【论文解读】Object Goal Navigation usingGoal-Oriented Semantic Exploration
SemExp探讨了目标导航问题,涉及在未知环境中导航到给定对象类别的实例。端到端的基于学习的导航方法在这项任务中面临困难,因为它们在探索和长期规划方面效果不佳。我们提出了一种模块化系统,名为“目标导向语义探索”,它构建一个情景语义地图并利用它根据目标对象类别高效地探索环境。视觉上逼真的仿真环境中的实证结果显示,所提出的模型在多个基准测试中表现优异,包括端到端学习方法以及基于模块地图的方法,并且在C
论文:https://devendrachaplot.github.io/papers/semantic-exploration.pdf
代码:https://github.com/devendrachaplot/Object-Goal-Navigation
项目: Object Goal Navigation using Goal-Oriented Semantic Exploration
example:
1 摘要:
这项研究探讨了目标导航问题,涉及在未知环境中导航到给定对象类别的实例。端到端的基于学习的导航方法在这项任务中面临困难,因为它们在探索和长期规划方面效果不佳。
我们提出了一种模块化系统,名为“目标导向语义探索”,它构建一个情景语义地图并利用它根据目标对象类别高效地探索环境。
视觉上逼真的仿真环境中的实证结果显示,所提出的模型在多个基准测试中表现优异,包括端到端学习方法以及基于模块地图的方法,并且在CVPR-2020 Habitat ObjectNav挑战赛的获胜。
消融分析表明,所提出的模型学习了场景中对象的相对排列的语义先验,并利用这些先验进行高效探索。领域无关的模块设计使我们能够将模型转移到移动机器人平台,并在现实世界中实现类似的目标导航性能。
2 引言:
图1:目标导航所需的语义技能。高效的目标导航不仅需要被动技能,如对象检测,还需要主动技能,比如构建一个情景记忆并有效地利用它来学习关于场景中对象相对排列的语义先验。

所提出的方法,被称为“目标导向语义探索”(SemExp),在Active Neural SLAM的基础上进行了两方面的改进,以解决语义导航任务。
首先,它构建类似于Active Neural SLAM的自顶向下度量地图,但添加额外的通道来明确编码语义类别。与在Active Neural SLAM中直接从第一人称图像预测自顶向下地图不同,我们使用第一人称预测,然后进行可微分几何投影。这使我们能够利用现有的预训练对象检测和语义分割模型来构建语义地图,而不是从头开始学习。
其次,我们不再使用仅基于障碍地图的最大化覆盖不可知目标的探索策略,而是训练了一个目标导向的语义探索策略,该策略学习了用于高效导航的语义先验。
