京东商品评论信息爬取及词云图制作——python爬虫(步骤详细,初学可做)
本篇内容主要介绍如何利用python在京东上爬取商品的评论信息及词云图的制作,案例选取了京东某店铺的新品小米十四手机两百多条评价,并采取了手动输入商品编号的方式可以实现"一码多用"进行不同商品信息爬取。
目录
一、介绍
1.摘要:
本篇内容主要介绍如何利用python在京东上爬取商品的评论信息及词云图的制作,案例选取了京东某店铺的新品小米十四手机两百多条评价,并采取了手动输入商品编号的方式可以实现"一码多用"进行不同商品信息爬取。
2.所需工具:
爬虫:python、pandas、requests、xpath、json、time
词云图:python、jieba、wordcloud
二、效果展示
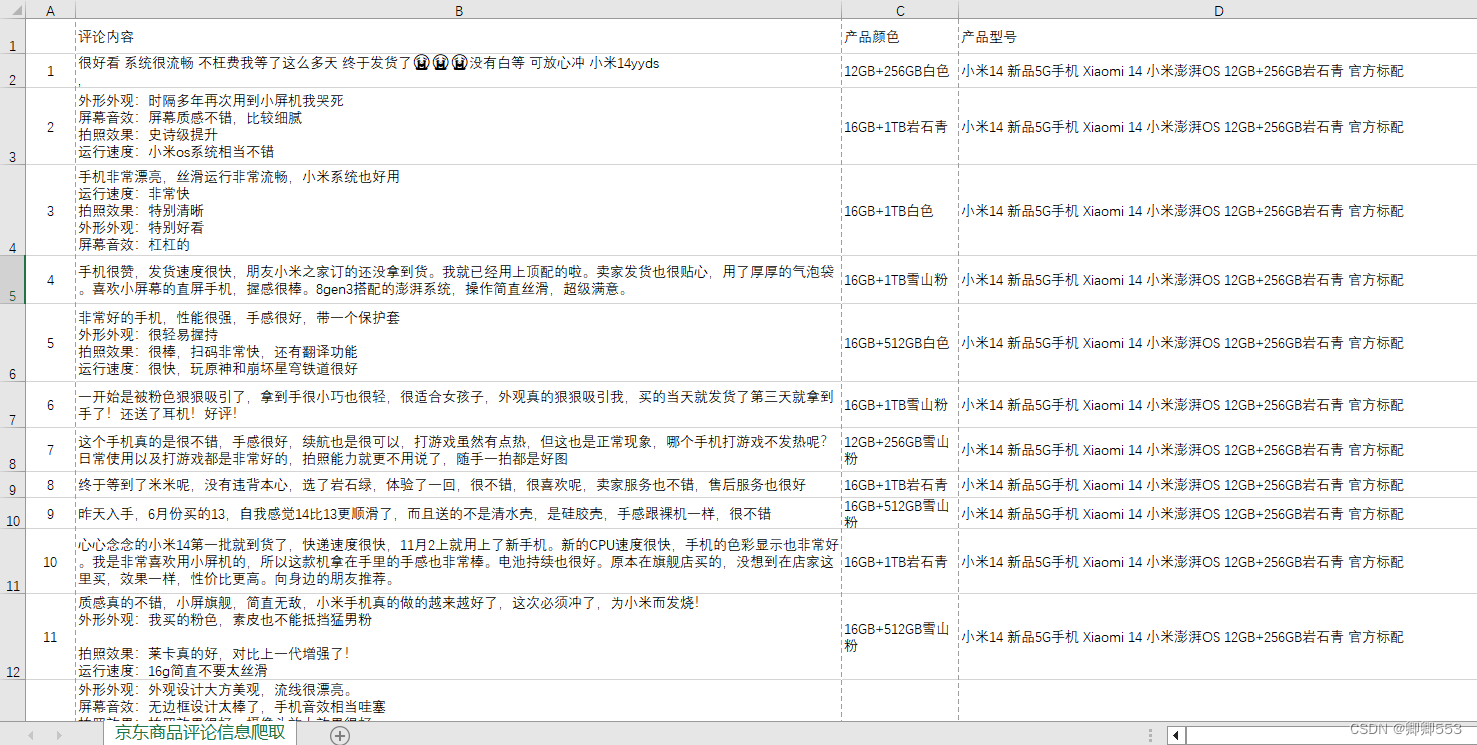
1.评论信息表格

2.词云图
三、爬取过程
1.导入所需模块
import requests import json import pandas as pd import time
2.UA伪装
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'}
建议直接复制粘贴
获取方法:在商品网页右键单击,依次选择——检查——Network——F5刷新选择第一项——划到最下方即可获取User-Agent
3.评论信息所在网址获取
(1)注意:
此时我们所需要的链接并不是像往常一样点击”商品评价“即可获取,用此链接是无法爬取到评论信息的
(2)真实链接查找方法
右键单击——检查——network——F5刷新后找到如图所示左侧选项,右侧的request url即我们所需的网址
url=‘https://api.m.jd.com/?appid=item-v3&functionId=pc_club_productPageComments&client=pc&clientVersion=1.0.0& t=1700188551707&loginType=3&uuid=122270672.1700188238960301464362.1700188239.1700188239.1700188239.1& productId=10089055921527&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1&bbtf=&shield='

然后选择右侧Preview即可看见我们所需的评论信息,是一个json文件

4.利用input语句输入商品编号实现评论信息爬取
本网页商品编号如图:
对比上方网址可知网址中的productId即为商品编号,可得出新网址代码如下
productid=input('请输入商品编号:')
url=f'https://api.m.jd.com/?appid=item-v3&functionId=pc_club_productPageComments&client=pc&clientVersion=1.0.0&
t=1700188551707&loginType=3&uuid=122270672.1700188238960301464362.1700188239.1700188239.1700188239.1&
productId={productid}&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1&bbtf=&shield='l
5.利用requests获取html
json_html=requests.get(url,headers=headers).text
6.json文件转换为dict
由3可知评论信息被封装在json文件中,所以我们需要借助json模块将json文件转换为python能识别的字典,代码如下:
dict_data=json.loads(json_html)
7.实现翻页功能
而网址中的page代表的是页数,page=0时是第一页,page=1是第二页,而且由图可知该网页最大页数maxPage为22,所以翻页功能可以借助for循环改变page的数值来实现,代码如下:
max_page=dict_data['maxPage']
for num in range (1,max_page+1):
