python struct模块
struct模块提供了用于在字节字符串和Python原生数据类型之间的转换,可以用于处理存储在文件中或从网络连接中存储的二进制数据,以及其他数据源。按照给定的格式fmt,将数据转换成字节流,并将字节流写入以offset开始的buffer中( buffer为可写的缓冲区,可用array模块)处理不定长的内容的主要思想是把长度和内容一起打包,解包时先解析内容的长度,然后再读取正文。按照给定的格式fmt
struct模块
struct模块提供了用于在字节字符串和Python原生数据类型之间的转换,可以用于处理存储在文件中或从网络连接中存储的二进制数据,以及其他数据源。
struct中的pack函数把任意数据类型变成bytes
-
pack(fmt,v1,v2…) ->string
按照给定的格式fmt, 将数据转换为字节流,并将该字节流返回
-
pack_into(fmt,buffer,offset,v1,v2)->None
按照给定的格式fmt,将数据转换成字节流,并将字节流写入以offset开始的buffer中( buffer为可写的缓冲区,可用array模块)
-
unpack(fmt,v1,v2)->tuple
按照给定的格式fmt,解析字节流,并返回解析结果
-
pack_from(fmt,buffer,offset)->tuple
按照给定的格式fmt,解析以offset开始的缓冲区,并返回解析结果
-
calcsize(fmt)->int
计算给定的格式fmt占用多少字节的内存,注意对齐方式
打包和解包
struct 支持将数据pack(打包成字节串),并能从字节串中unpack(解包)出数据。
import struct
import binascii
values = (1,'ab'.encode("utf-8"),2.7)
s = struct.Struct("I 2s f") # 指定格式
packed_data = s.pack(*values)
print(" 原始值 : ", values)
print(" 格式符 : ", s.format)
print(" 占用字节 : ", s.size)
print(" 打包结果: ", binascii.hexlify(packed_data))
# binascii.hexlify()将打包的值转换为十六进制字节序列显示出来
格式符中的空格用于分隔各个指示器(indicators), 在编译格式时会被忽略
import struct
values = (1,'ab'.encode("utf-8"),2.7)
s = struct.Struct("I 2s f")
packed_data = s.pack(*values)
unpacked_data = s.unpack(packed_data)
print(unpacked_data)
# 没有分隔符
# 2个整数,1个有3个字符的字符串,一个整数
a = struct.pack("2I3sI", 12, 34, b"abc", 56)
b = struct.unpack("2I3sI", a)
print('a:',a)
print('b:',b)
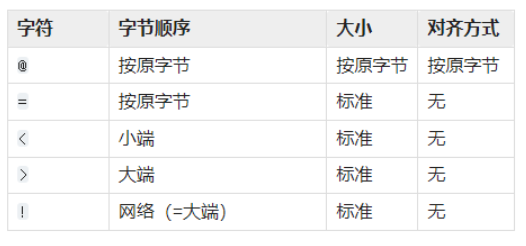
字节顺序和对齐
默认情况下,pack使用本地C库的字节顺序来编码的。格式化字符串的第一个字符可以用来表示填充数据的字节顺序、大小和对齐方式。
一般情况下,主机字节序 是 小端模式,网络字节序 是 大端模式

如果格式符中没有设置这些,那么默认将使用 @。
print(struct.calcsize("2I3sI"))# 16
上面的三个整型加一个 3 字符的字符串一共占用了 16 个字节
1 个 int 4 字节,3 个字符 3 字节
在 struct的打包过程中,根据特定类型的要求,必须进行字节对齐。
由于默认 unsigned int 型占用四个字节,因此要在字符串的位置进行4字节对齐,因此即使是 3 个字符的字符串也要占用 4 个字节。
不定长数据pack
处理不定长的内容的主要思想是把长度和内容一起打包,解包时先解析内容的长度,然后再读取正文
# 对于变长字符串在处理时把字符串的长度当成数据的内容一起打包
s = bytes(s)
data = struct.pack("I%ds"%(len(s),),len(s),s)
# 解包变长字符串
int_size = struct.calcsize("I")
i = struct.unpack("I",data[:int_size])
data = struct.unpack("%ds"%(i[0],),data[int_size:])
# 解包变长字符串时先解包内容的长度,再根据内容的长度解包数据
格式符

缓冲区
可以通过避免为每个打包结构分配新缓冲区的开销来优化
pack_into()和unpack_from()方法支持直接写入预先分配的缓冲区。
-
pack_into(format, buffer, offset, v1, v2, …)
-
unpack_from(format, buffer, offset=0)
在组包拆包时,可以指定所需的偏移量,这让组包拆包变得更加灵活。
import ctypes
import struct
s = struct.Struct('I 2s f')
sbuf = struct.Struct('I 2s f')
values = (1, 'ab'.encode('utf-8'), 2.7)
s.pack_into(sbuf, 0, *values)
res = s.unpack_from(sbuf, 0)
参考

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 1
1 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)