(五)Langchain PGVector 补充智能客服匹配式问答
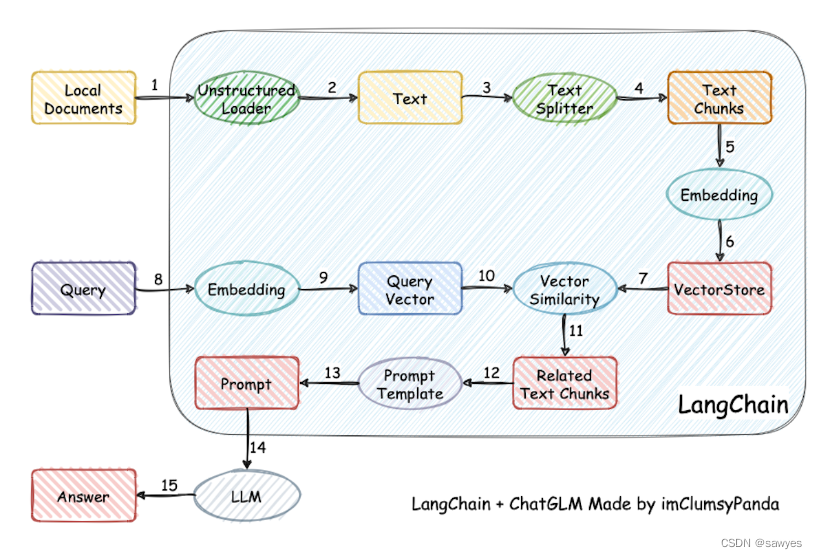
本项目实现原理如下图所示,过程包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的top k个 -> 匹配出的文本作为上下文和问题一起添加到prompt中 -> 提交给LLM生成回答。先让用户的问题,匹配问答中的问题(多问一答),相同的问题意图需要泛化,如果问题相识度满足一定的阈值,则返回问题对应的答案,如果不满足相关度阈值,
文章目录
资料
背景
最近在做智能客服,通过 https://github.com/imClumsyPanda/langchain-ChatGLM 可以完成DOC-QA 部分智能问答
摘要项目原理说明
本项目实现原理如下图所示,过程包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的top k个 -> 匹配出的文本作为上下文和问题一起添加到prompt中 -> 提交给LLM生成回答。

其中注意介绍中的这一句,在文本向量中匹配出与问句向量最相似的top k个,也就是第7和第10个步骤,有几个问题在实践中需要解决
- 测试过程中大部分答案还是满意的,但是由于原始文档切割,部分答案会丢失上下文(切割没了,top k也没匹配出来)
- 固定的问答对很难保障,比如操作流程,这种需求内容长且要求答案文本顺序不能乱
- 文本上下文存在复杂的内容,比如图片,音频,视频,需要处理才能让大模型呈现
- FAISS 向量库不支持matedata过滤,在复杂度更高的场景失去灵活性
- FAISS 不支持单条语句删除或更新
为了问答质量效果,既要保障高质量语料,也得寻求匹配式问答解决方案,这才选择了Langchain PGVector 补充智能客服匹配式问答
目标
先让用户的问题,匹配问答中的问题(多问一答),相同的问题意图需要泛化,如果问题相识度满足一定的阈值,则返回问题对应的答案,如果不满足相关度阈值,则把问题提交给文档问答库(适合有一定的业务文档积累场景)作为兜底,同样的也需要满足一定的相关度top k
FAQ-匹配式问答
安装PGVector 向量数据库
什么是 pgvector ? Postgres的开源向量相似性搜索,支持
- 精确和近似最近邻搜索
- L2 距离、内积和余弦距离
- 任何带有Postgres客户端的语言
为了快速验证可行性,使用 https://github.com/pgvector/pgvector 中docker方法启动项目
FROM ankane/pgvector
LABEL maintainer="Ben M <git@bmagg.com>"
CMD ["postgres"]
EXPOSE 5432
构建启动docker
docker build -t pgvector .
docker run -itd pgvector -p 5432 -e POSTGRES_DB=default -e POSTGRES_USER=default -e POSTGRES_PASSWORD=secret
text2vec-large-chinese
因为在实践过程中,如果用大模型能力去让文本向量化,貌似速度挺慢的,所以这里先使用text2vec-large-chinese作为向量模型
huggingface下载地址,https://huggingface.co/GanymedeNil/text2vec-large-chinese
放在测试项目的·models/text2vec-large-chinese·
国内下载慢的,可以在https://github.com/imClumsyPanda/langchain-ChatGLM/blob/master/docs/FAQ.md找到百度下载地址
Langchain-PGVector
通过学习Langchain-PGVector文档,首先安装langchain环境pgvector
pip install langchain pgvector -i http://mirrors.aliyun.com/pypi/simple/
测试向量化文本
Embedding 是一个浮点数向量(列表)。两个向量之间的距离用于测量它们之间的相关性。较小距离表示高相关性,较大距离表示低相关性。
为了提高相关性,尽可能泛化问题
from langchain.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(model_name="models/text2vec-large-chinese"
,model_kwargs={'device': "cpu"})
sentence = '你是谁|介绍一下你自己|你叫什么名字'
vec = embeddings.embed_documents(sentence)
print(vec)