这些改进使我们能够处理具有挑战性的目标导航任务。我们在视觉上逼真的仿真环境中的实验表明,SemExp在很大程度上优于先前的方法。所提出的模型还赢得了CVPR 2020 Habitat ObjectNav挑战[3]。我们还展示了SemExp在转移到移动机器人平台时实现了类似的实际性能。

所提出的模型包括两个模块,语义映射(Semantic Mapping)和目标导向语义策略(Goal-Oriented Semantic Policy)。语义映射模块随时间构建语义地图,而目标导向语义策略根据语义地图选择一个长期目标,以有效地实现给定的对象目标。基于分析规划器的确定性本地策略用于采取低层次的导航动作,以达到长期目标。
3 方法:
3.1 目标导航任务定义:
在目标导航任务中,目标是导航到给定对象类别的一个实例,如“椅子”或“床”。代理在环境中的一个随机位置初始化,并接收目标对象类别(G)作为输入。在每个时间步t,代理接收视觉观察(st)和传感器姿势读数xt,并采取导航动作at。视觉观察包括第一人称的RGB和深度图像。动作空间A包括四个动作:move_forward(前进)、turn_left(左转)、turn_right(右转)、stop(停止)。当代理认为已接近目标对象时,需要执行‘stop’动作。如果到目标对象的距离小于某个阈值ds(= 1m),当代理执行停止动作时,该回合被视为成功。回合在达到固定的最大时间步数(= 500)后终止。
3.2 概述:
我们提出了一个名为“目标导向语义探索”(SemExp)的模块化模型,用于解决目标导航任务(请参见图2概述)。它由两个可学习的模块组成,即“语义映射”和“目标导向语义策略”。语义映射模块随时间构建语义地图,而目标导向语义策略根据语义地图选择一个长期目标,以高效地实现给定的目标对象。基于分析规划器的确定性本地策略用于采取低层次的导航动作,以达到长期目标。我们首先描述我们的模型使用的语义地图表示,然后描述这两个模块。
3.3 语义地图表示:
SemExp模型内部维护着语义度量地图 mt 和代理的姿势 xt。空间地图 mt 是一个 K × M × M 的矩阵,其中 M × M 表示地图的大小,该空间地图中的每个元素对应于物理世界中的一个大小为25cm²(5cm × 5cm)的单元格。K = C + 2 是语义地图中的通道数,其中 C 是语义类别的总数。前两个通道表示障碍和已探索区域,其余的通道分别表示一个对象类别。每个通道中的每个元素表示相应位置是否是障碍物,已探索,或者包含相应类别的对象。在每一轮开始时,地图被初始化为全零,m0 = [0]^(K×M×M)。姿势 xt ∈ R^3 表示代理的x和y坐标以及在时间t的代理方向。代理始终从每一轮的开始时以东向朝向地图的中心,x0 = (M/2, M/2, 0.0)。
3.4 语义映射。
