LangChain之各个输出解析器的使用
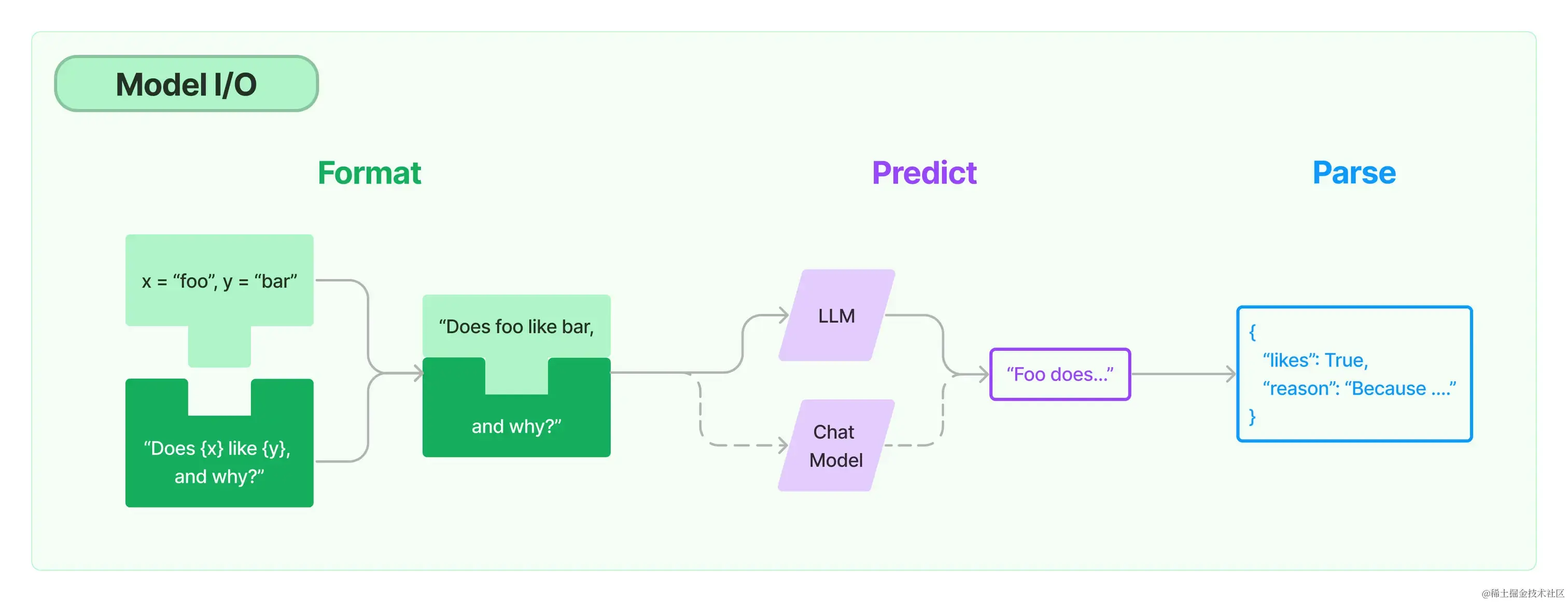
在LangChain中,Model I/O被称为:模型的输入与输出,其有输入提示(Format)、调用模型(Predict)、输出解析(Parse)等三部分组成。
Model I/O
在LangChain中,
Model I/O被称为:模型的输入与输出,其有输入提示(Format)、调用模型(Predict)、输出解析(Parse)等三部分组成。
makefile
复制代码
1.提示模板: LangChain的模板允许动态选择输入,根据实际需求调整输入内容,适用于各种特定任务和应用。
2.语言模型: LangChain 提供通用接口调用不同类型的语言模型,提升了灵活性和使用便利性。
3.输出解析: 利用 LangChain 的输出解析功能,精准提取模型输出中所需信息,避免处理冗余数据,同时将非结构化文本转换为可处理的结构化数据,提高信息处理效率。

输出解析器
概述
在LangChain的Model I/O中,输出解析器是其组成之一,这里也主要申明记录
输出解析(Parse)的使用。
输出解析器负责获取 LLM 的输出并将其转换为更合适的格式。借助LangChain的输出解析器重构程序,使模型能够生成结构化回应,并可以直接解析这些回应
结构
输出解析器是专用于处理和构建语言模型响应的类。一个基本输出解析器类通常需要实现两个核心方法:
python
复制代码
get_format_instructions:返回指导如何格式化语言模型输出的字符串,指导如何构建和组织回答。
parse:接受一个字符串(语言模型输出),将其解析为特定的数据结构或格式。
parse_with_prompt:可选方法,接受一个字符串(语言模型输出)和一个提示(生成输出的提示),将其解析为特定数据结构。
OutputParser输出解析器结构如下:
python
复制代码
class OutputParser:
def __init__(self):
pass
def get_format_instructions(self):
# 返回一个字符串,指导如何格式化模型的输出
pass
def parse(self, model_output):
# 解析模型的输出,转换为某种数据结构或格式
pass
def parse_with_prompt(self, model_output, prompt):
# 基于原始提示解析模型的输出,转换为某种数据结构或格式
pass
类型
LangChain有许多不同类型的输出解析器
| 名称 | 类名 | 描述 |
|---|---|---|
| CSV解析器) | CommaSeparatedListOutputParser | 模型的输出以逗号分隔,以列表形式返回输出 |
| 日期时间解析器 | DatetimeOutputParser | 可用于将 LLM 输出解析为日期时间格式 |
| 枚举解析器 | EnumOutputParser | 用于处理预定义的一组值,确保模型的输出在这些预定义值之中 |
| JSON解析器 | JsonOutputParser | 确保输出符合特定JSON对象格式。利用Pydantic库,解析器能验证数据并构建复杂数据模型,以确保输出符合预期数据模型。 |
| OpenAI函数中的解析器 | JsonOutputFunctionsParser PydanticOutputFunctionsParser JsonKeyOutputFunctionsParser PydanticAttrOutputFunctionsParser | 使用OpenAI函数调用来结构化其输出。只能与支持函数调用的模型一起使用 |
| OpenAI工具中的解析 | JsonOutputToolsParser JsonOutputKeyToolsParser PydanticToolsParser | 从 OpenAI 的函数调用 API 响应中提取工具调用。只能用于支持函数调用的模型 |
| 自动修复解析器 | OutputFixingParser | 输出解析器包装了另一个输出解析器,如果第一个解析器失败,它会调用另一个LLM来修复任何错误。 |
| Pandas DataFrame解析器 | PandasDataFrameOutputParser | 允许用户指定任意的Pandas DataFrame,并查询LLMs以获取以格式化字典形式提取数据的数据 |
| Pydantic解析器 | PydanticOutputParser | 允许指定任意的Pydantic模型并查询LLM以获得符合该架构的输出。 |
| 重试解析器 | OutputFixingParser | 在模型的初次输出不符合预期时,尝试修复或重新生成新的输出 |
| 结构化输出解析器 | StructuredOutputParser | 用于处理复杂的、结构化的输出。当应用需要模型生成具有特定结构的复杂回答时,可使用结构化输出解析器来实现 |
| XML解析器 | XMLOutputParser | 允许以流行的XML格式从LLM获取结果 |
| YAML解析器 | YamlOutputParser | 器允许指定任意的模式,并查询兼容该模式的LLMs输出,使用YAML格式化响应。 |
各个输出解析器的基本使用
设置环境变量
python
复制代码
