标题、代码块或水平规则来分 割文本。 使用NLTK的分割器 沿着Python类和方法的定义分割文本。 用于通用文本的分割器。它以一个字符列表为 参数, 尽可能地把所有的段落 (然后是句子, 然后是单词) 放在一起 使用Spacy的分割器 根据openAl的token数进行分割
我们直接举个栗子,比如对中文文本切分,继承langchain中类CharacterTextSplitter的ChineseTextSplitter类。正则表达式sent_sep_pattern来匹配中文句子的分隔符(如句号,感叹号,问好,分号等):
# 中文文本切分类
class ChineseTextSplitter(CharacterTextSplitter):
def __init__(self, pdf: bool = False, **kwargs):
super().__init__(**kwargs)
self.pdf = pdf
def split_text(self, text: str) -> List[str]:
if self.pdf:
text = re.sub(r"\n{3,}", "\n", text)
text = re.sub('\s', ' ', text)
text = text.replace("\n\n", "")
sent_sep_pattern = re.compile('([﹒﹔﹖﹗.。!?]["’”」』]{0,2}|(?=["‘“「『]{1,2}|$))') # del :;
sent_list = []
for ele in sent_sep_pattern.split(text):
if sent_sep_pattern.match(ele) and sent_list:
sent_list[-1] += ele
elif ele:
sent_list.append(ele)
return sent_list
3. 图解流程

Reference
[1] MedicalGPT: Training Medical GPT Model
[2] How to handle rate limits.openai
[3] 谈langchain大模型外挂知识库问答系统核心部件:如何更好地解析、分割复杂非结构化文本
[4] All You Need to Know to Build Your First LLM App.towardsdatascience
[5] LLM 系列 | 15:如何用LangChain做长文档问答
[6] 本地知识库对话系统大模型.tx技术工程

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 2
2 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)