相对位置编码 relative position encoding
相对位置编码
文章是对视频的总结原作者
Transformer中有两种常用的位置编码,分别为绝对位置编码和相对位置编码,其中绝对位置编码使用的比较多,也是比较简单的。在代码中直接初始化0矩阵,在forward函数中直接与x相加:

self.position_embeddings = nn.Parameter(torch.zeros(1, n_patches, in_channels))
def forward(self,x)
embeddings = x + self.position_embeddings而相对位置编码,是根据token与token之间的位置关系来生成权重:
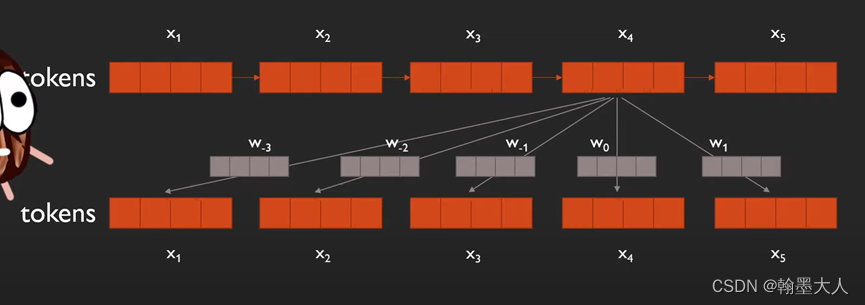
假如有5个token,其中一个token与其他所有位置包括自己在内的token之间存在一个权重。

w0表示x4与自己的位置关系,0表示与自己的距离,w1表示向右移动一个位置,w-1表示向左移动一个位置。

x3也是同理。

这样第一个到最后一个就可以表示为:


一共有9个不同的位置编码,分别为w-4, w-3, w-2, w-1, w0, w1, w2, w3, w4。用图片表示为:

我们用标识对表示为:

作者使用了一个k阈值,当超过这个特定的阈值,即其他的position_embedding距离自身超过两个位置,其他的position_embedding就和距离最近的position_embedding值一样。

假设k=2,w3和w4就会变成w2,后面同理。

那么如何用公式表示呢:

作者在text上进行了实验,但是词链就是一个展平了的graph,所以这种方法可以运用到图中,只要你元素中有成对的关系就可以使用。
在小数据集上,相比卷积transformer缺少内在偏置,因此需要加入相对位置编码来解决这个问题,而对于特大数据集,transformer就可以学习到卷积的内在偏置,即这也是为什么在小数据集上transformer的效果不如卷积,而在大数据集上,transformer效果优于卷积。
--------------------------------------------------分割线----------------------------------------------------------------------
继续补充对相对位置编码的理解,图片和思路来自B站霹雳吧啦Wz:
结合上面的知识,和上面的text一维不同,图片是二维的,同时拥有长和宽,对图片的每一个位置进行编码,第一个图片四个位置的索引,等于(0,0)-(0,0),(0,0)-(0,1),(0,0)-(1,0),(0,0)-(1,1),其他的三个图片同理。

将上面的相对位置索引进行展平,变成了如图4x4的矩阵。
在相对位置偏移公式中,B是相对位置偏移,不是相对位置索引,我们根据每一个相对位置索引(4x4矩阵)去relative position bias table去取相应的参数。
但是我们看到在蓝色方块的右边和红色方块的右边两个索引一样,所以不能简单的行列相加,并且在原文章中,我们使用的一元位置坐标,接下来我们进行转换:
首先:将数值限制到大于0。

接着行标,第一个数乘以2M-1。

最后得到一个新的索引:
根据索引我们去relative position bias table中查找对应的值。

其中训练网络中针对训练的是relative position bias table,即relative position bias table是训练出来的,而窗口m固定,index也是固定的。索引的范围行(-1,0,1),列(-1,0,1)共九个。
得到的bias即公式中的B。
参考:霹雳吧啦Wz

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)