7. user-Agent破解反爬机制
User-Agent检测:有些网站会检测请求头中的User-Agent字段,如果发现是Python的默认User-Agent,就会拒绝访问。User-Agent:每个浏览器或爬虫程序都有一个User-Agent标识,服务器可以通过检查User-Agent来判断访问者是人还是爬虫程序。服务器可以通过多种方式来识别是人手动访问网站还是爬虫程序访问网站,但是一些高级的爬虫程序可以模拟人类用户的行为,使得
文章目录
1. 为什么要设置反爬机制
普通用户通过浏览器访问网站。
爬虫是靠程序代码来访问网站。
爬虫程序可能会篡改资源信息。
爬虫程序会引发短时间内的访问激增。
导致服务器压力过大。
为了提高安全性,因此绝大多数网站都实施了反爬措施,对爬虫程序进行拦截。
【总结】
设置反爬机制是为了保护网站的数据和资源不被恶意爬虫或者机器人滥用和攻击。
恶意爬虫或机器人可能会对网站造成严重的影响,如消耗网站的带宽和服务器资源、盗取网站的数据、影响网站的正常运行等。
因此,为了保护网站的安全和稳定性,设置反爬机制是必要的。
同时,反爬机制也可以防止竞争对手通过爬虫获取网站的商业机密和竞争优势。
2. 服务器如何区分浏览器访问和爬虫访问
服务器可以通过多种方式来识别是人手动访问网站还是爬虫程序访问网站。
-
User-Agent:每个浏览器或爬虫程序都有一个User-Agent标识,服务器可以通过检查User-Agent来判断访问者是人还是爬虫程序。
-
IP地址:服务器可以通过检查访问者的IP地址来判断是否是爬虫程序。一些爬虫程序使用大量的IP地址进行访问,而人类用户通常只使用一个或几个IP地址。
-
访问频率:爬虫程序通常会以非常高的频率访问网站,而人类用户通常不会如此频繁地访问网站。服务器可以通过检查访问频率来判断是否是爬虫程序。
-
访问行为:爬虫程序通常会按照一定的规律进行访问,例如按照页面顺序进行访问或者按照特定的关键词进行搜索。服务器可以通过检查访问行为来判断是否是爬虫程序。
3. 反爬虫机制
所谓上有政策,下有对策。
服务器可以通过多种方式来识别是人手动访问网站还是爬虫程序访问网站,但是一些高级的爬虫程序可以模拟人类用户的行为,使得服务器难以区分。
Python的反爬虫机制主要包括以下几种:
-
User-Agent检测:有些网站会检测请求头中的User-Agent字段,如果发现是Python的默认User-Agent,就会拒绝访问。解决方法是在请求头中添加一个随机的User-Agent。
-
IP封禁:有些网站会根据IP地址来限制访问频率或者直接封禁IP。解决方法是使用代理IP或者使用分布式爬虫。
-
验证码识别:有些网站会在登录或者访问频率过高时出现验证码,需要手动输入才能继续访问。解决方法是使用第三方验证码识别服务或者手动输入验证码。
-
访问频率限制:有些网站会限制同一IP或同一用户的访问频率,如果超过一定次数就会拒绝访问。解决方法是控制访问频率或者使用分布式爬虫。
-
动态页面爬取:有些网站使用了动态页面技术,需要使用Selenium等工具模拟浏览器行为才能爬取。
4. User-Agent是什么
User-Agent是一个HTTP头部字段,用于标识发送HTTP请求的客户端应用程序或设备的信息。
它通常包含了操作系统、浏览器、设备类型、应用程序版本等信息,以便服务器能够根据这些信息来优化响应内容或提供适当的服务。
例如,网站可以根据User-Agent识别访问者使用的设备类型和浏览器版本,从而提供适合的网页布局和功能。
User[ˈjuːzə]:用户。
Agent[ˈeɪdʒənt]:代理人。
User-Agent用户代理,简称UA。
无论是浏览器发出的请求,还是爬虫发出的请求,都会包含请求头。
请求头里有一个非常重要的信息,User-Agent。
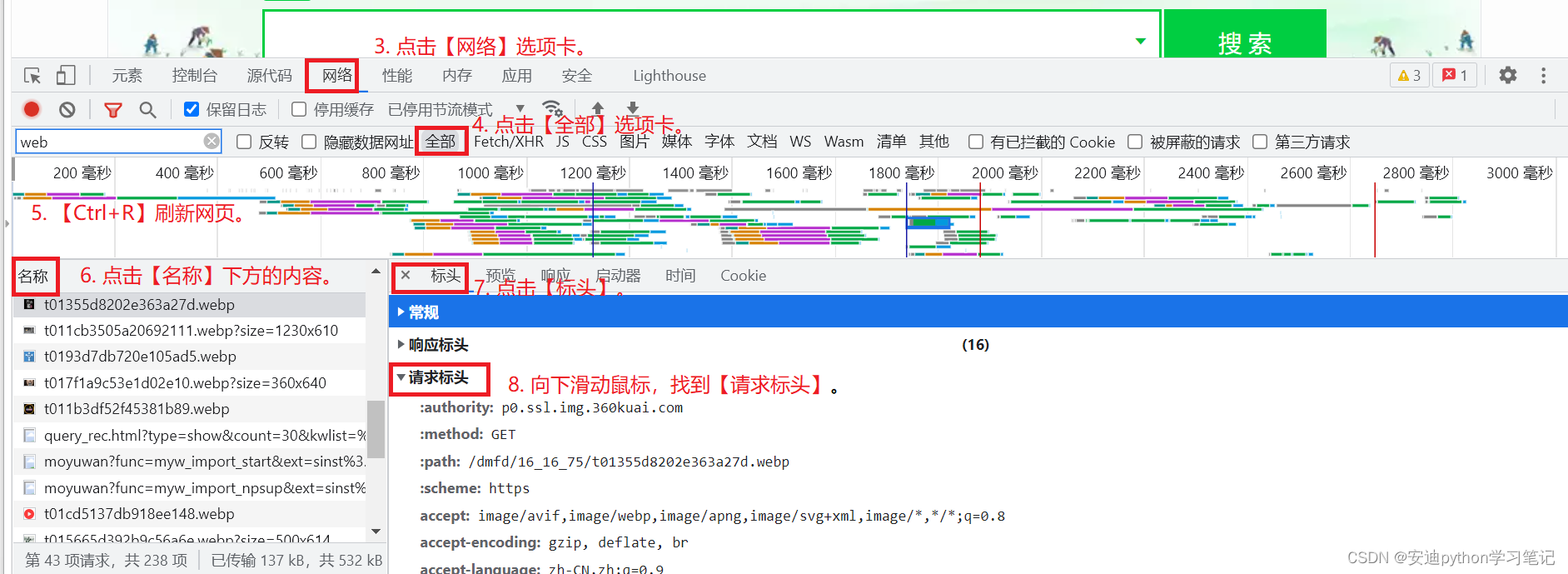
5. 如何查询网页的User-Agent
-
打开360浏览器。
-
