
大数据实战项目-招聘网站职位分析
本项目是以国内某互联网招聘网站全国范围内的大数据相关招聘信息作为基础信息,其招聘信息能较大程度地反映出市场对大数据相关职位的需求情况及能力要求,利用这些招聘信息数据通过大数据分析平台重点分析一下几点:分析大数据职位的区域分布情况分析大数据职位薪资区间分布情况分析大数据职位相关公司的福利情况分析大数据职位相关公司技能要求情况。
目录
第一章:项目概述
1.1项目需求和目标
1.2预备知识
1.3项目架构设计及技术选取
1.4开发环境和开发工具
1.5项目开发流程
第二章:搭建大数据集群环境
2.1安装准备
2.2Hadoop集群搭建
2.3Hive安装
2.4Sqoop安装
第三章:数据采集
3.1知识概要
3.2分析与准备
3.3采集网页数据
第四章:数据预处理
4.1分析预处理数据
4.2设计数据预处理方案
4.3实现数据的预处理
第五章:数据分析
5.1数据分析概述
5.2Hive数据仓库
5.3分析数据
第六章:数据可视化
6.1平台概述
6.2数据迁移
6.3平台环境搭建
6.4实现图形化展示功能
第一章:项目概述
1.1项目需求
项目需求:
本项目是以国内某互联网招聘网站全国范围内的大数据相关招聘信息作为基础信息,其招聘信息能较大程度地反映出市场对大数据相关职位的需求情况及能力要求,利用这些招聘信息数据通过大数据分析平台重点分析一下几点:
分析大数据职位的区域分布情况
分析大数据职位薪资区间分布情况
分析大数据职位相关公司的福利情况
分析大数据职位相关公司技能要求情况
1.2预备知识
知识储备:
- JAVA面向对象编程思想
- Hadoop、Hive、Sqoop在Linux环境下的基本操作
- HDFS与MapReduce的Java API程序开发
- 大数据相关技术,如Hadoop、HIve、Sqoop的基本理论及原理
- Linux操作系统Shell命令的使用
- 关系型数据库MySQL的原理,SQL语句的编写
- 网站前端开发相关技术,如HTML、JSP、JQuery、CSS等
- 网站后端开发框架Django或者Spring+SpringMVC+MyBatis整合使用
- Eclipse开发工具的应用
- Maven项目管理工具的使用
1.3项目架构设计及技术选取