为了构建语义地图,我们需要预测视觉观察中看到的对象的语义类别和分割。最好使用现有的对象检测和语义分割模型,而不是从头开始学习。主动神经SLAM模型直接从RGB观察中预测自顶向下地图,因此没有任何机制来整合预训练的对象检测或语义分割系统。相反,我们在第一人称视图中预测语义分割,并使用可微分投影将第一人称预测转换为自顶向下地图。这使我们能够使用现有的预训练模型进行第一人称语义分割。然而,第一人称语义分割中的小错误可能导致在投影后地图中的大错误。为了克服这个限制,我们在地图空间中引入了一个损失,除了在第一人称空间中。

图3显示了语义映射模块的概述。深度观测用于计算点云。点云中的每个点都与预测的语义类别相关联。使用在RGB观察中预训练的Mask RCNN [18]来预测语义类别。然后,点云中的每个点通过可微分的几何计算在3D空间中投影,得到体素表示。然后将体素表示转换为语义地图。对于所有障碍、所有单元格和每个类别,通过对体素表示的高度维度求和,可以得到投影语义地图的不同通道。然后,将投影的语义地图通过去噪神经网络,得到最终的语义地图预测。
地图在时间上通过空间变换和通道池化进行聚合,详细描述可参考Active Neural SLAM。语义映射模块使用交叉熵损失进行监督学习,同时考虑语义分割和语义地图预测。几何投影采用可微操作实现,以便如果需要,损失可以通过整个模块进行反向传播。
3.5 目标导向语义策略
目标导向语义策略根据当前的语义地图决定一个长期目标,以达到给定的目标对象(G)。如果与类别G对应的通道具有非零元素,表示观察到目标对象,它会简单地将所有非零元素选择为长期目标。如果没有观察到目标对象,则目标导向语义策略需要选择一个最有可能发现目标类别对象的长期目标。这需要学习对象和区域相对排列的语义先验。我们使用一个神经网络来学习这些语义先验。它以语义地图、代理的当前和过去位置以及目标对象为输入,并在自顶向下地图空间中预测一个长期目标。目标导向语义策略使用强化学习进行训练,以目标对象的最近距离减小为奖励。我们在一个粗略的时间尺度上对长期目标进行采样,每u = 25步一次,类似于[10]中的目标不可知的全局策略。这将强化学习中的探索时间视角指数级减小,从而减少样本复杂性。
3.6 确定性本地策略
本地策略使用快速行进方法[41]基于语义地图的障碍通道来规划从当前位置到长期目标的路径。它简单地沿着路径采取确定性动作以达到长期目标。与Active Neural SLAM中的训练本地策略相比,我们使用确定性本地策略,因为在我们的实验中它们表现相似。请注意,尽管上述语义策略在粗略的时间尺度上操作,但本地策略在细粒度的时间尺度上操作。在每个时间步中,我们更新地图并重新规划到长期目标的路径。
4 实验