import os
os.environ["OPENAI_BASE_URL"] = "https://xxx.com/v1"
os.environ["OPENAI_API_KEY"] = "sk-fDqouTlU62yjkBhF46284543Dc8f42438a9529Df74B4Ce65"
CSV解析器
使用一个简单的方法来解析逗号分隔值的列表。
python
复制代码
from langchain_core.prompts import PromptTemplate
from langchain_openai import OpenAI
# 初始化语言模型
model = OpenAI(model_name="gpt-3.5-turbo-instruct", temperature=0.0)
# 创建解析器
from langchain.output_parsers import CommaSeparatedListOutputParser
output_parser = CommaSeparatedListOutputParser()
# 提示模板
template = "Generate a list of 5 {text}.\n\n{format_instructions}"
# 根据提示模板创建LangChain提示模板
chat_prompt = PromptTemplate.from_template(template)
# 提示模板与输出解析器传递输出
chat_prompt = chat_prompt.partial(format_instructions=output_parser.get_format_instructions())
# 将提示和模型合并以进行调用
chain = chat_prompt | model | output_parser
res = chain.invoke({"text": "colors"})
print(res)
python
复制代码
['red', 'blue', 'green', 'yellow', 'purple']
日期时间解析器
用于处理日期和时间相关的输出,确保模型的输出是正确的日期或时间格式
bash
复制代码
from langchain.output_parsers import DatetimeOutputParser
from langchain.prompts import PromptTemplate
from langchain_openai import OpenAI
# 定义模板格式
template = """
回答用户的问题:{question}
{format_instructions}
"""
# 使用日期时间解析器
output_parser = DatetimeOutputParser()
prompt = PromptTemplate.from_template(
template,
partial_variables={"format_instructions": output_parser.get_format_instructions()},
)
# 链式调用
chain = prompt | OpenAI() | output_parser
# 执行
output = chain.invoke({"question": "比特币是什么时候成立的?"})
# 打印输出
print(output) # 2009-01-03 18:15:05
枚举解析器
1.创建枚举类型的输出解析器,首先定义Colors枚举类,然后创建EnumOutputParser实例,传入Colors枚举类。
2.在提示模板中使用person和instructions占位符,instructions获取EnumOutputParser输出的枚举值的格式说明。
3.构建聊天处理链,从提示模板开始,依次连接ChatOpenAI模块和刚创建的parser。最后调用了链的 invoke 方法
bash
复制代码
from langchain.output_parsers.enum import EnumOutputParser # 导入枚举类型的输出解析器
from langchain_core.prompts import PromptTemplate # 导入提示模板
from langchain_openai import ChatOpenAI # 导入与OpenAI的聊天模块
from enum import Enum # 导入枚举类型
# 定义一个枚举类Colors,包含三个颜色选项
class Colors(Enum):
RED = "红色"
GREEN = "绿色"
BLUE = "蓝色"
# 创建一个 EnumOutputParser 实例,传入 Colors 枚举类
parser = EnumOutputParser(enum=Colors)
# 创建一个提示模板,包含一个名为 person 的占位符和一个名为 instructions 的占位符
prompt = PromptTemplate.from_template(
"""这个人的眼睛是什么颜色的?
> 人物: {person}
指示: {instructions}"""
).partial(instructions=parser.get_format_instructions()) # 使用 parser 获取枚举值格式的说明