写入QA问答对
下面代码第一次是不会运行成功的,耐心往下看就知道原因
需要注意和验证的问题是
- 问题都整合在一起效果更好还是分开?
- 分数越低,代表匹配相关性越高
- 向量化的是问题,答案作为metadata写入到数据库了
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores.pgvector import PGVector
from langchain.vectorstores.pgvector import DistanceStrategy
from langchain.docstore.document import Document
from typing import List, Tuple
embeddings = HuggingFaceEmbeddings(model_name="models/text2vec-large-chinese"
,model_kwargs={'device': "cpu"})
# sentence = '你是谁|介绍一下你自己|你叫什么名字'
# vec = embeddings.embed_documents(sentence)
# print(vec)
import os
PGVECTOR_CONNECTION_STRING = PGVector.connection_string_from_db_params(
driver=os.environ.get("PGVECTOR_DRIVER", "psycopg2"),
host=os.environ.get("PGVECTOR_HOST", "localhost"),
port=int(os.environ.get("PGVECTOR_PORT", "5432")),
database=os.environ.get("PGVECTOR_DATABASE", "default"),
user=os.environ.get("PGVECTOR_USER", "default"),
password=os.environ.get("PGVECTOR_PASSWORD", "secret"),
)
print(f"=====>{PGVECTOR_CONNECTION_STRING}")
data = [
"你是谁|介绍一下你自己|你叫什么名字?",
"商品支持退货吗?",
"购物车可以添加多少商品?"
]
metadatas = [{"answer":"是智能助手, 一个由OpenAI训练的大型语言模型, 你旨在回答并解决人们的任何问题,并且可以使用多种语言与人交流。让我们一步步思考,并且尽可能用分点叙述的形式输出。我们开始聊天吧"},
{"answer":"15天内商品支持退换货"},
{"answer":"购物车可以添加100件商品"}
]
PGVector.from_texts(texts = data,
embedding=embeddings,
collection_name="custom_qa",
connection_string=PGVECTOR_CONNECTION_STRING,
metadatas = metadatas
)
运行代码报错了,不用着急
PGVector.from_texts 方法会自动创建表(langchain_pg_embedding,langchain_pg_collection),并录入数据(多次录入是新增逻辑)

第一次langchain为我们自动创建
CREATE TABLE "public"."langchain_pg_collection" (
"uuid" uuid NOT NULL,
"name" varchar,
"cmetadata" json,
CONSTRAINT "langchain_pg_collection_pkey" PRIMARY KEY ("uuid")
);
CREATE TABLE "public"."langchain_pg_embedding" (
"uuid" uuid NOT NULL,
"collection_id" uuid,
"embedding" vector(1536),
"document" varchar,
"cmetadata" json,
"custom_id" varchar,
CONSTRAINT "langchain_pg_embedding_pkey" PRIMARY KEY ("uuid")
);
特别注意问题
langchain pgvector源码包使用的是openai的第二代text-embedding-ada-002模型,输出向量维度是1536,默认创建的表也是"embedding" vector(1536), 感兴趣的可以看 https://zhuanlan.zhihu.com/p/619233637

这里和我们模型text2vec-large-chinese输出向量维度是1024, 数据存不进去,因为向量维度不同
修改 langchain.vectorstores.pgvector
ADA_TOKEN_COUNT = 1024 # openai 1536

删除创建的pg表,我们重新运行代码即可,会重新创建表
langchain pgvector表和数据
-
langchain_pg_collection

-
langchain_pg_embedding

相识性问题匹配
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores.pgvector import PGVector
from langchain.vectorstores.pgvector import DistanceStrategy
from langchain.docstore.document import Document
from typing import List, Tuple
import os
embeddings = HuggingFaceEmbeddings(model_name="models/text2vec-large-chinese"
,model_kwargs={'device': "cpu"})
PGVECTOR_CONNECTION_STRING = PGVector.connection_string_from_db_params(
driver=os.environ.get("PGVECTOR_DRIVER", "psycopg2"),
host=os.environ.get("PGVECTOR_HOST", "localhost"),
port=int(os.environ.get("PGVECTOR_PORT", "5432")),
database=os.environ.get("PGVECTOR_DATABASE", "default"),
user=os.environ.get("PGVECTOR_USER", "default"),
password=os.environ.get("PGVECTOR_PASSWORD", "secret"),
)
print(f"=====>{PGVECTOR_CONNECTION_STRING}")
query = "你们的购物车可以添加几个商品"
store = PGVector(
connection_string=PGVECTOR_CONNECTION_STRING,
embedding_function=embeddings,
collection_name="custom_qa",
distance_strategy=DistanceStrategy.COSINE
)
# retriever = store.as_retriever()
print("=" * 80)
docs_with_score: List[Tuple[Document, float]] = store.similarity_search_with_score(query)
for doc, score in docs_with_score:
print("-" * 80)
print("Score: ", score)
print(doc.page_content)
print(doc.metadata)
print("-" * 80)