按【F12】打开开发者工具。
-
点击【网络】选项卡。
-
点击【全部】选项卡。
-
【Ctrl+R】刷新网页。
-
点击【名称】下方的内容。
-
点击【标头】。
-
向下滑动鼠标,找到【请求标头】。

-
【请求标头】的最后一项信息就是【user-agent】
-
将整个【user-agent】复制到文件(doc或txt或py文件等等都可以)来备用。

6. user-agent信息解析
user-agent中包含许多信息,用户使用的操作系统、CPU类型、浏览器版本等等。
【复制的user-agent内容如下】
user-agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.95 Safari/537.36 QIHU 360SE
【user-agent信息解析如下】
操作系统:Windows NT 10.0
- CPU 架构:WOW64
- 浏览器内核:AppleWebKit/537.36
- 浏览器类型:Chrome
- 浏览器版本:108.0.5359.95
- 浏览器标识:Safari/537.36
- 来源:QIHU 360SE解析
在每次浏览器发送请求的时候,UA字符串都会被发送到服务器上。
服务器会根据UA信息,显示不同的网页排版,以适应不同的用户浏览器。
同时,服务器还可以通过UA信息,侦察客户端的请求是否安全。
判断请求访问的是爬虫程序还是普通用户。
7. 爬虫程序user-agent和浏览器user-agent的区别
爬虫程序里的user-agent和浏览器里的user-agent的主要不同在于:
-
目的不同:浏览器的user-agent是为了告诉服务器它所使用的浏览器类型和版本,以便服务器能够返回适合该浏览器的网页内容;而爬虫程序的user-agent是为了模拟浏览器行为,以便获取网页内容。
-
内容不同:浏览器的user-agent通常包含浏览器类型、版本、操作系统类型和版本等信息;而爬虫程序的user-agent通常只包含爬虫程序的名称和版本号等信息。
-
格式不同:浏览器的user-agent通常是一个字符串,包含多个信息,格式比较复杂;而爬虫程序的user-agent通常是一个简单的字符串,格式比较简单。
8. 代码查看爬虫程序的user-agent
我们通过一个测试网站来查看爬虫程序的user-agent的包含的信息。
【测试网站】
url = "http://httpbin.org/get"
【代码示例】
# 1.导入库
# requests是第三方库,作用是发送发送GET、POST、PUT、DELETE等请求
import requests
# 2.要访问的url
url = "http://httpbin.org/get"
# 3.发送请求,并把响应结果赋值给变量r
r = requests.get(url)
# 输出r的文本信息
print(r.text)
【终端输出】
{
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.26.0",
"X-Amzn-Trace-Id": "Root=1-6482e247-021e317204e5813568df0582"
},
"origin": "112.113.185.64",
"url": "http://httpbin.org/get"
}
上面输出的结果就爬虫程序里包含的user-agent。
观察输出结果,看到打印出来的 User-Agent的信息标志的是python-requests/2.26.0。
信息里没有操作系统,也没有浏览器版本。
所以我们通过上面的代码访问网页,服务器是能识别出是爬虫代码在访问,而不是人工在访问。
这样的User-Agent会被反爬机制轻易拦截。
既然爬虫程序是因为User-Agent被识别出来的。
那解决这个问题,我们只需要把爬虫的User-Agent伪装成浏览器请求头里的User-Agent即可。
狼怎么伪装成羊呢?