# 构建聊天处理链,以 prompt 开始,连接 ChatOpenAI,最后连接 parser
chain = prompt | ChatOpenAI() | parser
# 调用链的 invoke 方法,并传入一个字典,包含 person 变量
res = chain.invoke({"person": "Frank Sinatra"})
print(res)
OpenAI函数
有以下几种输出解析器:
javascript
复制代码
JsonOutputFunctionsParser:以 JSON 形式返回函数调用的参数
PydanticOutputFunctionsParser:将函数调用的参数作为 Pydantic 模型返回
JsonKeyOutputFunctionsParser:以 JSON 形式返回函数调用中特定键的值
PydanticAttrOutputFunctionsParser:以 Pydantic 模型的形式返回函数调用中特定键的值
bash
复制代码
from langchain_core.utils.function_calling import convert_pydantic_to_openai_function # 导入用于将Pydantic模型转换为OpenAI函数的函数
from langchain_core.prompts import ChatPromptTemplate # 导入聊天提示模板
from langchain_core.pydantic_v1 import BaseModel, Field, validator # 导入Pydantic的相关模块
from langchain_openai import ChatOpenAI # 导入与OpenAI的聊天模块
from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser # 导入OpenAI函数的输出解析器
# 定义一个名为 Joke 的 Pydantic 模型,表示一个笑话包括 setup(问题)和 punchline(答案)两个字段
class Joke(BaseModel):
setup: str = Field(description="设置笑话的问题")
punchline: str = Field(description="解决笑话的答案")
# 将 Joke 转换为 OpenAI 函数,并存储在 openai_functions 列表中
openai_functions = [convert_pydantic_to_openai_function(Joke)]
# 创建一个 ChatOpenAI 实例 model,设定 temperature 参数为 0
model = ChatOpenAI(temperature=0)
# 创建一个聊天提示模板 prompt,包含一个系统信息 "你是一个乐于助人的助手" 和一个用户输入的占位符
prompt = ChatPromptTemplate.from_messages(
[("system", "你是一个乐于助人的助手"), ("user", "{input}")]
)
# 创建一个 JsonOutputFunctionsParser 解析器实例 parser
parser = JsonOutputFunctionsParser()
# 构建聊天处理链,以 prompt 开始,连接 model,最后连接 parser
chain = prompt | model.bind(functions=openai_functions) | parser
# 调用链的 invoke 方法,向其传入一个包含用户输入的字典,并将结果保存在 res 中
res = chain.invoke({"input": "给我讲个笑话"})
print(res)
bash
复制代码
{'setup': '为什么鱼不喜欢唱歌?', 'punchline': '因为它们会唱歌会泡沫!'}
自动修复解析器
python
复制代码
# 导入必要的类和模块
import os
from langchain.output_parsers import PydanticOutputParser
from langchain.prompts import PromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field, validator
from langchain_openai import OpenAI
# 初始化语言模型
model = OpenAI(model_name="gpt-3.5-turbo-instruct", temperature=0.0)
# 定义笑话数据的结构
class Joke(BaseModel):
setup: str = Field(description="用于建立笑话的问题部分")
punchline: str = Field(description="回答笑话的部分")
# 使用 Pydantic 轻松添加自定义验证逻辑
@validator("setup")
def question_ends_with_question_mark(cls, field):
if field[-1] != "?":
raise ValueError("问题格式不正确!")