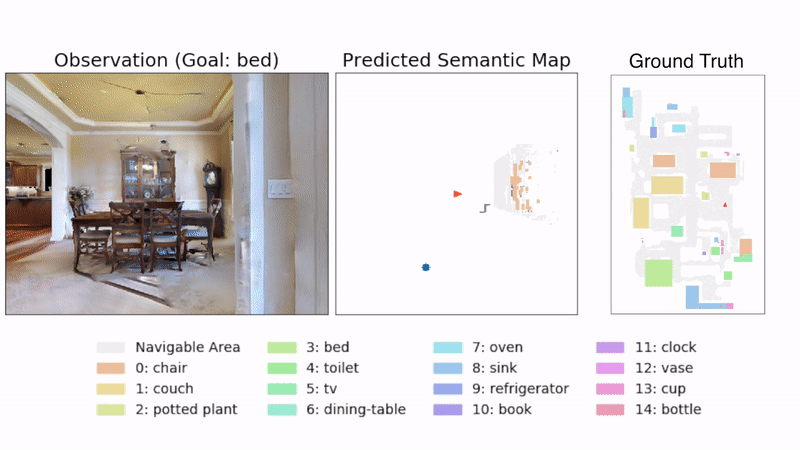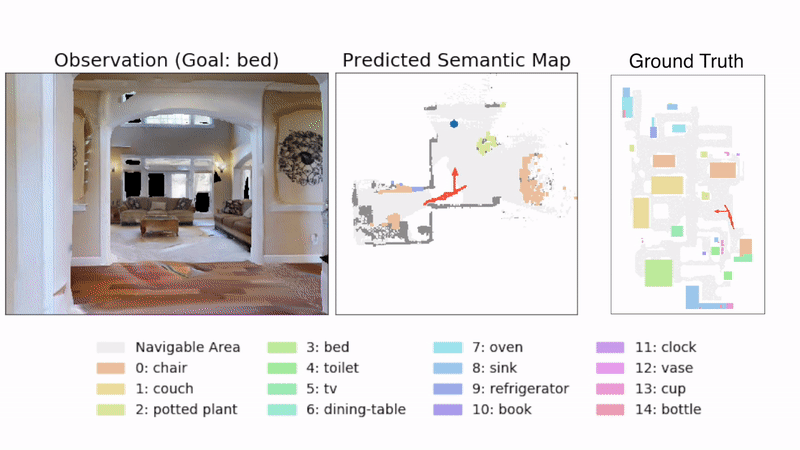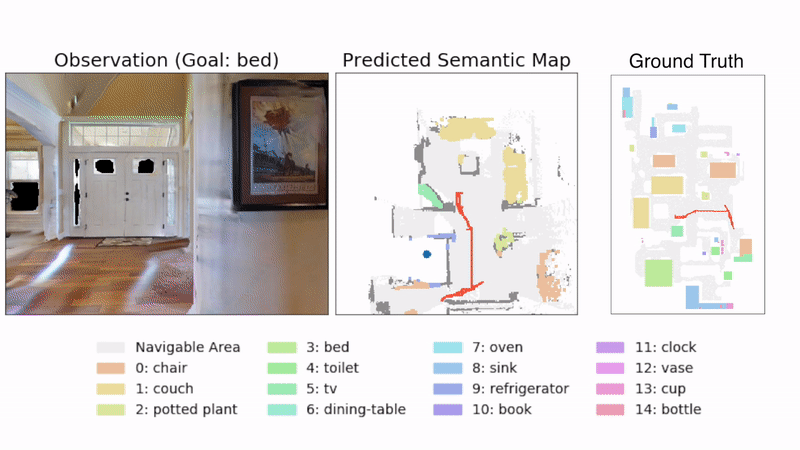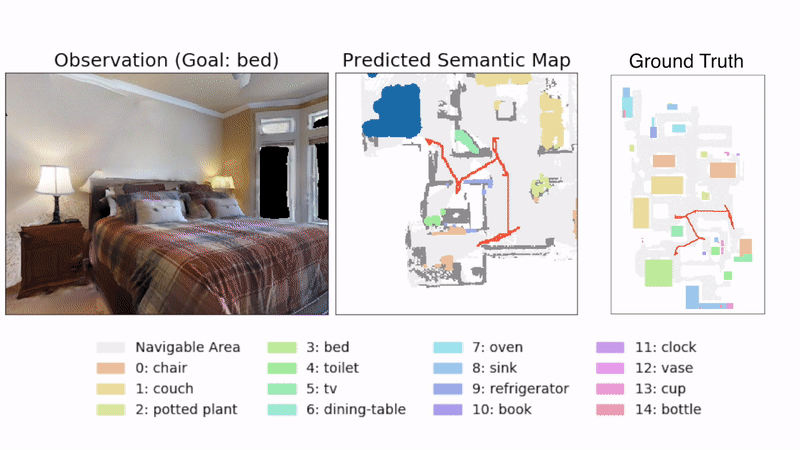
图4:示例轨迹。图中显示了SemExp模型在Gibson测试集的场景中的示例轨迹。在顶部显示了代理所看到的示例图像,下方显示了预测的语义地图。目标对象是'bed'。由目标导向语义策略选择的长期目标显示为蓝色。右侧显示了带有代理轨迹的地面真实地图(对代理不可见)供参考。
结果:
我们对所有基线和提出的模型进行了1000万帧的训练,并分别在Gibson和MP3D测试集中进行评估。我们对每个场景运行了200个评估回合,Gibson总共有1000个回合(5个场景),MP3D总共有2000个回合(10个场景,其中1个场景不包含6个可能类别的任何对象)。
图4使用提出的SemExp显示了一个示例轨迹,展示了代理的观察和预测的语义地图。定量结果显示在表1中。SemExp在两个数据集上一致优于所有基线(在Gibson/MP3D上实现了54.4%/36.0%的成功率,而Active Neural SLAM基线为44.6%/32.1%)。绝对数字在Gibson数据集上较高,因为场景相对较小。表1中Random的成功阈值表示数据集的难度。有趣的是,将传统的探索与预训练的对象检测器相结合的基线优于端到端的强化学习基线。我们观察到基于强化学习的基线的训练性能要高得多,表明它们在训练场景中记忆了对象的位置和外观,并且泛化能力差。SemExp相对于Active Neural SLAM基线的性能提升显示了在探索中整合语义和目标对象的重要性。
5 结论
在本文中,我们提出了一个在大型真实环境中解决目标导航任务的语义感知探索模型。所提出的模型相对于先前的方法有两个主要改进,即在显式的记忆中整合语义和学习目标导向的语义探索策略。我们的方法在目标导航任务上实现了最先进的性能,并赢得了CVPR2020 Habitat ObjectNav挑战赛。消融研究表明所提出的模型学习了导致更高效目标驱动导航的语义先验。领域无关的模块设计使我们的模型成功地转移到了真实世界。我们还分析了模型的错误模式,并在未来的工作中定量衡量了两个重要维度(语义映射和目标导向探索)的改进空间。所提出的模型还可以通过利用情节地图来更有效地导航后续目标,从而扩展到解决一系列目标导航任务。

开放原子开发者工作坊旨在鼓励更多人参与开源活动,与志同道合的开发者们相互交流开发经验、分享开发心得、获取前沿技术趋势。工作坊有多种形式的开发者活动,如meetup、训练营等,主打技术交流,干货满满,真诚地邀请各位开发者共同参与!
更多推荐


 37
37 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)