1.4开发环境和开发工具
系统环境主要分为开发环境(Windows)和集群环境(Linux)
开发工具:Eclipse、JDK、Maven、VMware Workstation
集群环境:Hadoop、Hive、Sqoop、MySQL
web环境:Tomcat、Spring、Spring MVC、MyBatis、Echarts
1.5项目开发流程
1.搭建大数据实验环境
(1)Linux 系统虛拟机的安装与克隆
(2)配置虛拟机网络与 SSH 服务
(3)搭建 Hadoop 集群
(4)安装 MySQL 数据库
(5)安装 Hive
(6)安装 Sqoop
2.编写网络爬虫程序进行数据采集
(1)准备爬虫环境
(2)编写爬虫程序
(3)将爬取数据存储到 HDFS
3.数据预处理
(1)分析预处理数据
(2)准备预处理环境
(3)实现 MapReduce 预处理程序进行数据集成和数据转换操作
(4)实现 MapReduce 预处理程序的两种运行模式
4.数据分析
(1)构建数据仓库
(2)通过 HSQL 进行职位区域分析
(3)通过 HSQL 进行职位薪资分析
(4)通过 HSQL 进行公司福利标签分析
(5)通过 HSQL 进行技能标签分析
5.数据可视化
(1)构建关系型数据库
(2)通过 Sqoop 实现数据迁移
(3)创建 Maven 项目配置项目依赖的信息
(4)编辑配置文件整合 SSM 框架
(5)完善项目组织框架
(6)编写程序实现职位区域分布展示
(7)编写程序实现薪资分布展示
(8)编写程序实现福利标签词云图
(9)预览平台展示内容
(10)编写程序实现技能标签词云图
第二章:搭建大数据集群环境
2.1安装准备
虚拟机安装与克隆(克隆方法选择创建完整克隆)三台网络连接成功的虚拟机即可
虚拟机网络配置
#查看IP
ifconfig
#编辑网络
vi /etc/sysconfig/network-scripts/ifcfg-ens33
#重启
service network restart
#配置ip和主机名映射
vi /etc/hosts
SSH服务配置
#SSH安装命令
yum -y install openssh openssh-server
#查看SSH进程
ps -ef | grep ssh
#生成密钥对
ssh-keygen -t rsa
#复制公钥文件三台机器
ssh-copy-id 主机名
scp -r /root/.ssh/* root@主机名:/root/.ssh/2.2Hadoop集群搭建
安装Java环境
1.安装rz,通过rz命令上传安装包
yum install lrzsz
2.解压
tar -zxvf jdk-8u181-linux-x64.tar.gz -C /usr/local
3.修改名字
mv jdk1.8.0_181/ jdk
4.配置环境变量
vi /etc/profile
#JAVA_HOME
export JAVA_HOME=/usr/local/jdk
export PATH=$PATH:$JAVA_HOME/bin
5.初始化环境变量
source /etc/profile
6.验证配置
java -version
这样,Hadoop 所需的 Java 运行环境就安装好了。
安装hadoop
1.通过rz命令上传安装包
2.解压
tar -zxvf hadoop2.7.1.tar.gz -C /usr/local
3.修改名字
mv hadoop2.7.1/ hadoop
4.配置环境变量
vi /etc/profile
#HADOOP_HOME
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
5.初始化环境变量
source /etc/profile
6.验证配置
hadoop version
- Hadoop集群配置
步骤:
- 配置文件
- 修改文件(hadoop-env.sh、yarn-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml)
- 修改slaves文件并将集群主节点的配置文件分发到其他主节点
1.cd hadoop/etc/hadoop
2.vi hadoop-env.sh
#配置JAVA_HOME
export JAVA_HOME=/usr/local/jdk3.vi yarn-env.sh
#配置JAVA_HOME(记得去掉前面的#注释,注意别找错地方)
4.vi core-site.xml
#配置主进程NameNode运行地址和Hadoop运行时生成数据的临时存放目录
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://一号主机名:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
5.vi hdfs-site.xml
#配置Secondary NameNode节点运行地址和HDFS数据块的副本数量
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>二号主机名:50090</value>
</property>
</configuration>
6.cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
#配置MapReduce程序在Yarns上运行
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
7.vi yarn-site.xml
#配置Yarn的主进程ResourceManager管理者及附属服务mapreduce_shuffle
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>一号主机名</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
8.vi slaves
centos72 //(一号主机名)centos73 //(二号主机名)
centos74 //(三号主机名)
9.scp /etc/profile root@hadoop2:/etc/profile
scp /etc/profile root@hadoop3:/etc/profile
scp -r /usr/local/* root@hadoop2:/usr/local/
scp -r /usr/local/* root@hadoop3:/usr/local/
10.记得在hadoop2、hadoop3初始化
source /etc/profile
Hadoop集群测试
格式化文件系统
启动hadoop集群
验证各服务器进程启动情况
#1.格式化文件系统
初次启动HDFS集群时,对主节点进行格式化处理
hdfs namenode -format
或者hadoop namenode -format
#2.进入hadoop/sbin/
cd /usr/local/hadoop/sbin/
#3.主节点上启动HDFSNameNode进程
hadoop-daemon.sh start namenode
#4.每个节点上启动HDFSDataNode进程
hadoop-daemon.sh start datanode
#5.主节点上启动YARNResourceManager进程
yarn-daemon.sh start resourcemanager
#6.每个节点上启动YARNodeManager进程
yarn-daemon.sh start nodemanager
#7.规划节点上启动SecondaryNameNode进程
hadoop-daemon.sh start secondarynamenode
#8.jps(5个进程)

2.3Hive安装
安装MySQL服务(Centos现在使用mariadb代替MySQL,mariadb是MySQL下面的一个分支)
#安装mariadb
yum install mariadb-server mariadb
#启动服务
systemctl start mariadb
systemctl enable mariadb
#切换到mysql数据库
use mysql;
#修改root用户密码
update user set password=PASSWORD('123456') where user = 'root';
#设置允许远程登录
grant all privileges on *.* to 'root'@'%'
identified by '123456' with grant option;
#更新权限表
flush privileges;

安装hive
#1.解压
tar -zxvf apache-hive-1.2.2-bin.tar.gz -C /usr/local
#2.修改名字
mv apache-hive-1.2.2-bin/ hive
#3.配置文件
cd /hive/conf
cp hive-env.sh.template hive-env.sh
vi hive-env.sh(修改 export HADOOP_HOME=/usr/local/hadoop)
#4.
vi hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
</configuration>
#5.上传mysql驱动包
- tar -zxvf mysql-connector-java-5.1.40.jar -C use/local
- cd /usr/local/mysql-connector-java-5.1.40.jar
- cp mysql-connector-java-5.1.40.jar /usr/local/hive/lib/
- #6.配置环境变量
- vi /etc/profile
- #添加HIVE_HOME
- export HIVE_HOME=/usr/local/hive
- export PATH=$PATH:$HIVE_HOME/bin
- source /etc/profile
- #7.启动hive
- cd ../bin/
- ./hive


