python爬虫教你如何快速搜索信息
很多时候,我们想要百度一个内容,却往往难以获得有用的信息,这时便需要进行必要的筛选,若是每次都点进连接中去查看,未免太过费时间,这里将利用python爬虫,快速帮你下载百度搜索的各条数据。1.下面的代码使用时有如下条件:安装了火狐浏览器安装了火狐驱动,可前往https://github.com/mozilla/geckodriver/releases下载安装所需要的相关包,运行时会提示的...
·
很多时候,我们想要百度一个内容,却往往难以获得有用的信息,这时便需要进行必要的筛选,若是每次都点进连接中去查看,未免太过费时间,这里将利用python爬虫,快速帮你下载百度搜索的各条数据。
1.下面的代码使用时有如下条件:
- 安装了火狐浏览器
- 安装了火狐驱动,可前往https://github.com/mozilla/geckodriver/releases下载
- 安装所需要的相关包,运行时会提示的,推荐使用pip安装
2.这里更重要的还是学习相关技术
- selenium的使用(一款自动化测试工具,这里用在爬虫技术中,用于模拟用户行为,可以解决绝大部分的反爬行为)
- xpath解析的学习
3.开始写代码
3.1导包
# -*- coding: utf-8 -*-
from selenium import webdriver
from lxml import etree
import os
import time
3.2全局配置
save_path = 'D:\\桌面' # 文件路径
filename = "结果集"
3.3主类main函数(selenium相关操作)
if __name__ == "__main__":
key_world = input("请输入您想要搜索的内容:")
num = int(input("请输入您想要爬取的页数:"))
filename = input("请输入您想要存储的文件名:")
urls = [] # 页码索引列表
for i in range(num):
url = "https://www.baidu.com/s?wd=" + key_world + "&pn=" + str(
i * 10) + "&oq=" + key_world + "&ie=utf-8&rsv_pq=da6a000c0001b80d&rsv_t=d7f5m3K7D2ij87xFqs1%2FBxTHWIIxqW6xVfayx6TdZRvpTSctGF1ObM1gLKs"
urls.append(url)
driver = webdriver.Firefox()
for u in urls:
driver.get(u)
myPage = driver.page_source # 获取源码
spider(myPage)
time.sleep(2)
driver.quit()
第一个for循环是根据百度的搜索规律,将搜索内容接入后拼接而成的网址,根据你所需要的页数,把他们放到一个列表中去。随后开启selenium,自动打开火狐浏览器,根据上面的网址列表,分别去遍历,也就是得到每一个网址所对应的以及页面,将该页面的源代码通过page_source方法下载下来,交由spider去解析和存储
3.4爬虫spider
def spider(myPage):
results = Page_Level(myPage) # 解析html文档获得结果
FileSave(results)# 将结果存储到txt文档中
3.5一级页面,数据解析(xpath的使用)
def Page_Level(myPage): # 一级页面
dom = etree.HTML(myPage)
results = []
channel_names = dom.xpath('//*[@id="content_left"]/div')
for channel in channel_names:
try:
summary = channel.xpath('div[@class="c-abstract"]/text()')
title_link = channel.xpath('div[@class="f13"]/div[1]/@data-tools')
print(title_link[0])
results.append("【" + title_link[0] + "\n" + str(summary) + "】\n\n")