return field
# 设置解析器并将指令注入到提示模板中
parser = PydanticOutputParser(pydantic_object=Joke)
prompt = PromptTemplate(
template="回答用户的查询。\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
# 将提示和模型合并以进行调用
prompt_and_model = prompt | model
output = prompt_and_model.invoke({"query": "给我讲个笑话."})
print(output)
# 使用解析器从输出中提取结构化数据
setup, punchline = parser.invoke(output)
print(f"问题: {setup} 回答: {punchline}""")
python
复制代码
{"setup": "为什么程序员总是喜欢用黑色的键盘?", "punchline": "因为黑色的键盘看起来像是在编程的黑暗中寻找光明。"}
问题: ('setup', '为什么程序员总是喜欢用黑色的键盘?') 回答: ('punchline', '因为黑色的键盘看起来像是在编程的黑暗中寻找光明。')
Pydantic解析器
Pydantic是一个Python库,它旨在简化数据验证和解析的过程。它提供了一种简单而强大的方式来定义数据模型,并使用这些模型来验证数据的有效性并进行解析。Pydantic通过在数据类中定义属性的类型和验证规则,使得数据模型的创建和验证变得非常容易。这个库还支持自动生成文档、序列化和反序列化等功能,使得数据处理变得更加高效和可靠。Pydantic通常用于构建Web应用程序、API服务以及数据处理任务中。
python
复制代码
# 创建模型实例
from langchain_openai import OpenAI
model = OpenAI(model_name='gpt-3.5-turbo-instruct')
# 定义接收的数据格式
from pydantic import BaseModel, Field
class TextInfo(BaseModel):
text: str = Field(description="文本信息")
object: str = Field(description="对象是谁")
description: str = Field(description="人物描述")
# 创建输出解析器
from langchain.output_parsers import PydanticOutputParser
output_parser = PydanticOutputParser(pydantic_object=TextInfo)
# 获取输出格式指示
format_instructions = output_parser.get_format_instructions()
# 打印提示
print("输出格式:", format_instructions)
# 创建提示模板
from langchain_core.prompts import PromptTemplate
prompt_template = """您是一位专业的文案写手。对于信息 {text} 进行简短生动描述 {format_instructions}"""
# 根据模板创建提示,同时在提示中加入输出解析器的说明
prompt = PromptTemplate.from_template(prompt_template, partial_variables={"format_instructions": format_instructions})
# 根据提示准备模型的输入
input = prompt.format(text='猪八戒吃人参果')
# 打印提示
print("提示:", input)
# 获取模型的输出
output = model.invoke(input)
# 解析模型的输出
parsed_output = output_parser.parse(output)
# 将Pydantic格式转换为字典
parsed_output_dict = parsed_output.dict()
# 打印字典
print("输出的数据:", parsed_output_dict)
python
复制代码
输出的数据: {'text': '猪八戒吃人参果', 'object': '信息', 'description': '猪八戒是一位贪吃的妖怪,他偶然得到了一粒人参果,听说可以长生不老,于是欢天喜地地吃了下去。但是没想到果真如此,他的身体也变得越来越大,最后连猴子大王都不是他的对手了。'}
自动修复解析器
python
复制代码
# 导入所需要的库和模块
from langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field
# 使用Pydantic创建一个数据格式
class TextInfo(BaseModel):
text: str = Field(description="文本信息")
object: str = Field(description="对象是谁")
description: str = Field(description="人物描述")
# 定义一个格式不正确的输出:Python期望属性名称被双引号包围,但在给定的JSON字符串中是单引号。
misformatted = "{'text': '猪八戒吃人参果', ‘object':'猪八戒','description':'猪八戒是一位贪吃的妖怪,他偶然得到了一粒人参果,听说可以长生不老,于是欢天喜地地吃了下去。'}"
# 创建一个用于解析输出的Pydantic解析器
parser = PydanticOutputParser(pydantic_object=TextInfo)
# 使用Pydantic解析器解析不正确的输出,出现异常提示:json.decoder.JSONDecodeError: Expecting property name enclosed in double quotes: line 1 column 2 (char 1)
# parser.parse(misformatted)
# 从langchain库导入所需的模块
from langchain_openai import ChatOpenAI
from langchain.output_parsers import OutputFixingParser
# 使用OutputFixingParser创建一个新的解析器,该解析器能够纠正格式不正确的输出
new_parser = OutputFixingParser.from_llm(parser=parser, llm=ChatOpenAI())
# 使用新的解析器解析不正确的输出
result = new_parser.parse(misformatted)
print(result)
重试解析器
有时候可以通过查看输出修复解析错误,但并非所有情况下都适用。举例来说,当输出格式不正确且部分完整时,LangChain的重试解析器利用大型模型的推理能力,根据原始提示来找回相关信息,帮助解析数据。
python
复制代码
# 定义一个模板字符串,这个模板将用于生成提问
template = """根据用户问题,提供操作和操作输入,说明应采取的步骤.
