scrapy+python股票基金数据可视化分析系统附源码
题目是基金分析可视化系统的设计与实现,通过网络爬虫抓取网站中的基金信息,对基金信息中的数据进行保存,然后对数据进行处理,然后可视化抓取到的基金信息.以达到为理财者进行合适的基金推荐, 系统主要开发工具是PyCharm,主要技术为html、css以及django开源框架的结合,前端使用 vue+elementui后端使用python+django.主要实现了用户注册,登录, 以及基金数。3.使用Dj
本系统实现了一个 基金分析可视化系统,主要功能如下:
1.搭建scrapy框架运行环境、搭建python运行环境、搭建Django框架运行环境,为系统开发做环境支持;
2.编写爬虫代码,依据不同网页的特性,实现对目标基金网站信息网站的爬取,从获取的网页内容中抽取出有价值的信息,对其进行数据清洗、数据封装,并将其存入数据库中;
3.使用Django web框架,完成其与数据库的连接,实现将爬取到的基金信息在web端展示的功能;
4.采用有效的反爬取手段,避开基金网站对爬虫的封禁。
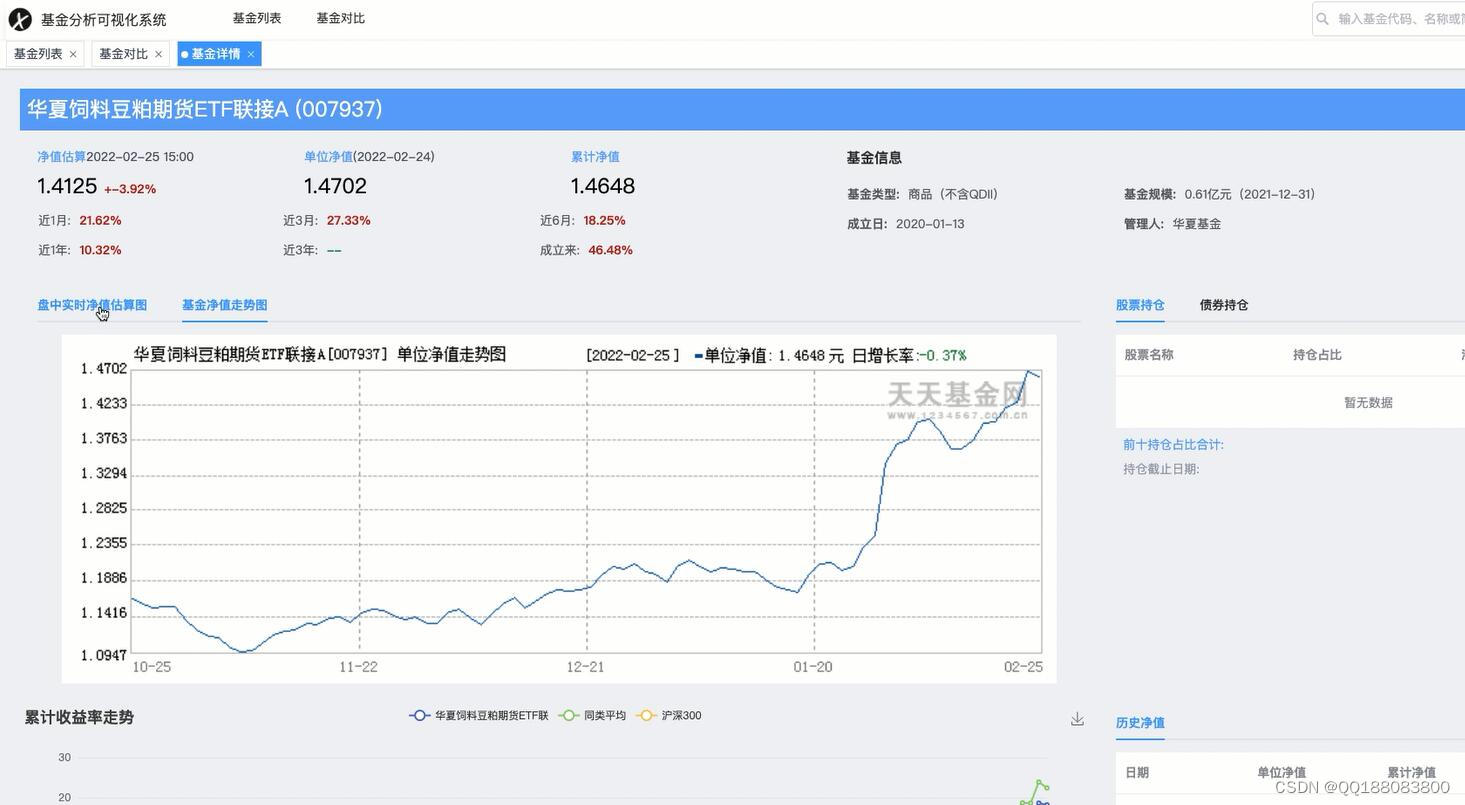
5.将爬取到的基金信息中的基金代码,基金简称,基金类型,盘中估值,估值涨幅,最新单位净值,日增长率等并最终实现数据的可视化展示。






3.3 爬虫设计
系统整体可分为三个部分,爬虫模块、数据库部分、数据展示模块。每个部分又可继续细分。
随着指数基金数量和规模的增加和扩大,对指数基金进行专业的分析评价也变得越来越迫切。基金研究人员普遍反映基金研究报告客观内容的撰写占用了他们大量宝贵时间。所以本次毕业设计的
题目是基金分析可视化系统的设计与实现,通过网络爬虫抓取网站中的基金信息,对基金信息中的数据进行保存,然后对数据进行处理,然后可视化抓取到的基金信息.以达到为理财者进行合适的基金推荐, 系统主要开发工具是PyCharm,主要技术为html、css以及django开源框架的结合,前端使用 vue+elementui后端使用python+django.主要实现了用户注册,登录, 以及基金数
3.2 系统功能分析
from django.shortcuts import render
from . import *
from django.http import HttpRequest
from index.utils import success, error
from django.http import StreamingHttpResponse
from django.http.response import HttpResponse
def search_fund(request: HttpRequest):
data = search(request.json.get("keyword"))
return success(data)
def filter_fund(request: HttpRequest):
data = filter_(**dict(request.json.items()))
return success(data)
def fund_detail(request: HttpRequest):