new_url=f'https://api.m.jd.com/?appid=item-v3&functionId=pc_club_productPageComments&client=pc&clientVersion=1.0.0&t=1700188551707&loginType=3&uuid=122270672.1700188238960301464362.1700188239.1700188239.1700188239.1&productId={productid}&score=0&sortType=5&page={num-1}&pageSize=10&isShadowSku=0&fold=1&bbtf=&shield='
8.重复上方5,6的步骤
由于运用for循环使url发生改变,所以要在for循环内重复5,6步骤
注意:自此以下所有步骤都要包含在7的for循环内部
json_html = requests.get(new_url, headers=headers).text dict_data = json.loads(json_html)
9.获取评论内容、产品颜色、产品型号
继续利用for循环分别获取评论内容、产品颜色、产品型号的列表,内容涉及有关于字典利用key取值内容、列表的append添加内容,代码如下
comments_list=dict_data['comments']
content_list=[]
color_list=[]
type_list=[]
for x in comments_list:
comment=x['content']
content_list.append(comment)
for y in comments_list:
color=y['productColor']
color_list.append(color)
for z in comments_list:
type=z['referenceName']
type_list.append(type)
10.借助pandas将信息存储为csv文件
all_data=pd.DataFrame({'评论内容':content_list,'产品颜色':color_list,'产品型号':type_list})
all_data.to_csv('D:/ceshi京东商品评论信息爬取.csv',mode='a',encoding="utf-8-sig")
注意:有些小伙伴可能会遇到跟我一样的问题,刚开始我写的是encoding="utf-8",用Excel打开之后是看不懂的中文乱码,经过实验发现用utf-8-sig可以正常显示
11.设置睡眠时长控制数据爬取翻页时间
这一步个人理解是为了让数据爬取过程更像是人在浏览一样,避免被发现
time.sleep(3)
四、评论信息爬取完整代码展示
import requests
import json
import pandas as pd
import time
#应用input语句实现手动输入商品编号和页码来获取评论
productid=input('请输入商品编号:')
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)\
Chrome/119.0.0.0 Safari/537.36'}
url=f'https://api.m.jd.com/?appid=item-v3&functionId=pc_club_productPageComments&client=pc&clientVersion=1.0.0&\
t=1700188551707&loginType=3&uuid=122270672.1700188238960301464362.1700188239.1700188239.1700188239.1&\
productId={productid}&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1&bbtf=&shield='
json_html=requests.get(url,headers=headers).text
#将json字符串转换为字典格式
dict_data=json.loads(json_html)
max_page=dict_data['maxPage']
for num in range (1,max_page+1):
new_url=f'https://api.m.jd.com/?appid=item-v3&functionId=pc_club_productPageComments&client=pc&clientVersion=1.0.0&\