2.4Sqoop安装
#1.解压
tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /usr/local
#2.修改名字
mv sqoop-1.4.7.bin__hadoop-2.6.0/ sqoop
#3.配置
cd sqoop/conf/
cp sqoop-env-template.sh sqoop-env.sh
vi sqoop-env.sh
修改
export HADOOP_COMMON_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=/usr/local/hadoop
export HIVE_HOME=/usr/local/hive
#4.配置环境变量
vi /etc/profile
#添加SQOOP_HOME
export SQOOP_HOME=/usr/local/sqoop
export PATH=$PATH:$SQOOP_HOME/bin
source /etc/profile
#5.效果测试
cd ../lib
rz(mysql-connector-java-5.1.40.jar)#上传jar包到lib目录下
cd ../bin/
sqoop list-databases --connect jdbc:mysql://127.0.0.1:3306/ --username root -P
#(sqoop list-database用于输出连接的本地MySQL数据库中的所有数据库,如果正确返回指定地址的MySQL数据库信息,说明Sqoop配置完成)

第三章:数据采集
介绍
本次采集使用python进行数据采集,采集网站为拉勾网里面的招聘信息,在早些年拉勾网返回数据是直接返回,但为防止市面爬虫过度采集数据影响服务器,拉钩网也是做了一定的反爬技术,现在的拉钩网反爬主要是以请求参数加密以及返回的数据不再是明文而是加密过后的密文数据,我们需要构造请求时携带的请求参数加密以及将返回过来的密文数据进行解密,爬取过程主要用到以下几个模块;
requests
nodejs
execjs2
crypto-js (JS中所要用到的库)
网页分析
这里我们可以观察到我们发送请求时需要携带一个参数data而且切换页面后我们也可以发现这个参数是改变的

这里我们可以观察到现在拉钩返回的数据是经过加密后的数据

接下来就是构造请求参数加密以及返回返回参数解密了,因为解析源代码步骤较多这里我仅挑主要步骤进行演示
这里是求情参数加密的位置我们需要扣取出并且补充该部分JS代码进行构造data的内容
调试后我们可以观察到t值为我们所需要获取的页面信息等我们需要传入页面信息然后通过这段JS代码加密获得我们请求携带参数data