狼可以用毛皮或其他材料制作成羊的外表。
披着羊皮的狼,和爬虫程序加入请求头信息(User-Agent)就是一个道理。
9. 在代码中加入请求头信息
requests库的get方法提供了headers参数。
headers:请求头。
headers参数的类型是字典。
headers参数的类型是字典。
headers参数的类型是字典。
作用是接收自定义的请求头。
【初学者可以这样构建请求头信息】
- 先构建一个字典
header = {}
header是变量名。
{}表示字典。
- 在大括号中间输入【回车】,输入
'':''字符,准备好字典的框架。
header = {
'':''
}
这里添加引号是因为这里字典的键和值都是字符串类型。
- 填充字典的键和值。
header = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) +\
AppleWebKit/537.36 (KHTML, like Gecko)+\
Chrome/108.0.5359.95 Safari/537.36 QIHU 360SE'
}
user-agent是字典的键。
后面的具体信息作为值。
因为请求头字符多,字典格式很多初学者掌握的不熟练,复制请求头信息时太容易出错了。
初学者用上面的方法可以避免出错。
然后在requests发送请求时将请求头信息及header变量作为值传递给get函数的参数headers。
r = requests.get(url,headers = header )
headers是get函数的参数,是不可以换成其他名字的。
header是存储请求头信息的变量名,名字你可以自己命名。
【测试加入请求头的user-agent】
# 1.导入库
# requests是第三方库,作用是发送发送GET、POST、PUT、DELETE等请求
import requests
# 2.要访问的url,这个是测试网址
url = "http://httpbin.org/get"
# 3. 浏览器的请求头信息
header = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) +\
AppleWebKit/537.36 (KHTML, like Gecko)+\
Chrome/108.0.5359.95 Safari/537.36 QIHU 360SE'
}
# 4.发送请求,并把响应结果赋值给变量r
r = requests.get(url, headers= header )
# 5. 输出r的文本信息
print(r.text)
【终端输出】
{
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.95 Safari/537.36 QIHU 360SE",
"X-Amzn-Trace-Id": "Root=1-648348bd-2aadd11662bf3bad3c052f78"
},
"origin": "112.113.185.64",
"url": "http://httpbin.org/get"
}
大家观察输出结果。
【添加 "User-Agent"访问网页服务器识别的 "User-Agent"是下面这样的】
“User-Agent”: “Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.95 Safari/537.36 QIHU 360SE”,
【没有 "User-Agent"访问网页服务器识别的 "User-Agent"是下面这样的】
“User-Agent”: “python-requests/2.26.0”
我们发现通过添加User-Agent我们将爬虫程序的请求头伪装成功了。
添加一个字典变量,我们成功的将狼伪装成了羊。
下面,我们以访问百度网页为例,写一个带请求头的访问网页代码。
【代码示例】
# 1.导入库
# requests是第三方库,作用是发送发送GET、POST、PUT、DELETE等请求
import requests
# 2.要访问的url
url = 'https://www.baidu.com/'
# 3. 浏览器的请求头信息
header = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) +\
AppleWebKit/537.36 (KHTML, like Gecko) +\
Chrome/108.0.5359.95 Safari/537.36 QIHU 360SE'
}
# 4.发送请求,并把响应结果赋值给变量r
r = requests.get(url, headers= header )
# 5.输出Response对象的status_code属性
print(r.status_code)
# 6. 查看r的类型
print(type(r))
【终端输出】
200
<class 'requests.models.Response'>
200表示访问网页成功。
<class 'requests.models.Response'>表示返回的r是一个requests.models类的响应对象。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐
 3
3 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)