t=1700188551707&loginType=3&uuid=122270672.1700188238960301464362.1700188239.1700188239.1700188239.1&\
productId={productid}&score=0&sortType=5&page={num-1}&pageSize=10&isShadowSku=0&fold=1&bbtf=&shield='
json_html = requests.get(new_url, headers=headers).text
dict_data = json.loads(json_html)
comments_list=dict_data['comments']
content_list=[]
color_list=[]
type_list=[]
for x in comments_list:
comment=x['content']
content_list.append(comment)
for y in comments_list:
color=y['productColor']
color_list.append(color)
for z in comments_list:
type=z['referenceName']
type_list.append(type)
all_data=pd.DataFrame({'评论内容':content_list,'产品颜色':color_list,'产品型号':type_list})
all_data.to_csv('D:/ceshi京东商品评论信息爬取.csv',mode='a',encoding="utf-8-sig")
time.sleep(3)五、词云图制作流程
1.导入所需模块
import jieba import wordcloud
2.导入评论信息所在文件
f=open('D:/小米十四评论.txt',encoding='utf-8')
data=f.read()
3.利用jieba对字段进行切分
data_list=jieba.lcut(data)
4.将列表数据转换为字符串
由于wordcloud不支持列表,所以要将数据转换为字符串
str1=" ".join(data_list)
5.利用wordcloud进行词云图制作
(1)参数配置
wc=wordcloud.WordCloud(
height=300,
width=500,
background_color='white',
font_path='STZHONGS.TTF',
scale=15,
stopwords={"的",'了','手机','非常','很','!','也',"小米",'我','是','用'}
)
height和width分别表示词云图的高度和宽度即宽和长
background_color表示背景图颜色
font_path表示索要设置的字体路径
scale表示字体大小
stopwords表示不需要参与词云图制作的词
tip:font_path查找方法
C盘——windows——Fonts——选中字体后右键点击属性——常规——第一行内容即为font_path
(2)jieba字段导入和词云图导出
wc.generate(str1)
wc.to_file('D:/小米十四词云图8.png')
六、词云图制作完整代码展示
import jieba
import wordcloud
f=open('D:/小米十四评论.txt',encoding='utf-8')
data=f.read()
data_list=jieba.lcut(data)
str1=" ".join(data_list)
wc=wordcloud.WordCloud(
height=300,
width=500,
background_color='white',
font_path='STZHONGS.TTF',
scale=15,
stopwords={"的",'了','手机','非常','很','!','也',"小米",'我','是','用'}
)
wc.generate(str1)
wc.to_file('D:/小米十四词云图8.png')
开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 25
25 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)