python-自动化篇-办公-一键将word中的表格提取到excel文件中
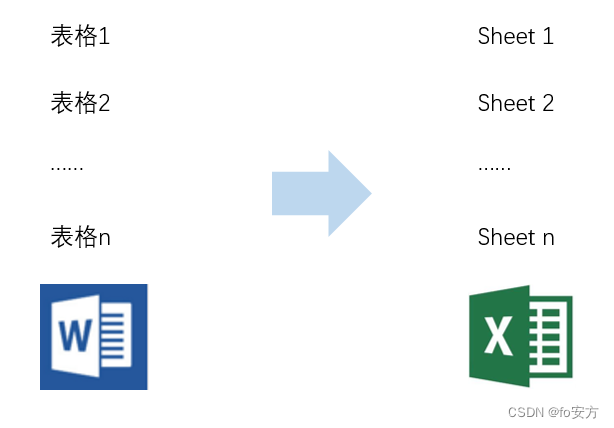
工作中,经常需要将Word文档中的表格粘贴到Excel文件中,以便汇总及分析。一个一个复制粘贴,非常不方便,还是Python自动化操作,省心省力。要求如下图所示,即将word中的所有表格,转存到excel文件的工作表里。以上,先导入相关模块。os用于获取待处理word文件的路径;docx用于读取word文件;openpyxl用于操作excel文件。将所有word文件的路径存入列表files中。然后
文章目录
工作中,经常需要将Word文档中的表格粘贴到Excel文件中,以便汇总及分析。一个一个复制粘贴,非常不方便,还是Python自动化操作,省心省力。要求如下图所示,即将word中的所有表格,转存到excel文件的工作表里。

import os
from docx import Document
from openpyxl import Workbook
#获取待处理的文件的路径
path='word文件' #文件所在文件夹
files = [path+"\\"+i for i in os.listdir(path)] #获取文件夹下的文件名,并拼接完整路径
for file in files:
doc = Document(file)
wb = Workbook()
wb.remove(wb.worksheets[0])#删除工作簿自带的工作表
for index, table in enumerate(doc.tables, start=1): #从1开始给表格编号
ws = wb.create_sheet(f"Sheet{index}")#创建新工作表,以"Sheet" + word中表格的编号命名
for i in range(len(table.rows)): #遍历word中表格的所有行
row_data = [] #储存表格中每行的数据
for j in range(len(table.columns)): #遍历word中表格的所有列
row_data.append(table.cell(i,j).text)
ws.append(row_data) #每取一行就写入数据到Excel表的行中
wb.save("excel文件\\{}.xlsx".format(file.split("\\")[1].split(".")[0])) #保存excel文件
以上,先导入相关模块。os用于获取待处理word文件的路径;docx用于读取word文件;openpyxl用于操作excel文件。将所有word文件的路径存入列表files中。然后逐个通过Document打开,并使用Workbook()创建Excel工作簿,以接收来自于word文件中的数据。因为创建工作簿后,Excel会自动新建一个名为"Sheet"的空白表格,但我们想用自己命名的表格,所以使用remove()将自动新建的表删掉了。
然后遍历word文件中的所有表格,并读取其中的数据。由于我们想让Excel工作簿中的表的序号与Word中的一致,所以使用enmuerate给Word中的表格进行编号,start=1表示从1开始,不然会默认从0开始。
随后使用wb.create_sheet新建一个工作表,其表名就用字符串"Sheet"加上上面的编号。其中f"{}"是格式化字符串方法,从Python 3.6开始加入标准库,是一种更灵活好用的方法。如下有四种方式处理字符串,结果完全一样,不过第一种最好用,墙裂推荐。
name = "Trump"
age = 70
f"你好, {name}, 你的年龄是{age}岁."
‘你好, Trump, 你的年龄是70岁.’
"你好, {}, 你的年龄是{}岁.".format(name,age)
‘你好, Trump, 你的年龄是70岁.’
"你好, %s, 你的年龄是%s岁." % (name, age)
‘你好, Trump, 你的年龄是70岁.’
"你好, " +name +", 你的年龄是" + str(age) + "岁."
‘你好, Trump, 你的年龄是70岁.’
然后遍历word中表格的所有行和列,将每行的数据存入列表row_data,然后通过append方法马上增加到Excel表中最后一个数据下面。append方法可以将一个列表中的所有元素写入到excel表的一行,一个元素占一个单元格(如下图),够智能的吧?

处理完一个word文件,就保存一下数据。为了使保存的excel文件名与word文件名一致,使用了file.split("\\")[1].split(".")[0])。其中file的内容如下。file.split("\\")[1]就得到了’采购报告.docx’,'采购报告.docx'.split(".")[0]就得到了“采购报告”。
file
‘你好, Trump, 你的年龄是70岁.’
‘你好, Trump, 你的年龄是70岁.’
‘你好, Trump, 你的年龄是70岁.’
‘你好, Trump, 你的年龄是70岁.’
‘word文件\采购报告.docx’
file.split("\\")[1]
‘采购报告.docx’
'采购报告.docx'.split(".")[0]
‘采购报告’
结果图如下。word文件中有多少个表格,就会在excel文件中生成多少个sheet。而且,如果在word文件中有合并单元格,那到excel文件中,这些单元格会拆分,并填充相同的内容,更利于数据分析。当然,结果excel文件中的格式就不是那么好看了,需要手动调整一下。

代码
import os
from docx import Document
from openpyxl import Workbook
#获取待处理的文件的路径
path='word文件' #文件所在文件夹
files = [path+"\\"+i for i in os.listdir(path)] #获取文件夹下的文件名,并拼接完整路径
for file in files:
doc = Document(file)
wb = Workbook()
wb.remove(wb.worksheets[0])#删除工作簿自带的工作表
for index, table in enumerate(doc.tables, start=1): #从1开始给表格编号
ws = wb.create_sheet(f"Sheet{index}")#创建新工作表,以"Sheet" + word中表格的编号命名
for i in range(len(table.rows)): #遍历word中表格的所有行
row_data = [] #储存表格中每行的数据
for j in range(len(table.columns)): #遍历word中表格的所有列
row_data.append(table.cell(i,j).text)
ws.append(row_data) #每取一行就写入数据到Excel表的行中
wb.save("excel文件\\{}.xlsx".format(file.split("\\")[1].split(".")[0])) #保存excel文件


开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 39
39 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)