data = detail(request.json.get("code"))
return success(data)
def fund_jzgs_pic(request: HttpRequest):
data = get_picture(request.json.get("code"))
return HttpResponse(data, content_type="image/png")
def fund_jz_pic(request: HttpRequest):
data = get_jz_picture(request.json.get("code"))
return HttpResponse(data, content_type="image/png")
def js_data(request: HttpRequest):
data = get_js_data(request.json.get("code"))
return HttpResponse(data, content_type="application/javascript")
def ljsylzs(request: HttpRequest):
data = get_ljsylzs(**dict(request.json.items()))
return success(data)
def jbxx(request: HttpRequest):
data = get_jbxx(**dict(request.json.items()))
return success(data)
def yjpjbj(request: HttpRequest):
data = get_yjpjbj(**dict(request.json.items()))
return success(data)
def ljsyl(request: HttpRequest):
data = get_ljsyl(**dict(request.json.items()))
return success(data)
目 录
摘要 1
abstract 1
目 录 1
1 绪论 3
1.1 开发背景 3
1.2 开发意义 3
2 开发技术介绍 3
2.1 Python介绍 3
2.2 Django介绍 3
2.3 xpath介绍 4
2.4 Vue介绍 5
2.5 Scrapy架构 5
2.6 开发环境搭建 6
3 系统设计 7
3.1 可行性分析 7
3.2 系统功能分析 8
3.3 爬虫设计 8
3.4 功能模块设计 10
3.5 突破反爬虫设计 10
3.6 系统文件结构介绍 11
3.7 scrapy爬虫主要文件介绍 12
4 详细实现 12
4.1 系统注册登陆 12
4.2 个人中心主界面 13
4.3 基金列表 13
4.4 数据可视化 15
4.4.1 收益率走势对比图 15
4.4.2 盘中实时净值估算 15
4.4.3 基金净值走势图 16
4.4.4 累计收益走势 16
5 系统测试 16
5.1 软件测试的环境 16
5.2 测试的重要性 17
5.3 数据展示测试 17
结束语 18
参考文献 20
致谢 22

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)