这里是我们解密返回参数解密的部分我们需要扣取补充出这段代码从而对服务器返回的加密参数进行解密,这里t值为返回的加密数据

这里是完整的加密解密
const CryptoJS = require('crypto-js')
//请求参数加密
t = '{"first":"true","needAddtionalResult":"false","city":"全国","pn":"1","cl":"false","fromSearch":"true","labelWords":"sug","suginput":"大数据","kd":"大数据"}'
Pt = CryptoJS.enc.Utf8.parse("c558Gq0YQK2QUlMc")
,
It = function (t) {
kt = CryptoJS.enc.Utf8.parse("tlZvARmBN47KJOQLze8L5iv9BCS59Fh2"),
t = CryptoJS.enc.Utf8.parse(t);
t = CryptoJS.AES.encrypt(t, kt, {
iv: Pt,
mode: CryptoJS.mode.CBC,
padding: CryptoJS.pad.Pkcs7
});
return t.toString()
};
console.log(It(t))
//返回参数解密
Mt = function (t) {
kt = CryptoJS.enc.Utf8.parse("tlZvARmBN47KJOQLze8L5iv9BCS59Fh2");
t = CryptoJS.AES.decrypt(t, kt, {
iv: Pt,
mode: CryptoJS.mode.CBC,
padding: CryptoJS.pad.Pkcs7
}).toString(CryptoJS.enc.Utf8);
try {
t = JSON.parse(t)
} catch (t) {
}
return t
}
data2 = '返回的加密数据'
console.log(Mt(data2))运行结果如下,我们可以看到前两行为我们的data加密内容,而下面及是我们对返回的加密内容进行解密后的结果,网页数据就在[object]中
 接下来就是编写python代码对拉勾网进行爬取这里不再过多解释python代码,代码如下
接下来就是编写python代码对拉勾网进行爬取这里不再过多解释python代码,代码如下
import requests
import execjs
import requests
import random
from fake_useragent import UserAgent
import json
ua = UserAgent()
random_user_agent = ua.random
print(random_user_agent)
import requests
cookies = {
'_ga': 'GA1.2.1272972245.1715999320',
'user_trace_token': '20240518102839-c8c3409f-a363-4e71-8976-ef1211ef7347',
'LGUID': '20240518102839-4f66b67e-e239-4f52-bc0a-d50afd142d85',
'LG_HAS_LOGIN': '1',
'gate_login_token': 'v1####26a4b7ccbb950eab38a48546a6d39dc708718eebe4b14033f933331c848644b1',
'LG_LOGIN_USER_ID': 'v1####24c2a150d44647d4ea50267acddeec4d77c8c91f956f2b83d0be8d851367fe47',
'showExpriedIndex': '1',
'showExpriedCompanyHome': '1',
'showExpriedMyPublish': '1',
'hasDeliver': '0',
'privacyPolicyPopup': 'false',
'index_location_city': '%E5%85%A8%E5%9B%BD',
'__lg_stoken__': '96b1b539a2e83df930182b19e601e0f6b8a2ed65c92bad21f4e8b8bc0211b326e0b46dd159349f9af115bf96da3128d392d0b9145644d30cd78c561289666ed9e7563ec8f8c5',
'SEARCH_ID': '294e3851f8da4b1697cdda1563b6a344',
'Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6': '1717683836,1717723299,1717768330,1718011140',
'_gid': 'GA1.2.1941430621.1718011140',
'_ga_DDLTLJDLHH': 'GS1.2.1718011141.6.0.1718011141.60.0.0',
'_putrc': '2F6168008B97CCFB123F89F2B170EADC',
'JSESSIONID': 'ABAABJAABIEABFB7A606A68EEAC32ACFFD2E93760CC2E21',
'login': 'true',
'unick': '%E7%94%A8%E6%88%B71909',
'WEBTJ-ID': '20240611120634-1900579eabe153c-03240b3817f78-26001c51-1327104-1900579eabf1f86',
'sensorsdata2015session': '%7B%7D',
'X_HTTP_TOKEN': '83546a1e60db0aac7588708171d2863746c2bb1e13',
'X_MIDDLE_TOKEN': '279aea30d77d3186278ff1a5eca2573a',
'sensorsdata2015jssdkcross': '%7B%22distinct_id%22%3A%2227016941%22%2C%22first_id%22%3A%2218f89878889581-08e5b533acda7d-4c657b58-1327104-18f8987888a19d2%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_utm_source%22%3A%22PC_SEARCH%22%2C%22%24os%22%3A%22Windows%22%2C%22%24browser%22%3A%22Chrome%22%2C%22%24browser_version%22%3A%22125.0.0.0%22%7D%2C%22%24device_id%22%3A%2218f89878889581-08e5b533acda7d-4c657b58-1327104-18f8987888a19d2%22%7D',
}
headers = {
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Connection': 'keep-alive',
'Origin': 'https://www.lagou.com',
'Referer': 'https://www.lagou.com/wn/jobs?pn=1&cl=false&fromSearch=true&labelWords=sug&suginput=%E5%A4%A7%E6%95%B0%E6%8D%AE&kd=%E5%A4%A7%E6%95%B0%E6%8D%AE',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36',
'X-K-HEADER': 'dHursI0y13O3d2j5G0mDSFSiY+OYzMwNOqXcjVVxOnrGTnyFc8ARUQlthxQ0D6IG',
'X-S-HEADER': 'ydN1aAIqiRudYJ+1ZKbiOKB3R8Ksh7ZfE0+T4mU1/M3PS9uduf8y8D+tfayd+V6KaQwgkyRLFTNAYo2hXHvHJmjZaqxkrdrPxHfRNjoi3rS5EcM7GhdCzn4SXeQdghwW1KXyB8bC+ZSgDpoMWw5yDQ==',
'X-SS-REQ-HEADER': '{"secret":"dHursI0y13O3d2j5G0mDSFSiY+OYzMwNOqXcjVVxOnrGTnyFc8ARUQlthxQ0D6IG"}',
'accept': 'application/json, text/plain, */*',
'content-type': 'application/x-www-form-urlencoded; charset=UTF-8',
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="125", "Google Chrome";v="125"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'traceparent': '00-9c8ecced61191023fcafbd750d5c222c-f91e220a1add9ae0-01',
'x-anit-forge-code': '3cf80cfc-4565-4bd8-b0c3-413ff42504ac',
'x-anit-forge-token': '7952b512-1d43-4c2e-b9c8-5d5d8a9c129d',
}
for page in range(1,31):
params = {
'needAddtionalResult': 'false',
}
ra_data = '{"first":"true","needAddtionalResult":"false","city":"全国","pn":"' + str(page) + '","cl":"false","fromSearch":"true","labelWords":"sug","suginput":"大数据","kd":"大数据"}'
data_en = execjs.compile(open('参数解密加密.js','r',encoding='utf-8').read()).call('It',ra_data)
print(data_en)
data = {
'data': data_en,
}
response = requests.post('https://www.lagou.com/jobs/v2/positionAjax.json', cookies=cookies, headers=headers, data=data)
print(response.text)
ra_reponse_text = response.json()['data']
reponse_rext_en = execjs.compile(open('参数解密加密.js','r',encoding='utf-8').read()).call('Mt',ra_reponse_text)
print(reponse_rext_en)
result_json = json.dumps(reponse_rext_en['content']['positionResult']['result'], ensure_ascii=False, indent=4)
with open(f'./data/page{page}.csv','w',encoding='utf-8') as f:
f.write(result_json)
for index in reponse_rext_en['content']['positionResult']['result']:
print(index) 
获取到的数据可以在Python代码中直接上传到HDFS上也可以将文件上传到HDFS上面,这里数据较少我采用的直接将文件上传到了HDFS上面
hadoop fs -put data /Jobdata

