python深度学习实现自编码器Autoencoder神经网络异常检测心电图ECG时间序列
原文链接:http://tecdat.cn/?p=25410原文出处:拓端数据部落公众号通过训练具有小中心层的多层神经网络重构高维输入向量,可以将高维数据转换为低维代码。这种神经网络被命名为自编码器Autoencoder。自编码器是非线性降维技术用于特征的无监督学习,它们可以学习比主成分分析效果更好的低维代码,作为降低数据维数的工具。异常心跳检测如果提供了足够的类似于某种底层模式的训练数据,我们可
最近我们被客户要求撰写关于深度学习的研究报告,包括一些图形和统计输出。
通过训练具有小中心层的多层神经网络重构高维输入向量,可以将高维数据转换为低维代码。这种神经网络被命名为自编码器Autoencoder。
自编码器是非线性降维 技术用于特征的无监督学习,它们可以学习比主成分分析效果更好的低维代码,作为降低数据维数的工具。
异常心跳检测
如果提供了足够的类似于某种底层模式的训练数据,我们可以训练网络来学习数据中的模式。异常测试点是与典型数据模式不匹配的点。自编码器在重建这些数据时可能会有很高的错误率,这表明存在异常。
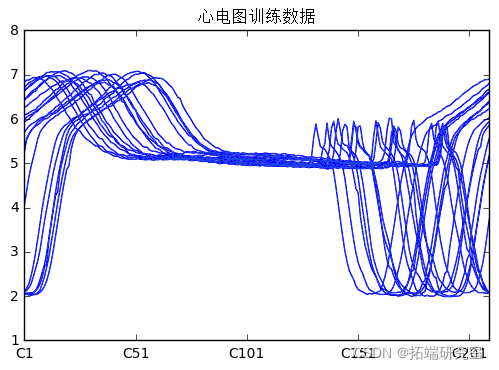
该框架用于使用深度自编码器开发异常检测演示。该数据集是心跳的 ECG 时间序列,目标是确定哪些心跳是异常值。训练数据(20 个“好”心跳)和测试数据(为简单起见附加了 3 个“坏”心跳的训练数据),如下所示。每行代表一个心跳。
init()
PATH = os.path.expanduser("~/")import_file(PATH + "train.csv")
import_file(PATH + "test.csv")![]()
探索数据集。
tra.shape# 将框架转置,将时间序列作为一个单独的列来绘制。
plot(legend=False); # 不显示图例
在训练数据中,我们有 20 个时间序列,每个序列有 210 个数据点。请注意,所有线条都很紧凑并且形状相似。重要的是要记住,在使用自编码器进行训练时,您只想使用 VALID 数据。应删除所有异常。
现在让我们训练我们的神经网络
Estimator(
activation="Tanh",
hidden=[50],
)
model.trainmodel

我们的神经网络现在能够对 时间序列进行 编码。
现在我们尝试使用异常检测功能计算重建误差。这是输出层和输入层之间的均方误差。低误差意味着神经网络能够很好地对输入进行编码,这意味着是“已知”情况。高误差意味着神经网络以前没有见过该示例,因此是异常情况。
anomaly(test )现在的问题是:哪个 test 时间序列最有可能是异常?
我们可以选择错误率最高的前 N 个
df['Rank'] = df['MSE'].ranksorted

dfsorted[MSE'] > 1.0

datT.plot
daT[anindex].plot(color='red');
带监督微调的无监督预训练
有时,未标记的数据比标记的数据多得多。在这种情况下,在未标记数据上训练自编码器模型,然后使用可用标签微调学习模型是有意义的。
结论
在本教程中,您学习了如何使用自编码器快速检测时间序列异常。


开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 0
0 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)