except:
pass
return results
利用xpath方法提取出文档中的标题,地址,将要概述
3.6数据存储(保存为txt文档)
def FileSave(results):
if not os.path.exists(save_path): # 判断文件路径是否存在,若不在,则创建
os.mkdir(save_path)
path = save_path + os.path.sep + filename + ".txt"
with open(path, 'a+', encoding='utf-8') as fp:
for i in results:
fp.write("%s\n" % (i))
最后,附上完整的代码
# -*- coding: utf-8 -*-
from selenium import webdriver
from lxml import etree
import os
import time
# 全局配置
save_path = 'D:\\桌面' # 文件路径
filename = "结果集"
# 保存为TXT文档
def FileSave(results):
if not os.path.exists(save_path): # 判断文件路径是否存在,若不在,则创建
os.mkdir(save_path)
path = save_path + os.path.sep + filename + ".txt"
with open(path, 'a+', encoding='utf-8') as fp:
for i in results:
fp.write("%s\n" % (i))
# 一级页面爬取
def Page_Level(myPage): # 一级页面
dom = etree.HTML(myPage)
results = []
channel_names = dom.xpath('//*[@id="content_left"]/div')
for channel in channel_names:
try:
summary = channel.xpath('div[@class="c-abstract"]/text()')
title_link = channel.xpath('div[@class="f13"]/div[1]/@data-tools')
print(title_link[0])
results.append("【" + title_link[0] + "\n" + str(summary) + "】\n\n")
except:
pass
return results
# 爬虫
def spider(myPage):
results = Page_Level(myPage) # 解析
FileSave(results)#存储
# 运行
if __name__ == "__main__":
key_world = input("请输入您想要搜索的内容:")
num = int(input("请输入您想要爬取的页数:"))
filename = input("请输入您想要存储的文件名:")
urls = [] # 页码索引列表
for i in range(num):
url = "https://www.baidu.com/s?wd=" + key_world + "&pn=" + str(
i * 10) + "&oq=" + key_world + "&ie=utf-8&rsv_pq=da6a000c0001b80d&rsv_t=d7f5m3K7D2ij87xFqs1%2FBxTHWIIxqW6xVfayx6TdZRvpTSctGF1ObM1gLKs"
urls.append(url)
driver = webdriver.Firefox()
for u in urls:
driver.get(u)
myPage = driver.page_source # 获取源码
spider(myPage)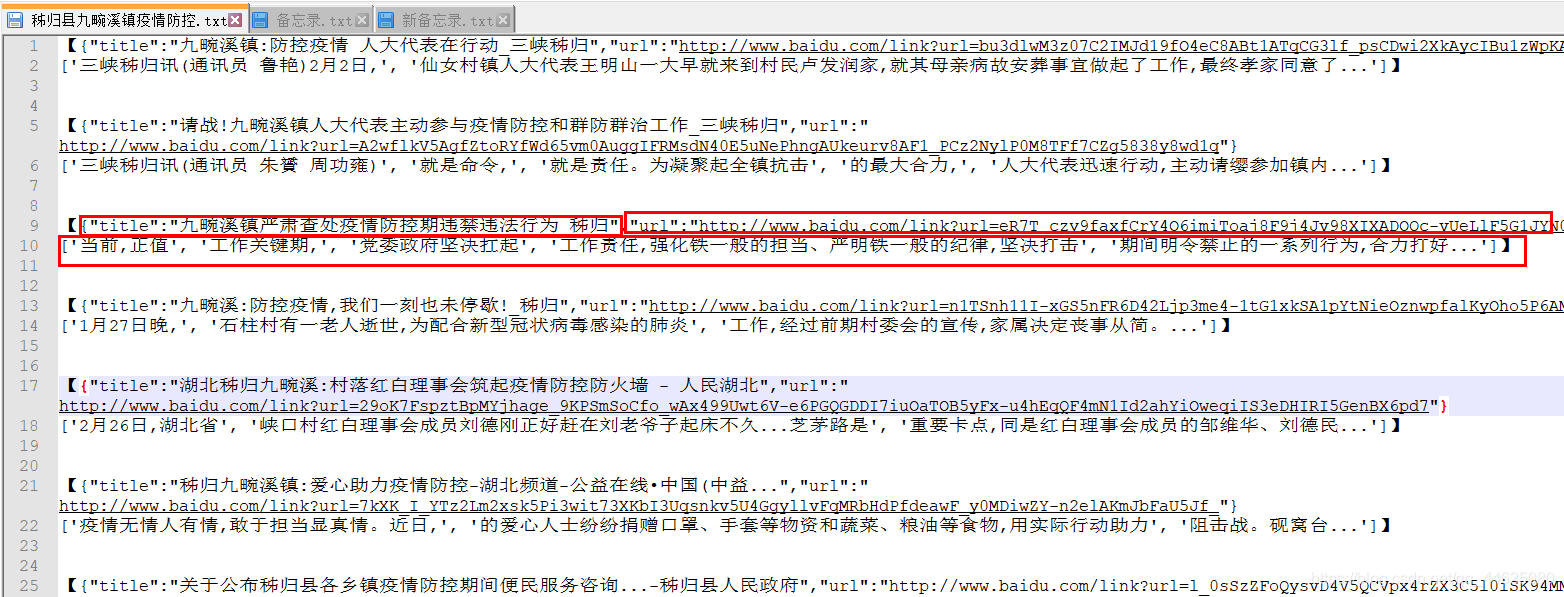
time.sleep(2)
driver.quit()
最终的效果如图

更多爬虫实例,可前往本人码云仓库
https://gitee.com/lk0423/spider

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)