第四章:数据预处理
4.1分析预处理数据
查看数据结构内容,格式化数据
本项目主要分析的内容是薪资、福利、技能要求、职位分布这四个方面。
- salary(薪资字段的数据内容为字符串形式)
- city(城市字段的数据内容为字符串形式)
- skillLabels(技能要求字段的数据内容为数组形式)
- companyLabelList(福利标签数据字段 数据形式为数组);positionAdvantage(数据形式为字符串)
linux安装Pycharm
sudo tar -zxvf pycharm-专业版-xxx.x.x.tar.gz -C /usr/local
启动Pycharm
cd /usr/local/pycharm
./bin/pycharm.sh
专业版可暂时选择三十天
数据清洗处理(Python)
import codecs
import pandas as pd
import json
import csv
from pyhdfs import HdfsClient
client = HdfsClient(hosts='centos72:50070', user_name='root')
hdfs_path = '/output'
#with client.open('/Jobdata/page1.csv',) as reader:
# content = reader.read()
# print(content)
#decode = codecs.decode(content,'utf-8')
#print(decode)
all_job_data = []
for page in range(1, 31):
with client.open(f'/Jobdata/page{page}.csv', ) as reader:
content = reader.read()
# print(content)
decode = codecs.decode(content, 'utf-8')
data = json.loads(decode)
if isinstance(data, list):
df = pd.DataFrame(data)
# 数据处理步骤保持不变...
df['salary'] = df['salary'].str.replace('k', '', regex=False)
df['companyLabelList'] = df['companyLabelList'].apply(lambda x: '-'.join(x) if x else '')
df['positionAdvantage'] = df['positionAdvantage'].str.replace(r'[,\s,、]+', '-', regex=True).fillna('')
df['combined_labels'] = (df['companyLabelList'] + '-' + df['positionAdvantage']).str.replace('^-',
'').str.replace(
'-$', '')
df['skillLables'] = df['skillLables'].apply(lambda x: '-'.join(x) if x else '')
df['jobResultData'] = df['city'] + ',' + df['salary'] + ',' + df['combined_labels'] + ',' + df[
'skillLables']
# 将处理后的'jobResultData'添加到列表中
all_job_data.extend(df['jobResultData'].tolist())
print(all_job_data)
# 将所有数据写入到一个Pandas DataFrame
all_job_data_df = pd.DataFrame({'jobResultData': all_job_data})
print(all_job_data_df)
# 将DataFrame转换为CSV字符串
csv_data = all_job_data_df.to_csv(index=False,quoting=csv.QUOTE_MINIMAL).encode('utf-8')
# 指定HDFS上的文件路径
hdfs_path = '/output'
# 写入HDFS
# 如果文件已存在并且需要覆盖,则先删除
if client.exists(hdfs_path):
client.delete(hdfs_path, recursive=False)
# 创建文件句柄,注意这里没有直接传入data参数
client.create(hdfs_path,csv_data)
print("所有页面的'jobResultData'已成功写入到HDFS中")
这样存储到HDFS的数据为 (带双引号,我们需将双引号去除,我们可以选择将文件在另一个程序保存为txt文件上传到HDFS上)

第五章:数据分析
5.1数据分析概述
本项目通过使用基于分布式文件系统的Hive对招聘网站的数据进行分析
5.2Hive数据仓库
Hive是建立在Hadoop分布式文件系统上的数据仓库,它提供了一系列工具,能够对存储在HDFS中的数据进行数据提取、转换和加载(ETL),是一种可以存储、查询和分析存储在Hadoop中的大规模的工具。Hive可以将HQL语句转为MapReduce程序进行处理。
本项目是将Hive数据仓库设计为星状模型,由一张事实表和多张维度表组成。
事实表(ods_jobdata_origin)主要用于存储MapReduce计算框架清洗后的数据

维度表(t_salary_detail)主要用于存储薪资分布分析的数据

维度表(t_company_detail)主要用于存储福利标签分析的数据
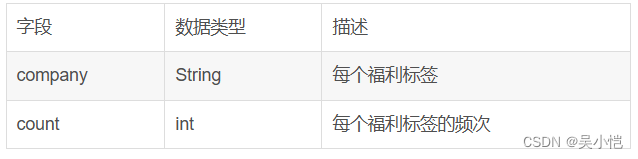
维度表(t_city_detail)主要用于存储城市分布分析的数据
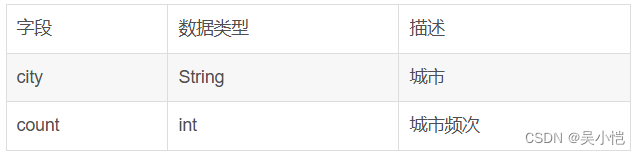
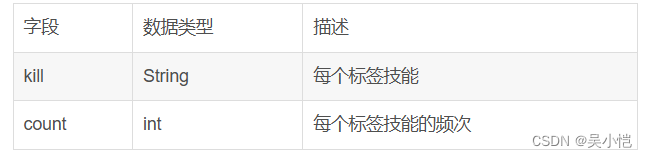
维度表(t_kill_detail)主要用于存储技能标签分析的数据
实现数据仓库
启动Hadoop集群后,在主节点hadoop1启动Hive
将HDFS上的预处理数据导入到事实表ods_jobdata_origin中
--创建数据仓库 jobdata
create database jobdata;
use jobdata;
--创建事实表 ods_jobdata_origin
create table ods_jobdata_origin(
city string comment '城市',
salary array<string> comment '薪资',
company array<string> comment '福利',
kill array<string> comment '技能')
comment '原始职位数据表'
row format delimited fields terminated by ','
collection items terminated by '-'
stored as textfile;
--加载数据
load data inpath '/output' overwrite into table ods_jobdata_origin;
--查询数据
select * from ods_jobdata_origin;