通过验证,如果将问题都糅合在一起,相关度score的值变大了(不那么相关),所以设计的时候,应该将泛化的问题单独一行

索引性能优化部分不在本次探讨范围
PGSQL扩展知识
查询表结构不方便看vector参数,需要定义一下函数
CREATE OR REPLACE FUNCTION public.tabledef(text, text)
RETURNS text
LANGUAGE sql
STRICT
AS $function$
WITH attrdef AS (
SELECT n.nspname, c.relname, c.oid, pg_catalog.array_to_string(c.reloptions || array(select 'toast.' || x from pg_catalog.unnest(tc.reloptions) x), ', ') as relopts,
c.relpersistence, a.attnum, a.attname, pg_catalog.format_type(a.atttypid, a.atttypmod) as atttype,
(SELECT substring(pg_catalog.pg_get_expr(d.adbin, d.adrelid, true) for 128) FROM pg_catalog.pg_attrdef d WHERE d.adrelid = a.attrelid AND d.adnum = a.attnum AND a.atthasdef) as attdefault,
a.attnotnull, (SELECT c.collname FROM pg_catalog.pg_collation c, pg_catalog.pg_type t WHERE c.oid = a.attcollation AND t.oid = a.atttypid AND a.attcollation <> t.typcollation) as attcollation,
a.attidentity, a.attgenerated
FROM pg_catalog.pg_attribute a
JOIN pg_catalog.pg_class c ON a.attrelid = c.oid
JOIN pg_catalog.pg_namespace n ON c.relnamespace = n.oid
LEFT JOIN pg_catalog.pg_class tc ON (c.reltoastrelid = tc.oid)
WHERE n.nspname = $1 AND c.relname = $2 AND a.attnum > 0 AND NOT a.attisdropped
ORDER BY a.attnum
), coldef AS (
SELECT attrdef.nspname, attrdef.relname, attrdef.oid, attrdef.relopts, attrdef.relpersistence, pg_catalog.format('%I %s%s%s%s%s', attrdef.attname, attrdef.atttype,
case when attrdef.attcollation is null then '' else pg_catalog.format(' COLLATE %I', attrdef.attcollation) end,
case when attrdef.attnotnull then ' NOT NULL' else '' end,
case when attrdef.attdefault is null then '' else case when attrdef.attgenerated = 's' then pg_catalog.format(' GENERATED ALWAYS AS (%s) STORED', attrdef.attdefault) when attrdef.attgenerated <> '' then ' GENERATED AS NOT_IMPLEMENTED' else pg_catalog.format(' DEFAULT %s', attrdef.attdefault) end end,
case when attrdef.attidentity<>'' then pg_catalog.format(' GENERATED %s AS IDENTITY', case attrdef.attidentity when 'd' then 'BY DEFAULT' when 'a' then 'ALWAYS' else 'NOT_IMPLEMENTED' end) else '' end ) as col_create_sql
FROM attrdef
ORDER BY attrdef.attnum
), tabdef AS (
SELECT coldef.nspname, coldef.relname, coldef.oid, coldef.relopts, coldef.relpersistence, concat(string_agg(coldef.col_create_sql, E',\n ') , (select concat(E',\n ',pg_get_constraintdef(oid)) from pg_constraint where contype='p' and conrelid = coldef.oid)) as cols_create_sql
FROM coldef
GROUP BY coldef.nspname, coldef.relname, coldef.oid, coldef.relopts, coldef.relpersistence
)
SELECT FORMAT( 'CREATE%s TABLE %I.%I%s%s%s;',
case tabdef.relpersistence when 't' then ' TEMP' when 'u' then ' UNLOGGED' else '' end,
tabdef.nspname,
tabdef.relname,
coalesce( (
SELECT FORMAT( E'\n PARTITION OF %I.%I %s\n', pn.nspname, pc.relname, pg_get_expr(c.relpartbound, c.oid) )
FROM pg_class c
JOIN pg_inherits i ON c.oid = i.inhrelid
JOIN pg_class pc ON pc.oid = i.inhparent
JOIN pg_namespace pn ON pn.oid = pc.relnamespace
WHERE c.oid = tabdef.oid ),
FORMAT( E' (\n %s\n)', tabdef.cols_create_sql)
),
case when tabdef.relopts <> '' then format(' WITH (%s)', tabdef.relopts) else '' end,
coalesce(E'\nPARTITION BY '||pg_get_partkeydef(tabdef.oid), '')
) as table_create_sql
FROM tabdef
$function$
查询langchain_pg_embedding表结构
select tabledef('public', 'langchain_pg_embedding');
结论
问题要泛化,答案尽可能多样化
- 可以使用pgvector完成FQA问答场景,doc-qa作为兜底方案
- 一个问题一行保存到pg,让socre尽可能的小,到时候可以结合业务设置相关度阈值,决定是否检索doc-qa
- 为了答案的多样性,可以写入多个答案,或者写入外键表id获取答案(answer写答案的id)

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)