{format_instructions}
问题: {query}
响应:
"""
# 定义一个Pydantic数据格式
from pydantic import BaseModel, Field
# 使用Pydantic格式Action来初始化一个输出解析器
from langchain.output_parsers import PydanticOutputParser
class Action(BaseModel):
action: str = Field(description="要采取的操作")
action_input: str = Field(description="操作的输入")
parser = PydanticOutputParser(pydantic_object=Action)
# 定义一个提示模板,它将用于向模型提问
from langchain.prompts import PromptTemplate
prompt = PromptTemplate(
template="回答用户查询.\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
prompt_value = prompt.format_prompt(query="猪八戒是谁?")
# 定义一个错误格式的字符串:提供action字段,没有提供action_input字段,与Action数据格式的预期不符,解析会失败
bad_response = '{"action": "search"}'
# parser.parse(bad_response) # 直接解析会引发一个错误
# 用OutputFixingParser修复此错误
from langchain.output_parsers import OutputFixingParser
from langchain_openai import ChatOpenAI
fix_parser = OutputFixingParser.from_llm(parser=parser, llm=ChatOpenAI())
parse_result = fix_parser.parse(bad_response)
# 原始bad_response没有action_input字段。OutputFixingParser填补缺失,为action_input字段提供值keyword。
print('OutputFixingParser的parse结果:', parse_result)
# 使用 RetryOutputParser,它传入提示(以及原始输出)以再次尝试以获得更好的响应。
from langchain.output_parsers import RetryWithErrorOutputParser
from langchain_openai import OpenAI
retry_parser = RetryWithErrorOutputParser.from_llm(
parser=parser, llm=OpenAI(temperature=0)
)
parse_result = retry_parser.parse_with_prompt(bad_response, prompt_value)
# 根据传入的原始提示,还原了action_input字段的内容
print('RetryWithErrorOutputParser的parse结果:', parse_result)
python
复制代码
OutputFixingParser的parse结果: action='search' action_input='keyword'
RetryWithErrorOutputParser的parse结果: action='search' action_input='猪八戒'
结构化输出解析器
python
复制代码
# 通过LangChain调用模型
from langchain_core.prompts import PromptTemplate
# 创建提示模板
template = "您是一位专业的文案写手。\n对于信息 {text} 进行简短描述.{format_instructions}"
from langchain_openai import OpenAI
# 创建模型实例
model = OpenAI()
# 导入结构化输出解析器和ResponseSchema
from langchain.output_parsers import ResponseSchema, StructuredOutputParser
# 定义要接收的响应模式
response_schemas = [
ResponseSchema(name="info", description="信息"),
ResponseSchema(name="description", description="扩展描述")
]
# 创建输出解析器
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
# 获取格式指示
format_instructions = output_parser.get_format_instructions()
# 根据模板创建提示,同时在提示中加入输出解析器的说明
prompt = PromptTemplate.from_template(template,
partial_variables={"format_instructions": format_instructions})
# 根据提示准备模型的输入
inputData = prompt.format(text="猪八戒吃人参果")
# 获取模型的输出
output = model.invoke(inputData)
# 解析模型的输出
parsed_output = output_parser.parse(output)
print(parsed_output)
python
复制代码
{'info': '猪八戒吃人参果', 'description': '猪八戒是西游记中的一个角色,他是一只妖怪,但是也具有人类的智慧。人参果是一种神奇的植物,具有强大的功效,可以让人长生不老。猪八戒作为一个贪吃的妖怪,自然会对人参果产生强烈的兴趣,但是他的贪嘴往往会给他带来麻烦。这个信息可以用来描述猪八戒的特点,以及人参果的重要性。'}


开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 5
5 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)