创建明细表ods_jobdata_detail用于存储事实表细化薪资字段的数据
create table ods_jobdata_detail(
city string comment '城市',
salary array<string> comment '薪资',
company array<string> comment '福利',
kill array<string> comment '技能',
low_salary int comment '低薪资',
high_salary int comment '高薪资',
avg_salary double comment '平均薪资')
comment '职位数据明细表'
row format delimited fields terminated by ','
collection items terminated by '-'
stored as textfile;
insert overwrite table ods_jobdata_detail
select city,salary,company,kill,salary[0],salary[1],(salary[0]+salary[1])/2
from ods_jobdata_origin;
对薪资字段内容进行扁平化处理,将处理结果存储到临时中间表t_ods_tmp_salary
create table t_ods_tmp_salary as select explode(ojo.salary) from ods_jobdata_origin ojo;
对t_ods_tmp_salary表的每一条数据进行泛化处理,将处理结果存储到中间表
t_ods_tmp_salary_dist中
create table t_ods_tmp_salary_dist as select case
when col>=0 and col<=5 then "0-5"
when col>=6 and col<=10 then "6-10"
when col>=11 and col<=15 then "11-15"
when col>=16 and col<=20 then "16-20"
when col>=21 and col<=25 then "21-25"
when col>=26 and col<=30 then "26-30"
when col>=31 and col<=35 then "31-35"
when col>=36 and col<=40 then "36-40"
when col>=41 and col<=45 then "41-45"
when col>=46 and col<=50 then "46-50"
when col>=51 and col<=55 then "51-55"
when col>=56 and col<=60 then "56-60"
when col>=61 and col<=65 then "61-65"
when col>=66 and col<=70 then "66-70"
when col>=71 and col<=75 then "71-75"
when col>=76 and col<=80 then "76-80"
when col>=81 and col<=85 then "81-85"
when col>=86 and col<=90 then "86-90"
when col>=91 and col<=95 then "91-95"
when col>=96 and col<=100 then "96-100"
when col>=101 then ">101" end from t_ods_tmp_salary;
对福利标签字段内容进行扁平化处理,将处理结果存储到临时中间表t_ods_tmp_company
create table t_ods_tmp_company as select explode(ojo.company) from ods_jobdata_origin ojo;
对技能标签字段内容进行扁平化处理,将处理结果存储到临时中间表t_ods_tmp_kill
create table t_ods_tmp_kill as select explode(ojo.kill) from ods_jobdata_origin ojo;
创建维度表t_ods_kill,用于存储技能标签的统计结果
create table t_ods_kill(
every_kill string comment '技能标签',
count int comment '词频')
comment '技能标签词频统计'
row format delimited fields terminated by ','
stored as textfile;
创建维度表t_ods_company,用于存储福利标签的统计结果
create table t_ods_company(
every_company string comment '福利标签',
count int comment '词频')
comment '福利标签词频统计'
row format delimited fields terminated by ','
stored as textfile;
创建维度表t_ods_salary,用于存储薪资分布的统计结果
create table t_ods_salary(
every_partition string comment '薪资分布',
count int comment '聚合统计')
comment '薪资分布聚合统计'
row format delimited fields terminated by ','
stored as textfile;
创建维度表t_ods_city,用于存储城市的统计结果
create table t_ods_city(
every_city string comment '城市',
count int comment '词频')
comment '城市统计'
row format delimited fields terminated by ','
stored as textfile;

