python作业-基于Flickr30k数据集实现图像文本跨模态搜索python源码+数据集+测试界面+项目说明(高分课程设计)
跨模态检索:图像——文本检索媒体计算实践作业:图像——文本跨模态搜索数据集下载本项目使用的是Flickr30k数据集,你需要自行先下载。百度云地址数据预处理在Preprocessing下:data_split_1.py 划分训练集、测试集、验证集resize_data_2.py 长宽比例不变,将短边拉伸为256count_vocab_3.py 统计每个单词的词频convert_annotation
源码下载地址
项目介绍
跨模态检索:图像——文本检索
媒体计算实践作业:图像——文本跨模态搜索
数据集下载
本项目使用的是Flickr30k数据集,你需要自行先下载。 百度云地址
数据预处理
在Preprocessing下:
data_split_1.py 划分训练集、测试集、验证集
resize_data_2.py 长宽比例不变,将短边拉伸为256
count_vocab_3.py 统计每个单词的词频
convert_annotations_4.py 将.txt格式的标注文件转换为.json
build_dictionary_5.py 构建单词编号,即查询字典
模型训练
在数据预处理完成后,在config.py中配置各文件的路径以及训练的参数,并且下载在谷歌新闻上预训练的Word2Vec模型
trainStage1.py 使用分类损失预训练
trainStage2.py 使用三元组损失和对抗损失微调
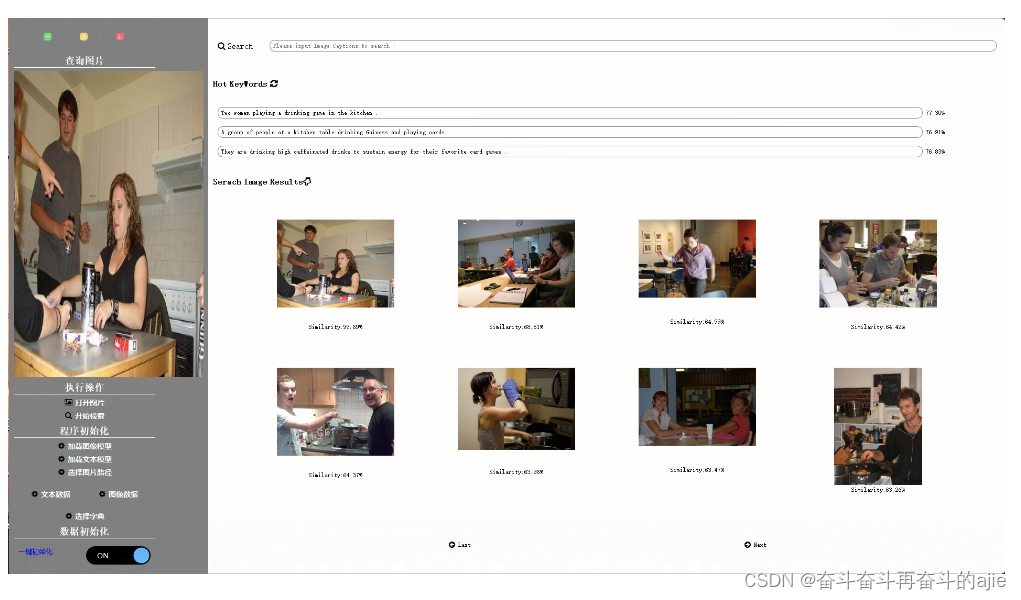
项目功能
界面预览

项目备注
1、该资源内项目代码都经过测试运行成功,功能ok的情况下才上传的,请放心下载使用!
2、本项目适合计算机相关专业(如计科、人工智能、通信工程、自动化、电子信息等)的在校学生、老师或者企业员工下载学习,也适合小白学习进阶,当然也可作为毕设项目、课程设计、作业、项目初期立项演示等。
3、如果基础还行,也可在此代码基础上进行修改,以实现其他功能,也可用于毕设、课设、作业等。
下载后请首先打开README.md文件(如有),仅供学习参考, 切勿用于商业用途。
源码下载地址

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)