5.3分析数据
职位区域分析
--职位区域分析
insert overwrite table t_ods_city
select city,count(1) from ods_jobdata_origin group by city;
--倒叙查询职位区域的信息
select * from t_ods_city sort by count desc;
--职位薪资分析
insert overwrite table t_ods_salary
select '_c0',count(1) from t_ods_tmp_salary_dist group by '_c0';
--查看维度表t_ods_salary中的分析结果,使用sort by 参数对表中的count列进行倒序排序
select * from t_ods_salary sort by count desc;
--平均值
select avg(avg_salary) from ods_jobdata_detail;
--众数
select avg_salary,count(1) as cnt from ods_jobdata_detail group by avg_salary order by cnt desc limit 1;
--中位数
select percentile(cast(avg_salary as bigint),0.5) from ods_jobdata_detail;
--公司福利分析
insert overwrite table t_ods_company
select col,count(1) from t_ods_tmp_company group by col;
--查询维度表中的分析结果,倒序查询前10个
select every_company,count from t_ods_company sort by count desc limit 10;
--职位技能要求分析
insert overwrite table t_ods_kill
select col,count(1) from t_ods_tmp_kill group by col;
--查看技能维度表中的分析结果,倒叙查看前3个
select every_kill,count from t_ods_kill sort by count desc limit 3;
第六章:数据可视化
6.1平台概述
招聘网站职位分析-数据可视化系统主要通过Web平台对分析结果进行图像化展示,旨在借助于图形化手段,清晰有效地传达信息,能够真实反映现阶段有关大数据职位的内容。本系统采用pyecharts来辅助实现。
招聘网站职位分析可视化系统以JavaWeb为基础搭建,通过Django框架实现后端功能。
6.2数据迁移
--创建数据库JobData
CREATE DATABASE JobData CHARACTER set utf8 COLLATE utf8_general_ci;
--创建城市分布表
create table t_city_count(
city VARCHAR(30) DEFAULT null,
count int(5) DEFAULT NULL
) ENGINE=INNODB DEFAULT CHARSET=utf8;
--创建薪资分布表
create table t_salary_count(
salary VARCHAR(30) DEFAULT null,
count int(5) DEFAULT NULL
) ENGINE=INNODB DEFAULT CHARSET=utf8;
--创建福利标签统计表
create table t_company_count(
company VARCHAR(30) DEFAULT null,
count int(5) DEFAULT NULL
) ENGINE=INNODB DEFAULT CHARSET=utf8;
--创建技能标签统计表
create table t_kill_count(
kills VARCHAR(30) DEFAULT null,
count int(5) DEFAULT NULL
) ENGINE=INNODB DEFAULT CHARSET=utf8;
通过Sqoop实现数据迁移
Sqoop主要用于在Hadoop(Hive)与传统数据库(MySQL)间进行数据传递,可以将一个关系型数据库中的数据导入到Hadoop的HDFS中,也可以将HDFS的数据导入到关系型数据库中。
--将职位所在的城市的分布统计结果数据迁移到t_city_count表中
bin/sqoop export \
--connect jdbc:mysql://hadoop1:3306/JobData?characterEncoding=UTF-8 \
--username root \
--password 123456 \
--table t_city_count \
--columns "city,count" \
--fields-terminated-by ',' \
--export-dir /user/hive/warehouse/jobdata.db/t_ods_city
--将职位薪资分布结果数据迁移到t_salary_count表中
bin/sqoop export \
--connect jdbc:mysql://hadoop1:3306/JobData?characterEncoding=UTF-8 \
--username root \
--password 123456 \
--table t_salary_dist \
--columns "salary,count" \
--fields-terminated-by ',' \
--export-dir /user/hive/warehouse/jobdata.db/t_ods_salary
--将职位福利统计结果数据迁移到t_company_count表中
bin/sqoop export \
--connect jdbc:mysql://hadoop1:3306/JobData?characterEncoding=UTF-8 \
--username root \
--password 123456 \
--table t_company_count \
--columns "company,count" \
--fields-terminated-by ',' \
--export-dir /user/hive/warehouse/jobdata.db/t_ods_company
--将职位技能标签统计结果迁移到t_kill_count表中
bin/sqoop export \
--connect jdbc:mysql://hadoop1:3306/JobData?characterEncoding=UTF-8 \
--username root \
--password 123456 \
--table t_kill_dist \
--columns "kills,count" \
--fields-terminated-by ',' \
--export-dir /user/hive/warehouse/jobdata.db/t_ods_kill
数据可视化
city数据处理
import pymysql
# 数据库连接信息
from pyecharts.charts import Bar
from pyecharts import options as opts
cnx = pymysql.connect(user='root', password='123456', host='127.0.0.1', database='JobData')
cursor = cnx.cursor()
# 执行查询
query = ("SELECT * FROM t_city_count")
cursor.execute(query)
# 获取所有结果
results = cursor.fetchall()
print(results)
# 关闭游标和连接
cursor.close()
cnx.close()
# 你可以将results转换为列表或字典,以便后续处理
# 这里只是一个简单的例子,你可能需要根据你的表结构进行转换
x = [row[0] for row in results] # 假设我们只关心第一列的数据
y = [row[1] for row in results]
print(x)
print(y)
# word = list(results)
# print(word)
bar = (
Bar()
.add_xaxis(x)
.add_yaxis("Series", y)
.set_global_opts(
title_opts=opts.TitleOpts(title="横向柱状图示例"),
xaxis_opts=opts.AxisOpts(
axislabel_opts=opts.LabelOpts(rotate=90), # 旋转标签以节省空间
interval=0 # 显示所有标签,如果标签过多可能会导致重叠
),
# 你还可以在这里设置图表的大小,例如:width="1200px", height="600px"
)
)
bar.render('city_bar.html')
kill数据处理
import pymysql
# 数据库连接信息
from pyecharts.charts import Bar
from pyecharts import options as opts
cnx = pymysql.connect(user='root', password='123456', host='127.0.0.1', database='JobData')
cursor = cnx.cursor()
# 执行查询
query = ("SELECT * FROM t_city_count")
cursor.execute(query)
# 获取所有结果
results = cursor.fetchall()
print(results)
# 关闭游标和连接
cursor.close()
cnx.close()
# 你可以将results转换为列表或字典,以便后续处理
# 这里只是一个简单的例子,你可能需要根据你的表结构进行转换
x = [row[0] for row in results] # 假设我们只关心第一列的数据
y = [row[1] for row in results]
print(x)
print(y)
# word = list(results)
# print(word)
bar = (
Bar()
.add_xaxis(x)
.add_yaxis("Series", y)
.set_global_opts(
title_opts=opts.TitleOpts(title="横向柱状图示例"),
xaxis_opts=opts.AxisOpts(
axislabel_opts=opts.LabelOpts(rotate=90), # 旋转标签以节省空间
interval=0 # 显示所有标签,如果标签过多可能会导致重叠
),
# 你还可以在这里设置图表的大小,例如:width="1200px", height="600px"
)
)
bar.render('city_bar.html')
[root@centos72 pythonProject]# ^C
[root@centos72 pythonProject]# ls
1.py 3.py city_bar.py kill_ciyun.py sqlite-autoconf-3350500.tar.gz
2.py baocuo company_wordcount.py salary_bar.py
[root@centos72 pythonProject]# cat kill_ciyun.py
import pymysql
# 数据库连接信息
from pyecharts.charts import WordCloud
from pyecharts import options as opts
cnx = pymysql.connect(user='root',password='123456',host='127.0.0.1',database='JobData')
cursor = cnx.cursor()
# 执行查询
query = ("SELECT * FROM t_kill_count")
cursor.execute(query)
# 获取所有结果
results = cursor.fetchall()
print(results)
# 关闭游标和连接
cursor.close()
cnx.close()
# 你可以将results转换为列表或字典,以便后续处理
# 这里只是一个简单的例子,你可能需要根据你的表结构进行转换
x = [row[0] for row in results] # 假设我们只关心第一列的数据
y = [row[1] for row in results]
word = list(results)
print(word)
wordcloud = (
WordCloud()
.add("",word,word_size_range=[20,100])
.set_global_opts(title_opts=opts.TitleOpts(title="kill_count"))
)
wordcloud.render('kill_wordcount.html')
company数据处理
import pymysql
# 数据库连接信息
from pyecharts.charts import WordCloud
from pyecharts import options as opts
cnx = pymysql.connect(user='root', password='123456', host='127.0.0.1', database='JobData')
cursor = cnx.cursor()
# 执行查询
query = ("SELECT * FROM t_company_count")
cursor.execute(query)
# 获取所有结果
results = cursor.fetchall()
print(results)
# 关闭游标和连接
cursor.close()
cnx.close()
# 你可以将results转换为列表或字典,以便后续处理
# 这里只是一个简单的例子,你可能需要根据你的表结构进行转换
x = [row[0] for row in results] # 假设我们只关心第一列的数据
y = [row[1] for row in results]
word = list(results)
print(word)
wordcloud = (
WordCloud()
.add("", word, word_size_range=[20, 100])
.set_global_opts(title_opts=opts.TitleOpts(title="company_count"))
)
wordcloud.render('company_wordcount.html')
salary数据处理
import pymysql
# 数据库连接信息
from pyecharts.charts import Bar
from pyecharts import options as opts
cnx = pymysql.connect(user='root', password='123456', host='127.0.0.1', database='JobData')
cursor = cnx.cursor()
# 执行查询
query = ("SELECT * FROM t_salary_count")
cursor.execute(query)
# 获取所有结果
results = cursor.fetchall()
print(results)
# 关闭游标和连接
cursor.close()
cnx.close()
# 你可以将results转换为列表或字典,以便后续处理
# 这里只是一个简单的例子,你可能需要根据你的表结构进行转换
x = [row[0] for row in results] # 假设我们只关心第一列的数据
y = [row[1] for row in results]
print(x)
print(y)
# word = list(results)
# print(word)
bar = (
Bar()
.add_xaxis(x)
.add_yaxis("Series", y)
.set_global_opts(
title_opts=opts.TitleOpts(title="横向柱状图示例"),
xaxis_opts=opts.AxisOpts(
axislabel_opts=opts.LabelOpts(rotate=90), # 旋转标签以节省空间
interval=0 # 显示所有标签,如果标签过多可能会导致重叠
),
# 你还可以在这里设置图表的大小,例如:width="1200px", height="600px"
)
)
bar.render('salary_bar.html')
创建Django项目
目录信息

主要内容


运行Django

结果演示
福利词云演示

技能词云演示

薪资分布演示

城市工作量演示


开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 18
18 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)